I have problem with Hebrew encoding in npp. Encoding Hebreww 1225 displays Greec leters instaed Hebrew.
-
I have a problem with Hebrew encoding in NPP.
Encoding Hebrew Windows - 1225 results in displaying Greece letters instead of the Hebrew one.
All other encodings result in gibberish or “???”
The same program works fine on IntelliJ IDEA. -
You said Windows-1225, but I couldn’t find that in Notepad++ or in Wikipedia. Both do show Windows-1255, so I am assuming that was just a typo on your part.
I did a File > New, then picked Encoding > Character Sets > Hebrew > Windows-1255. I used Edit > Character Panel to insert the characters from codepoints E0 thru FA:
אבגדהוזחטיךכלםמןנסעףפץצקרשת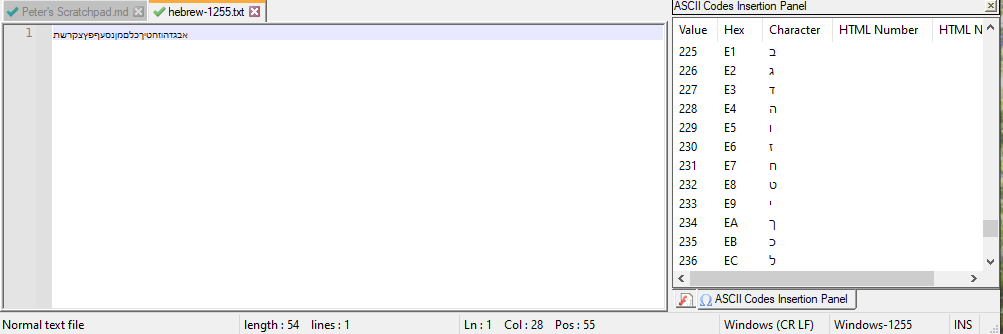
I then closed the file, exited and reloaded Notepad++. If my Settings > Preferences > MISC has ☐ Autodetect character encoding disabled (my normal condition), if I re-open the file, it assumes standard “ANSI”, so displays accented characters:

You’ll notice that in my experiments, it didn’t pick Greek characters; it picked the Latin accented characters
If I close, exit, and reload, and change settings to enable ☑ Autodetect character encoding, then when I load the file, it detects it as ISO 8859-8, which is the ISO-standard Hebrews encoding (and has the same characters at those 27 codepoints… but is compatible enough for this example data.
I am sure you have a reason for using Win-1255. But in my experience, defaulting all text files to a Unicode representation, such as UTF-8 or UTF-8-BOM, is much more reliable. All those Win-#### encodings, and the OEM-### predecessors, were the old 1980’s and early 1990’s way of doing things; Unicode has been the right way to handle characters since the 1990’s, and has been growing in support over the past 2.5 decades, such that modern equipment nearly 100% supports the majority of Unicode.
If you must have Win-1255, I would suggest storing the “official” file in UTF-8-BOM; then, only when you need to export to whatever system requires the Win-1255 should you change the encoding and save to the export file (under a different name).
The reason I suggest that is because with the 256-character pure 8-bit character sets, it is impossible for Notepad++ or any other application to guess the right encoding character set 100% of the time – such apps often use heuristic algorithms to study the byte sequences, and try to determine which character set is most likely, given the bytes used; but since most of the true-8-bit sets have frequently-used characters in E0-FA, it’s not possible to always be right. Whereas if you use an encoding like UTF-8, there is an encoding scheme for all the Unicode characters to be unambiguously stored; and if you use UTF-8-BOM, Notepad++ will not guess wrong that it’s some other encoding (because the BOM as the first bytes in the file are an unambiguous indicator to Notepad++ and other editors).
When the Windows filesystems were designed (either the original DOS filesystem or the “newer” NTFS filesystem for Windows NT from the early 90s), they didn’t choose to store metadata like encoding settings; this means that applications that handle files from that era (or systems that foolishly never updated to also handle the longtime Unicode standards) cannot know for sure what the encoding is, and you sometimes have to use heuristics or application settings or manual input to determine the right encoding. And that’s not Notepad++'s fault.
But if you cannot use UTF-8 for your file or for your “main/master” file, and must always use Win-1255 for whatever reason (ie, exporting to Win-1255 isn’t sufficient), then you are going to have to live with Notepad++ sometimes selecting the wrong encoding. In such a circumstance, I would recommend that you figure out whether autodetect enabled or disabled works better for you (different users have different results on that toggle); that you set Settings > Preferences > New Document > Encoding to the pulldown with
Win-1255selected; and that you use Settings > Shortcut Mapper > Main Menu, set Filter =Win, and add a keyboard shortcut forWindows-1255, so that you can have a quick keystroke to tell Notepad++ that the current encoding is Windows-1255. -
Hallo Mr. Jones,
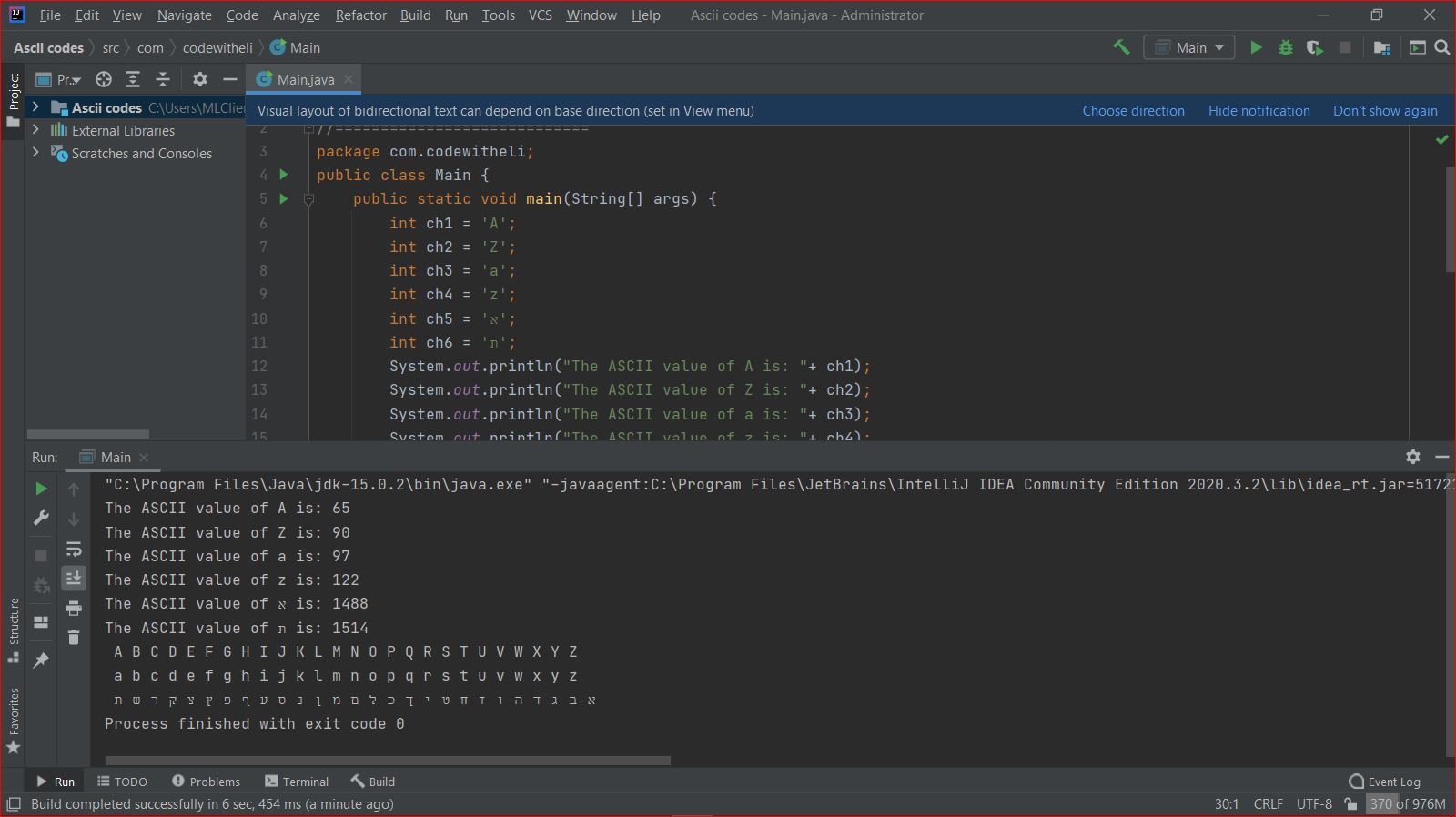
The here attached images are of a Java program and the output obtained with IntelliJ IDEA.
All my affords to obtain the same output with Notepad++ failed.
Please let me know if you did find the solution.
Much obliged:
Jaacov Molcho. (ymolcho12@yahoo.com)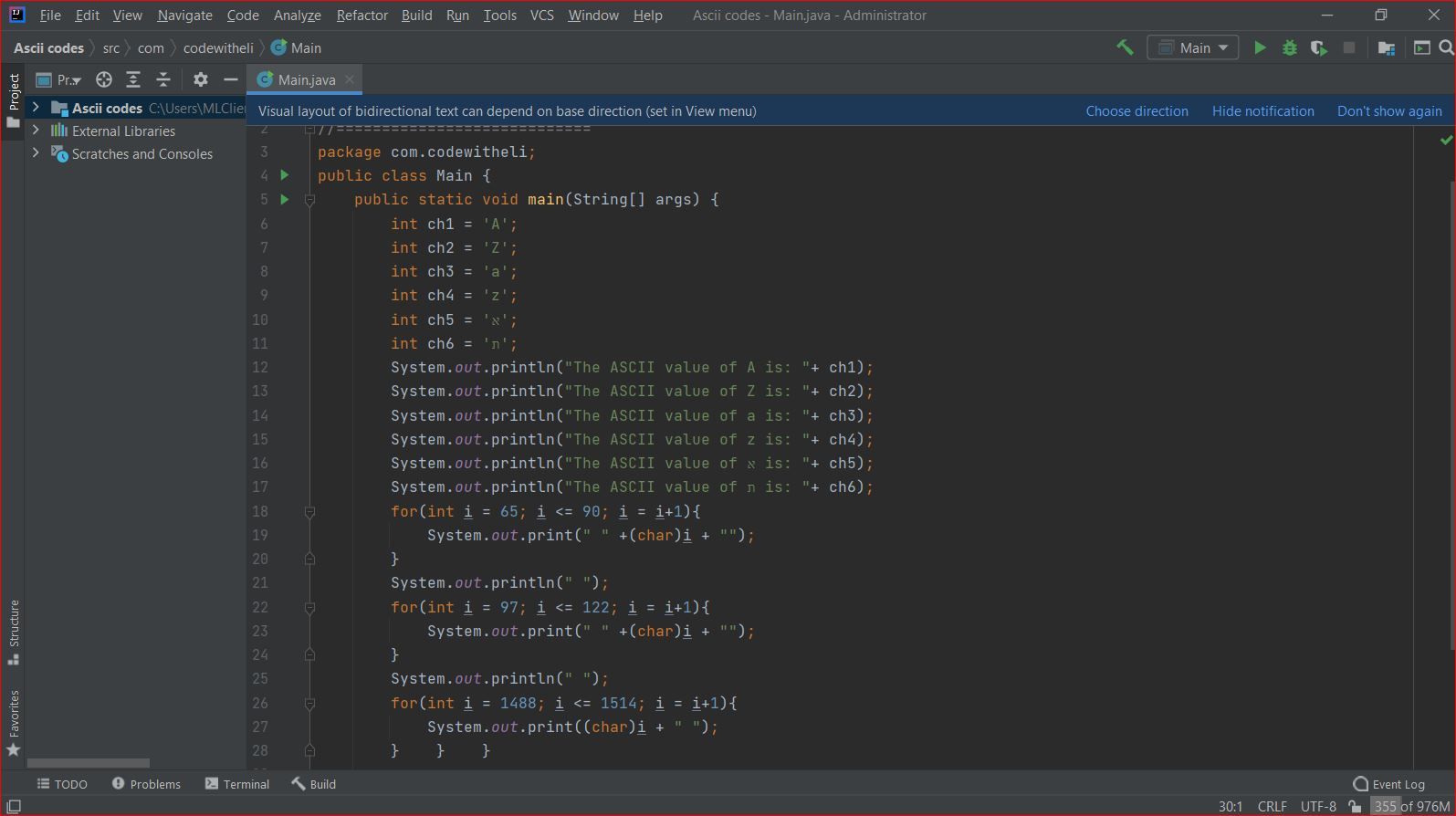
-
- This is not a Java help forum. But your output text is lying:
The ASCII value of א is: 1488is factually incorrect. There is no ASCII codepoint for א, or anything other than the standard first 128 characters with the standard US English alphabet, numbers, punctuation, and control characters – anything that claims “the ASCII (codepoint) is greater than 127” is wrong. What you are showing in your Java is the Unicode codepoint of א, which is 1488, akaU+05D0. - If you are programming in Java, there is no reason to be using encoding Windows-1255. Use a real Unicode encoding, like UTF-8, like you are in IntelliJ IDEA.
- If what you are really complaining about is that running the program from Notepad++ , and that you aren’t seeing the characters you think you should, are you sure that your output console is really set the way you think it is? Because while IntelliJ IDEA might properly set the encoding of its output window to utf8, maybe what you are using with Notepad++ for output (whether it is NppExec’s console, or a spawned cmd.exe window from Run > Run menu, or whatever) might not have the encoding set the way you think (chcp,
npe_console o2 i2, …)
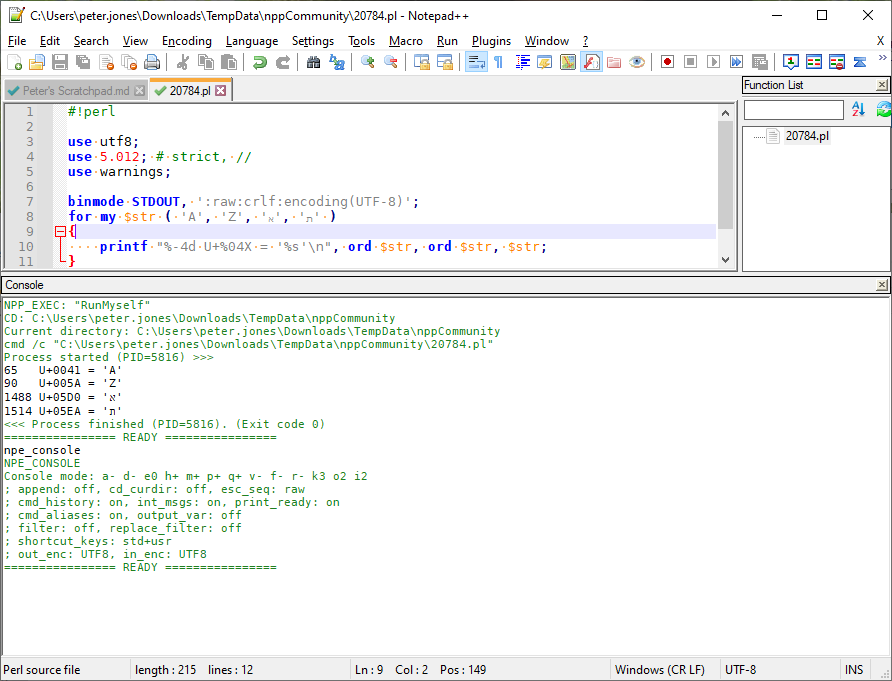
As you can see, with my perl code set for UTF-8, outputting to the NppExec with the console settings set for UTF8 output encoding, everything is as I expect:
- This is not a Java help forum. But your output text is lying:
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login