Regex: Select/Delete html <div> tags between comments
-
hello. I want to select/delete all <div> tags between
<!-- START -->and<!-- FINAL --><!-- START --> <div class="search"> <div align="right"> <a href="link-1.html"><img src="index_files/flag_lang.jpg" title="link" alt="link" width="28" height="19" /></a> <a href="link-2.html"><img src="index_files/flag_lang_fr.jpg" title="fr" alt="fr" width="28" height="19" /></a> <a href="link-3.html"><img src="index_files/flag_lang_en.jpg" title="en" alt="en" width="28" height="19" /></a> <a href="link-4.html"><img src="index_files/flag_lang_es.jpg" title="es" alt="es" width="28" height="19" /></a> <a href="link-5.html"><img src="index_files/flag_lang_pt.jpg" title="pt" alt="pt" width="28" height="19" /> </div> </div> <!-- FINAL -->THE OUTPUT SHOULD BE:
<!-- START --> <a href="link-1.html"><img src="index_files/flag_lang.jpg" title="link" alt="link" width="28" height="19" /></a> <a href="link-2.html"><img src="index_files/flag_lang_fr.jpg" title="fr" alt="fr" width="28" height="19" /></a> <a href="link-3.html"><img src="index_files/flag_lang_en.jpg" title="en" alt="en" width="28" height="19" /></a> <a href="link-4.html"><img src="index_files/flag_lang_es.jpg" title="es" alt="es" width="28" height="19" /></a> <a href="link-5.html"><img src="index_files/flag_lang_pt.jpg" title="pt" alt="pt" width="28" height="19" /> <!-- FINAL -->I made a regex, but it is not very good, and maybe too long:
FIND:
(<\!-- START -->)(.*?)(<div)[\s\S]*?(<a href)|(height="19" />)[\s\S](*?)(</div>)[\s\S](*?)(</div>)(<\!-- FINAL -->)Replace by:
/1/2/5/6/7Can anyone help me?
-
This is a great application for the general technique shown HERE.
Why don’t you try applying it for your case?
If you have trouble, come back here and post the regex you’ve derived based upon the technique and you’ll probably get help.
OTHERS: Please don’t respond in ways unrelated to the general technique (unless/until it is shown to fail for the OP’s case).
Doing so just helps this site devolve from good discussions about Notepad++ into a regular expression writing service.
[If you feel the need to solve it for your personal “mental gymnastics” purposes, why not just do it for yourself and feel the satisfaction without showing-off by posting it?] -
@Robin-Cruise said in Regex: Select/Delete html <div> tags between comments:
Replace by: /1/2/5/6/7
BTW, someone that has asked regular expression questions before should have somewhere along the line gained the knowledge that such a replace expression is utterly wrong.
-
@Alan-Kilborn said in Regex: Select/Delete html <div> tags between comments:
This is a great application for the general technique shown HERE.
sorry, but I do not understand nothing on that post, related with mine…
-
@Robin-Cruise said in Regex: Select/Delete html <div> tags between comments:
sorry, but I do not understand nothing on that post, related with mine…
Hmmm, well, I used that post’s information, with your data, to see that it will work for your problem, at least as far as you’ve stated it.
I suppose that someone will come along and spoon-feed you.
-
I don’t know if it works with one regex, but it works with two
FIND:
(<\!-- START -->)(.*?)[\s\S]*?(<a href)REPLACE BY:
\1\r\r\3AND THEN:
FIND:
(height="19" />\s)[\s\S]*?(<\!-- FINAL -->)Replace by:
\1\r\2 -
@Robin-Cruise said in Regex: Select/Delete html <div> tags between comments:
sorry, but I do not understand nothing on that post, related with mine…
The post he linked shows a generic regular expression that searches for specific text, to be replaced with specific text, in between a start and end expression (so “replace text FR with text RR, but only when it’s between BSR and ESR”) – that sounds exactly like your question, where FR would be your
<div>, RR would be empty (because you want to delete it), and BSR and ESR are defined by the START and FINAL comment syntax you showed.I don’t know if it works with one regex, but it works with two
Congratulations. You may have just learned the most important rule of regular expressions: you don’t have to do it the fancy way. If a two-step process works for you, and you understand the two steps, then use the process you do understand.
If you want to experiment with other methods, or learn how to do it one step, you will just have to practice, and try, and learn from your mistakes. That’s how all of us got to the point we are with regular expressions.
-
@PeterJones yes, sir. Thank you.
Anyway, I can learn another solutions, but on my examples, not others. If it is so easy to you, can you please update the solution on your other link to my problem?
I want to see the difference.
-
@Robin-Cruise said in Regex: Select/Delete html <div> tags between comments:
can you please update the solution on your other link to my problem?
Nope, sorry. You have a working solution. Optimizing beyond that is not the focus of this community forum.
If you want to learn more about regular expressions, you can only do that by experimenting on your own, reading the documentation you have been pointed to multiple times, trying out regular expressions that you see elsewhere and figuring out what they do. No matter how much we spoon feed you solutions to specific questions, you won’t understand regular expressions until you actually experiment yourself, and see for yourself what each piece does. I cannot help you any more than that.
-
@PeterJones Please remember this:
A man who knows and does not show what he knows is not a man who possesses science in the true sense of the word.
-
@Robin-Cruise said in Regex: Select/Delete html <div> tags between comments:
@PeterJones Please remember this:
A man who knows and does not show what he knows is not a man who possesses science in the true sense of the word.
Wow, how philosophical.
I am here to help people, not just give them the answers they demand. There is a difference. I like teaching how to fish, not just giving the person a fish. But since you don’t like the way I try to help people learn – which is fine – then I will stop trying to help you learn after this post, because I don’t feel that arguing with you is a good use of my time.
I will now try to be excruciatingly explicit in what I was trying to move you toward:
- Since my phrasing of “where FR would be your
<div>” apparently wasn’t obvious, I will add a slight explanation, then make the definition explicit: Realizing that your<div>s have attributes, that would be represented in regular expression syntax as<div[^>]*>. This means that you will need to apply the mental algebra of FR =<div[^>]*>- but thinking about it more, and looking at your example, you also implied that you wanted to remove
</div>as well as the start of the div. It would have been nice if you’d been explicit; it seems counter-productive to demand of us that we fill in all the details, but you get to leave out important details like that. Anyway, to allow it to remove both the beginning and the end, we want to say there’s an optional/before the div. Translating to regex syntax, that would be:</?div[^>]*>
- but thinking about it more, and looking at your example, you also implied that you wanted to remove
- Since my wording of “BSR and ESR are defined by the START and FINAL comment syntax you showed” wasn’t clear to you, I will make it more explicit:
- BSR =
<!-- START --> - ESR =
<!-- FINAL -->
- BSR =
- I hope you understood that when I said “RR would be empty”, that meant that the RR term would not have any text.
@guy038 said,
SEARCH
(?-i:BSR|(?!\A)\G)(?s:(?!ESR).)*?\K(?-i:FR)
REPLACE RRSo now, we take the definitions above, and plug them in. I will show you one step at a time.
(?-i:BSR|(?!\A)\G)(?s:(?!ESR).)*?\K(?-i:FR)I insert the expression defined above for BSR, and get:
(?-i:<!-- START -->|(?!\A)\G)(?s:(?!ESR).)*?\K(?-i:FR)Then I insert the expression for ESR:
(?-i:<!-- START -->|(?!\A)\G)(?s:(?!<!-- FINAL -->).)*?\K(?-i:FR)Then I insert the expression for FR:
(?-i:<!-- START -->|(?!\A)\G)(?s:(?!<!-- FINAL -->).)*?\K(?-i:</?div[^>]*>)So when we tried to tell you what values when in BSR, ESR, and FR, that was what I was saying: insert those three expressions into the placeholder spots in Guy’s generic regular expression.
Then for the replacement, he said,
**RR**I said the RR will be empty. So that means that the replacement box needs to be empty.
And, in case you’ve forgotten, the search mode needs to be set as Regular expression.
Here is a screenshot of the dialog filled out, but I haven’t done any replacements yet:
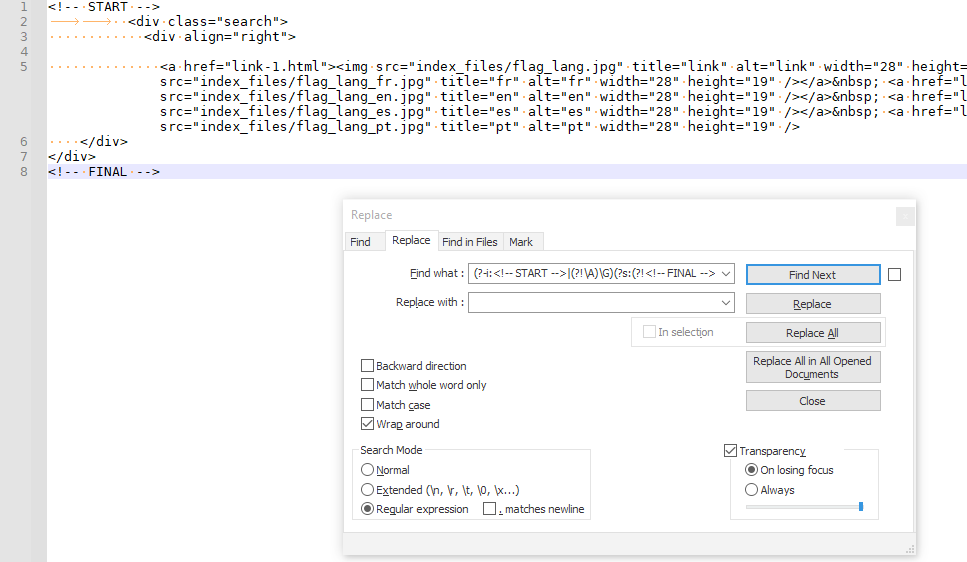
And here is a screenshot after I hit REPLACE ALL, so you can see the number of replacements that it does:
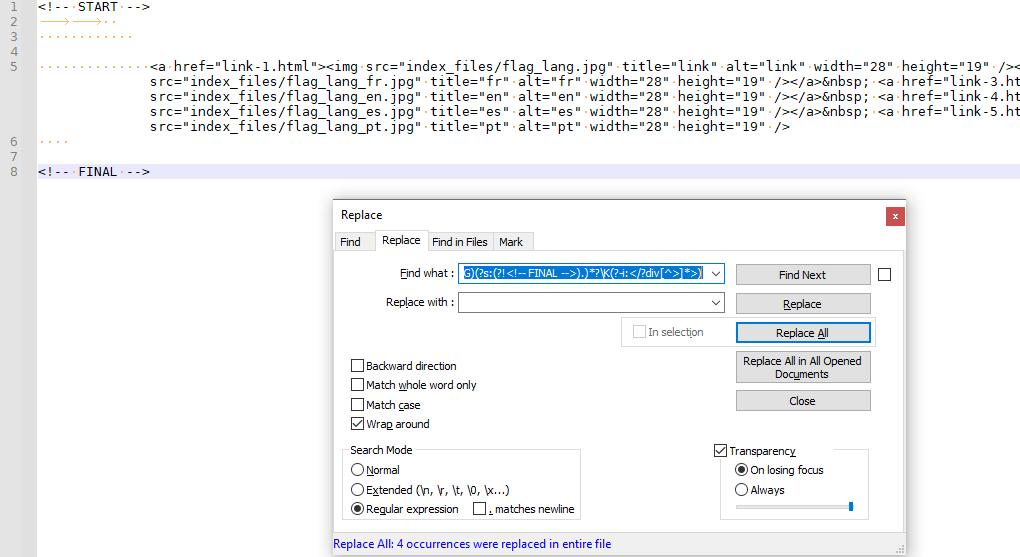
So now you have seen in gory detail how to go about taking your defined start, end, search, and replace values, and how to plug them into Guy’s generic regular expression. It’s a simple sequential process.
I am truly sorry that you didn’t get the mental benefit of figuring out how to do those steps yourself, because that would have helped you much more than just handing you the answer. Hopefully, with my descriptions, it will still help you learn more about regex. (Given that you don’t like the way I help people learn, I am doubtful that it will help you; but I don’t know how else to help you learn.)
And one last time, just in case it will sink in this time: the only way you are going to learn regex is by trying it yourself, rather than demanding that others spoon-feed you the answer. Good luck, and good bye.
- Since my phrasing of “where FR would be your
-
I think the OP may have to work harder to pull out his answer from your post, than he would have had to to just follow the generic solution I pointed to initially. :-)
-
This post is deleted! -
Hi, @Robin-cruise, @peterjones, @alan-kilborn and **All,
A few clarifications : in order to use the generic regex, described before :
-
You must use the N++ release
v7.9.1or a later release, which correctly handles the\Aassertion ! -
Depending of the
Search,ReplaceorMarkoperation needed, here are, in the table below :-
The location of the caret, before running this generic S/R
-
The status of the
Wrap aroundoption
-
•---------------------------------------•-----------------------------------------•------------------------• | Action | Location of CARET, BEFORE S/R | "Wrap around" option | •---------------------------------------•-----------------------------------------•------------------------• | | | | | Find Next | At VERY BEGINNING of CURRENT file | N/A | | | | | | Count | N/A | TICKED | | | | | | Find All in Current Document | N/A | N/A | | | | | | Find All in All Opened Documents | N/A | N/A | | | | | •---------------------------------------•-----------------------------------------•------------------------• | | | | | Replace | At VERY BEGINNING of CURRENT file | N/A | | | | | | Replace All | N/A | TICKED | | | | | | Replace All in All Opened Documents | N/A | N/A | | | | | •---------------------------------------•-----------------------------------------•------------------------• | | | | | Find All | N/A | XXXX | | | | | | Replace in Files | N/A | XXXX | | | | | •---------------------------------------•-----------------------------------------•------------------------• | | | | | Mark All | N/A | TICKED | | | | | •---------------------------------------•-----------------------------------------•------------------------•This means that, globally, you can always move the caret at the very beginning of current file and tick the
Wrap aroundoption, when available, whatever the type of operation needed, in order to use that generic regex ;-))
Now, to get close to @robin-cruise’s problem, which prefers to entirely deletes the
<div........>and</div>lines, these slightly modified regexes should work better !(?-i:<!-- START -->|(?!\A)\G)(?s:(?!<!-- FINAL -->).)*?\K(?si:\h*</?div[^>]*>\R)OR
(?-i:<!-- START -->|(?!\A)\G)(?s:(?!<!-- FINAL -->).)*?\K(?si:\h*</?div.*?>\R)
For instance, from this initial text :
<div class="search"> <div align="right"> </div> </div> <!-- START --> <div class="search"> <div align="right"> <a href="link-1.html"><img src="index_files/flag_lang.jpg" title="link" alt="link" width="28" height="19" /></a> <a href="link-2.html"><img src="index_files/flag_lang_fr.jpg" title="fr" alt="fr" width="28" height="19" /></a> <a href="link-3.html"><img src="index_files/flag_lang_en.jpg" title="en" alt="en" width="28" height="19" /></a> <a href="link-4.html"><img src="index_files/flag_lang_es.jpg" title="es" alt="es" width="28" height="19" /></a> <a href="link-5.html"><img src="index_files/flag_lang_pt.jpg" title="pt" alt="pt" width="28" height="19" /> </div> </div> <!-- FINAL --> <div class="search"> <div align="right"> </div> </div> <!-- START --> <div class="search"> <div align="right"> <a href="link-1.html"><img src="index_files/flag_lang.jpg" title="link" alt="link" width="28" height="19" /></a> <a href="link-2.html"><img src="index_files/flag_lang_fr.jpg" title="fr" alt="fr" width="28" height="19" /></a> <a href="link-3.html"><img src="index_files/flag_lang_en.jpg" title="en" alt="en" width="28" height="19" /></a> <a href="link-4.html"><img src="index_files/flag_lang_es.jpg" title="es" alt="es" width="28" height="19" /></a> <a href="link-5.html"><img src="index_files/flag_lang_pt.jpg" title="pt" alt="pt" width="28" height="19" /> </div> </div> <!-- FINAL --> <div class="search"> <div align="right"> </div> </div>
we would get this output text :
<div class="search"> <div align="right"> </div> </div> <!-- START --> <a href="link-1.html"><img src="index_files/flag_lang.jpg" title="link" alt="link" width="28" height="19" /></a> <a href="link-2.html"><img src="index_files/flag_lang_fr.jpg" title="fr" alt="fr" width="28" height="19" /></a> <a href="link-3.html"><img src="index_files/flag_lang_en.jpg" title="en" alt="en" width="28" height="19" /></a> <a href="link-4.html"><img src="index_files/flag_lang_es.jpg" title="es" alt="es" width="28" height="19" /></a> <a href="link-5.html"><img src="index_files/flag_lang_pt.jpg" title="pt" alt="pt" width="28" height="19" /> <!-- FINAL --> <div class="search"> <div align="right"> </div> </div> <!-- START --> <a href="link-1.html"><img src="index_files/flag_lang.jpg" title="link" alt="link" width="28" height="19" /></a> <a href="link-2.html"><img src="index_files/flag_lang_fr.jpg" title="fr" alt="fr" width="28" height="19" /></a> <a href="link-3.html"><img src="index_files/flag_lang_en.jpg" title="en" alt="en" width="28" height="19" /></a> <a href="link-4.html"><img src="index_files/flag_lang_es.jpg" title="es" alt="es" width="28" height="19" /></a> <a href="link-5.html"><img src="index_files/flag_lang_pt.jpg" title="pt" alt="pt" width="28" height="19" /> <!-- FINAL --> <div class="search"> <div align="right"> </div> </div>
Which, as expected, do not contain any
<div........>or</div>lines, located inside the<!-- START -->........<!-- FINAL -->blocks !Best Regards,
guy038
-
-
@guy038 , @PeterJones and @Alan-Kilborn
Thank you. Now, it was much easy for me to understand the structure of a the new way of using regex.
I hope that all those who will access this page in the future will take a step forward towards progress in the way of how regex works.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login