Match < and > and what's between it
-
Hi, glossar and All,
Your regex cannot work because it searches the shortest range of standard chars between a
<char and the string>>!So, I suppose that the following regex S/R should do the trick, without the need of any group :
SEARCH
<.+?>REPLACE
[c darkslategray][b]$0[/b][/c][/m]So, from the text :
[m2][b]1.[/b]<jemand rechnet mit etwas[i]([c darkred]Dat.[/c])[/i]>[/m]we get :
[m2][b]1.[/b][c darkslategray][b]<jemand rechnet mit etwas[i]([c darkred]Dat.[/c])[/i]>[/b][/c][/m][/m]
Now, I was intrigued by the two successive
[/m]at the end of the replacement !If I try to identify the starting tags and the appropriate ending tags, in the resulting replacement string, it gives :
[m2][b]1.[/b][c darkslategray][b]<jemand rechnet mit etwas[i]([c darkred]Dat.[/c])[/i]>[/b][/c][/m][/m] | | | | | | | | | | | | | | | | | | •---------------• | | | | | | | | | •------------------------• | | | | | | | •---------------------------------------------------------• | | | •-----• •------------------------------------------------------------------------------• | •-----------------------------------------------------------------------------------------------•Obviously, the last
[/m]is orphan and should not occur !So, I think that the right S/R is, rather :
SEARCH
<.+?>REPLACE
[c darkslategray][b]$0[/b][/c]Note that, in replacement, the
$0syntax represents the overall match, i.e. the<..........>area !Best Regards,
guy038
-
@glossar said in Match < and > and what's between it:
[m2][b]1.[/b]<jemand rechnet mit etwas[i]([c darkred]Dat.[/c])[/i]>[/m]
So in general, I’m confused as to why OP would think that
<.*?>>would match this:[m2][b]1.[/b]<jemand rechnet mit etwas[i]([c darkred]Dat.[/c])[/i]>[/m]…at all, because there is no occurrence of
>>in the data!?This would be a really basic error, one that I’d think someone could figure out before creating a posting here.
-
@guy038
Thank you for the effort, I appreciate it!
You were a bit late with your help :P, so I went with poor-man’s-way in the end: replaced < with # and > with ~ :)) and put them later back. I’m glad it worked. :)While we are on it, what’s difference between an “+” and “asterisk” in the context of <.*|+?>? And also difference between “$1” and “$0”? I know all regex rules and co. are all there, but maybe you would shortly and simply put it?
Anyway, thank you again.
My bad! An \ was supposed to be before “>>” - at least that’s how it stays in my notes: “<.*?>> : Match < and > and what’s between it”
-
@glossar said in Match < and > and what's between it:
My bad! An \ was supposed to be before “>>” - at least that’s how it stays in my notes: “<.*?>> : Match < and > and what’s between it”
No problem, but you see the problem yet?: You’re not using “black boxes” here to express your regex and thus this site is consuming some of your characters, so it is hard for anyone reading to know what you really mean. As you’re composing a post here, type your critical data, then select it, then use the
</>button in the “toolbar”. Then it will dothisto your text, and it (mostly) will leave it alone.
-
Just noticed that the \ before >> won’t show here.
-
Ah, okay, indeed I did and do need that </> trick! Thanks.
-
You can also do it like this when composing (blown up and captured as an image):

which will still prevent the site from stealing your intent, but will show it in a less-harsh manner:
test -
Hello @glossar,
You said :
what’s difference between an “+” and “asterisk” in the context of <.*|+?>? And also difference between “$1” and “$0”? I know all regex rules and co. are all there, but maybe you would shortly and simply put it?
Look at this text :
So, < this is a test > which continues with <this other part>, so TWO CONSECUTIVE '<.........>' areas in a SAME line Regex (?-s)<.+?> |................| |...............| |.........| ( +? is a LAZY quantifier ) Regex (?-s)<.+> |........................................................................................| ( + is a GREEDY quantifier )As you can see :
-
The regex
(?-s)<.+?>matches the shortest range of standard characters, all different from>, till a first>char -
The regex
(?-s)<.+>matches the greatest range of standard characters, till the last>char of current line
Now, to surround any individual
<.......>area with, let’s say,#-and-#, you have two possibilities :-
Just use the
$0syntax, in replacement, representing the overall match-
SEARCH
(?-s)<.+?> -
REPLACE
#-$0-#
-
-
Defines a group with parentheses, whose contents are rewritten as
\1,$1or${1}, in the replacement regex :-
SEARCH
(?-s)(<.+?>) -
REPLACE
#-\1-#OR#-$1-#OR#-${1}-#
-
Now, note that you could have found all this information, on NET, in tutorials on regular expressions ! For instance, with the
regular-expressions.infosite :-
https://www.regular-expressions.info/repeat.html ( Greediness vs Laziness )
-
https://www.regular-expressions.info/refreplacebackref.html Choose
Boostin the first drop-down list ( $0 vs $1 )
and so on … ! Thus, I’m not going to “
re-invent the wheel”, in each reply !So, I advice you to read this FAQ and, then, please, RTFM ;-)) Just note that this abbreviation can also be used in the plural !
Best Regards
guy038
BTW, @glossar, did my assumption, about an excess
[/m]ending tag, was exact ? -
-
@guy038 said in Match < and > and what's between it:
https://www.regular-expressions.info/refreplacebackref.html Choose Boost in the first drop-down list ( $0 vs $1 )
Nice reference. We should direct questioners here with some “regularity”!
It took me a moment to realize what the second dropdown is for!
It appears to be so you can compare two things! Am I right about it?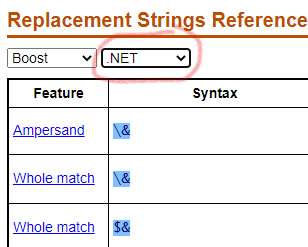
-
Hi, @alan-kilborn and All,
Yes, these two drop-down lists help us to compare if a specific functionality is supported or not, between two regex engine flavours, as well as some specificities for each one !
Note that my last sentence, between parentheses
( $0 vs $1 )is not connected at all, with these two drop-down lists, but, simply, refers to subjects asked by @glossar !BR
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login