Identical strings in column
-
Hello,
Is possible to find all identical strings in one COLUMN and mark the rows where these strings are located (highlight and mark them)?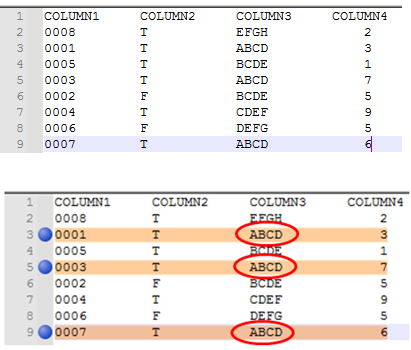
-
Possible, yes. But the answer will confuse you, and you have to be willing to learn regular expression syntax.
There have been examples of other “column based duplicate matching” recently – one of those solutions might apply, but I’m not immediately finding the discussion (my search terms might not match the phrasing in the previous topic) – maybe one of the people who helped with that will be able to chime in.
Before we put any work into it, could you please clarify what should be done in this circumstance:
0008 T EFGH 1 0001 T ABCD 2 0005 T EFGH 3 0003 T ABCD 4 0002 T EFGH 5 0006 F ZYXW 6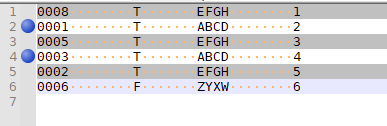
There are two groups: “EFGH” is on three rows, and “ABCD” is on two. Do you want all five of those bookmarked? Or just the three “EFGH”? Or just the two “ABCD”? If a subset of the 5, how are we supposed to know which? If it’s just a subset, then can we just hardcode the search string, and look for the solution to “mark duplicates of
ABCDin that column3 group of character columns”? Or is it just the first sequence in column3 that has duplicates below? Or something else?Further, are we allowed to sort? Because if it could be sorted by column 3, and then maybe later re-sort back to the original order, it might be easier.
The advice below might help you ask your question better / clarify your needs. (The phrasing below is focused on the search/replace, but search-and-mark requires the same information.)
-—
Do you want regex search/replace help? Then please be patient and polite, show some effort, and be willing to learn; answer questions and requests for clarification that are made of you. All example text should be marked as literal text using the
</>toolbar button or manual Markdown syntax. To makeregex in red(and so they keep their special characters like *), use backticks, like`^.*?blah.*?\z`. Screenshots can be pasted from the clipboard to your post usingCtrl+Vto show graphical items, but any text should be included as literal text in your post so we can easily copy/paste your data. Show the data you have and the text you want to get from that data; include examples of things that should match and be transformed, and things that don’t match and should be left alone; show edge cases and make sure you examples are as varied as your real data. Show the regex you already tried, and why you thought it should work; tell us what’s wrong with what you do get. Read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. If you follow these guidelines, you’re much more likely to get helpful replies that solve your problem in the shortest number of tries. -
I will try to describe it more precisely
I should from generated file remove all lines with duplicated (multiplicated) matching in COLUMN3 . Duplicated lines have to be deleted manually because it is very difficult to describe an algorithm how choose the right one.
So there are two options … maybe more, but now I see only these twooption 1)
- find first duplicated strings in COLUMN3 and mark the rows where these strings are located (highlight and mark them).
- manually delete duplicate lines and repeat the searching
option 2)
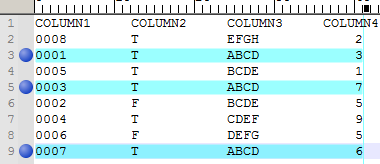
- find all duplicated strings in COLUMN3 and mark the rows where these strings are located (highlight and mark them).
- manually delete duplicate lines
-
You didn’t answer all my questions, and you didn’t follow the advice of giving us data in textual format. Until you do, we would only be guessing as to how wide those columns are.
I will try to describe it more precisely
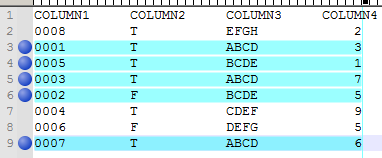
It was slightly better. I think I now understand that that you want to mark (and eventually delete) all the lines that have any of the duplicated column3 values, so the equivalent of the “all five” from my dummy example.
Please answer all these questions and supply all this data, or you won’t get a good answer and we will just waste our time trying to guess what you mean:
- Please copy your example text, as text, from Notepad++ and paste it into this reply; then highlight those 9 lines of text and click the
</>button . This will make your example text end up in a black box that we can easily copy/paste, like I showed in an earlier post. Otherwise, we will not know for sure how wide each column is. (Your recent screenshot has a little bit of a rule, but I wouldn’t trust that to give accurate results under certain circumstances.) Besides, giving us the data as pure text makes it easier for us to experiment with the regex before publishing it.
This will make your example text end up in a black box that we can easily copy/paste, like I showed in an earlier post. Otherwise, we will not know for sure how wide each column is. (Your recent screenshot has a little bit of a rule, but I wouldn’t trust that to give accurate results under certain circumstances.) Besides, giving us the data as pure text makes it easier for us to experiment with the regex before publishing it. - Are we allowed to permanently sort the data to make it easier, or does it have to end up in the same order it was when we started?
- If we aren’t allowed to permanently sort, could we temporarily sort the data (ie, change the order of the lines, run the regex, and then change the order of the lines back to the original)?
- If you say we cannot even temporarily sort, please explain in detail why that is not allowed.
- Do you need to have the marked version so you can be sure before deleting? Or is it okay to just immediately delete those rows?
My current high-level ideas:
If we’re allowed to permanently sort, it would be easiest: I would sort by column3, then look for any rows that have the same text in COLUMN3, then delete that whole span of text. QED.If we’re allowed to temporarily sort, it would be doable: we could use the column-editor to insert a temporary “original order” column so that we can get back to the original order at the end; then sort by the COLUMN3, delete the span as I suggested before, then sort by the inserted-original-order column, then remove that temporary column. It’s more work for us to describe and for you to implement, but in the end, the remaining data will still be in the same order it was originally.
If you need the intermediate examination of the rows, I would add a character to the end of the row before doing the final sort (instead of deleting the lines)… then after you’d confirmed, you could run a final regex to eliminate all the lines that end in that character.
Please note: if your next reply does not have the information or answers to all 5 of my questions, I will not be able to help you any more.
-–
Just a general note: a data table like you’ve shown is often better manipulated in something other than a text editor. If that data came from a database, it would really be best to do the data manipulation in the generating stage – where it makes this text report – rather than trying to post-process; ask your DB Admin or guru if it’s possible to have a modified report in the form you want it. If the data originally came from a spreadsheet, then this manipulation would be as easy to do within the spreadsheet program as it is in Notepad++; and even if it wasn’t a spreadsheet originally, you could import it back into a spreadsheet program to do the manipulations. I’m not saying that you shouldn’t use Notepad++ (heresy!), I am just saying that just because you have the world’s best hammer (Notepad++), that doesn’t mean that every job is a nail for you to hit; sometimes, a screwdriver could be more efficient. - Please copy your example text, as text, from Notepad++ and paste it into this reply; then highlight those 9 lines of text and click the
-
ad1)
Product Date/Time C T H Test Field Test Device Serial No Sensor Serial Software Version Battery Code Order No Inspector metalo 2021-03-09T14:21:17.600361 0 SUCCESS 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:21:30.437178 0 SUCCESS 013300000001 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:21:44.398500 0 SUCCESS 013300000001 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:21:53.262360 0 SUCCESS 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:22:09.373559 0 FAILED 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:22:23.436083 0 SUCCESS 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:22:34.567201 0 SUCCESS 013300000001 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:23:24.688700 0 SUCCESS 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:23:54.831355 0 SUCCESS 013300000001 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:24:11.763923 0 SUCCESS 013300000001 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:24:23.617504 0 SUCCESS 013300000001 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:24:36.528950 0 SUCCESS 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:24:50.557704 0 SUCCESS 013300000001 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:25:04.470269 0 SUCCESS 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:25:20.594258 0 SUCCESS 013300000001 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:25:48.726621 0 SUCCESS 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:26:00.645561 0 FAILED 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:26:12.536780 0 SUCCESS 013300000001 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:26:24.438022 0 SUCCESS 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1)I’m looking for matches in strings of type “A7615A4D1AD8C62E8C51DB0AD65185F2”
ad2) no it isn’t allowed
ad3) yes temporarily sort is possible. We can return rows by timestamp (second column)
ad4) -
ad5) I would like have the marked version and manually delete the rows.
-
@PeterJones said in Identical strings in column:
If you need the intermediate examination of the rows, I would add a character to the end of the row before doing the final sort (instead of deleting the lines)… then after you’d confirmed, you could run a final regex to eliminate all the lines that end in that character.
This solution would be good.
-
Hello, @petr-jaja, @peterjones and All,
I began to look to your problem, but I’ve found out a critical bug, in the N++ sort feature. My work-around could help @peterjones to build up a correct solution !
I’m also looking for a solution to the OP’s problem and I find a serious bug, in the N++ sort feature, when the column-mode selection is involved !
For a quick test, done with the
v7.9.2release, let use this simple part of the @petr-jaja’s text, below :013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 013300000001 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF 013300000001 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 013300000001 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 013300000001 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF 013300000001 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF 013300000001 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 013300000001 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF 013300000001 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 013300000001 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFFAs you can see, the different columns are separated with tabulation characters
In order to sort this text by increasing
MD5checksums :-
I created a zero-length column mode selection, at column
17, right before these hexadecimal strings -
I ran the
Edit > Line operations > Sort Lines Lexicographically Ascendingoption
And I got this output :
013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 013300000001 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF 013300000001 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF 013300000001 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF 013300000001 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF 013300000001 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF 013300000001 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF 013300000001 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF 013300000001 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF 013300000001 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFFObviously, these lines are not sorted by ascending
MD5checksums :-((
Now, let’s replace all the tabulations chars, between the string
013300000001and any checksum, by4fourspacecharacters. Thus, the text is changed as below :013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 013300000001 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF 013300000001 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 013300000001 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 013300000001 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF 013300000001 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF 013300000001 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 013300000001 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF 013300000001 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 013300000001 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFFFinally, let’s perform these two actions, again :
-
Create a zero-length column mode selection, at column
17, right before these hexadecimal strings -
Run the
Edit > Line operations > Sort Lines Lexicographically Ascendingoption
013300000001 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF 013300000001 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF 013300000001 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF 013300000001 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF 013300000001 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF 013300000001 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF idem 1 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF idem 1 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF idem 1 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF idem 2 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF idem 2 013300000001 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF Idem 3 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF Idem 3 013300000001 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF 013300000001 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFFThis time, as expected, all lines are correctly sorted by ascending
MD5checksums :-))Now, with the regex
(?-s)^.*([[:xdigit:]]{32}).*\R(?:.*\1.*\R)+, or just by examination in these few lines, it’s easy to verify, in the OP’s sample, that threeMD5checksums are duplicated. I added the stringIdem #to identify these lines easily.
Peter and all, could you confirm this bug, with the latest
v7.9.4N++ version, on recentW10laptop ? Many thanks by advance !Best Regards,
guy038
I verified that :
-
Any
TABcharacter, before thecolumn-modeselection, causes the sort bug -
Any
TABcharacter, after thecolumn-modeselection, is not relevant
-
-
Nope, I got right sorted columns even with a tab separator. Tested on Windows 7 & NPP v7.9.1 and on a fresh install of npp.7.9.4.portable.x64
HTH
-
I can duplicate @guy038 's sorting problem.
I’m sure it has to do with a tab being one character but being treated – or mistreated, as you like – as more than one.
It “throws” off the column used as the sort key.
I’m sure if one really looked hard at Guy’s bad results, the pattern could be detected (I’m not going to do that).Probably some code is “position” based but other code is “(effective) column” based.
It might be interesting to see if other ill-effects occur in this type of sorting situation when variable multibyte UTF+8 characters, rather than tabs, are involved. -
Given your answers, and the very different data, which takes a completely differnt regex than I was expecting:
- Duplicate the 32char alphanumeric to the start of line:
- FIND =
(?-s)(?=^.*\t([[:alnum:]]{32})\t)
REPLACE =$1\x20\x20\x20\x20\x20$0
MODE = regular expression
Replace All
- FIND =
- Sort:
- Select all but the first (header) line
- Edit > Line Operations > Sort Lines Lexicographically Ascending
- check for duplicates and mark with ✗
- FIND =
(?-s)^([[:alnum:]]{32})..\x20{3}(.*\R)^\1..\x20{3}
REPLACE =$1\x20✗\x20\x20\x20$2$1\x20✗\x20\x20\x20
MODE = regular expression
Replace All
- FIND =
- Manually check and delete:
- FIND =
(?-s)^([[:alnum:]]{32})\x20✗\x20{3}.*(\R|\z)
REPLACE = leave empty
MODE = Regular expression
Find Next, and Replace on the ones you want to delete; or Replace All if you’ve verified all are okay to delete
- FIND =
- Clean out extra column at the beginning
- FIND =
(?-s)^([[:alnum:]]{32})\x20.\x20{3}
REPLACE = leave empty
MODE = Regular expression
Replace All
- FIND =
- Sort:
- Select all but the first (header) line
- Edit > Line Operations > Sort Lines Lexicographically Ascending
(I use \x20 throughout to indicate a space, both in the search and in the replace expressions. That way, there is no ambiguity)
(@guy038 , @Alan-Kilborn , @astrosofista : by grabbing a copy of the 32-char field at the beginning, and using spaces to separate, I ignored the problem of the tab-sorting, and eliminated the need to do a column-select for a sort. it made it much easier to implement and explain)
@Petr-Jaja ,I think this does it for you. Notice that I ignored which column number the 32 alpha-numeric sequence is in, as long as it has a tab before and after. This matches the data you showed (which had only one field that was 32 characters exactly), but might not match reality. The answers you get are only as good as the data you give.
caveat emptor
This sequence seemed to work for me, based on my understanding of your issue, and is published here to help you learn how to do this. I make no guarantees or warranties as to the functionality for you. You are responsible to save and backup all data before and after running this sequence.
- Duplicate the 32char alphanumeric to the start of line:
-
Hello, @petr-jaja, @peterjones, @astrosofista, @alan-kilborn and All,
Well, it’s going worse than I initially thought ! And the @alan-kilborn’s assumptions are certainly true, as well !
First, for nice testing, you must use, at least, the
v7.9release, which corrects some sorting problems ( but not all, apparently ! ) when using thecolumn modeselection !So, let’s consider this initial text, below, where I changed the last char of the string
013300000001, beginning the linesI used, alternatively, in an
UTF-8encoded file :-
The character
1, coded inUTF-8, with one byte (31) -
The character
é, coded inUTF-8, with two bytes (C3A9) -
The character
∑, coded inUTF-8, with three bytes (E28891) -
The character
🦅, coded inUTF-8, with four bytes (F09FA685)
01330000000🦅 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 01330000000é 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF 01330000000∑ 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF 01330000000é C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 01330000000∑ 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF 01330000000🦅 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 01330000000é E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF 01330000000∑ 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF 01330000000🦅 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 01330000000é 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF 01330000000∑ D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF 01330000000é A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 01330000000🦅 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFFWith the
v7.9.2release, after doing a zero-length column-mode selection, at column17, right before theMD5checksums, through all the lines and running a usualSort Lines Lexicographically Ascending, I got this text :01330000000🦅 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF 01330000000🦅 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 01330000000🦅 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 01330000000🦅 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF 01330000000é 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF 01330000000∑ 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF 01330000000∑ 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF 01330000000é 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF 01330000000∑ 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF 01330000000é A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 01330000000é C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 01330000000∑ D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF 01330000000é E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFFAs you can see, the
MD5strings seem to be sorted in two distinct ranges :-
A first block of lines, containing the character with Unicode code-point over
U+FFFF -
A second block of lines, containing, only, characters with Unicode code-point under
U+10000
Again, I verified that, if I inserted these same characters, instead of the first char of the
0126...string, so after theMD5values to sort, the bug does not occur and theMD5checksums are correctly sorted !So, guys, I’ll probably create an issue, after your possible replies !
Best Regards,
guy038
-
-
Here’s a series of screenshots for the 6 steps, showing it in action
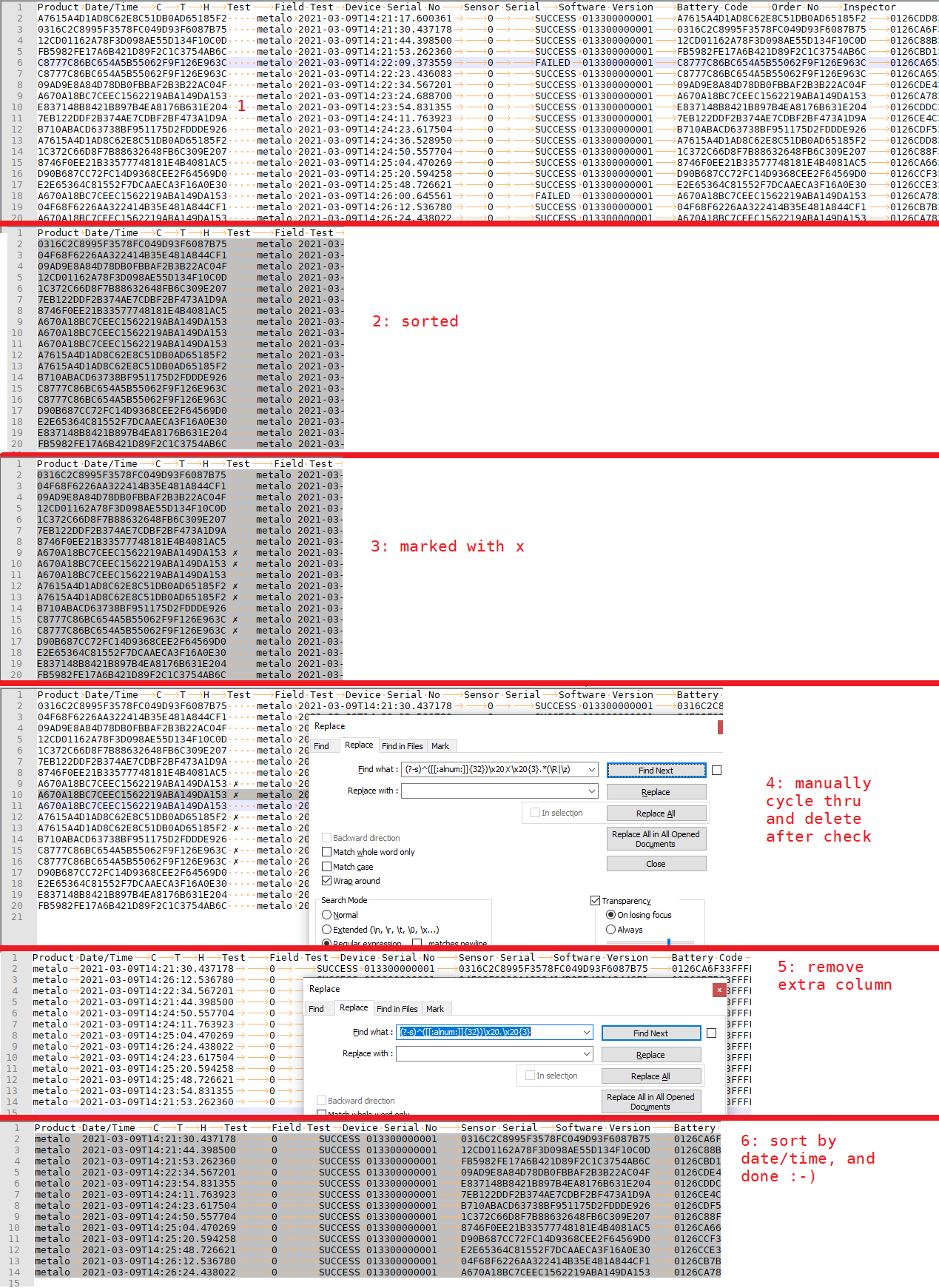
-
Hello, @petr-jaja, @peterjones, @astrosofista, @alan-kilborn and All,
I think that a solution, in fewer steps, should be possible !
Let’s start with the initial example of @petr-jaja, in this post :
https://community.notepad-plus-plus.org/post/63869
First, like @peterjones said, we copy the
MD5checksums at beginning of each line :-
SEARCH
(?-s)^.+\t([[:xdigit:]]{32})\t -
REPLACE
\1\t$0
So, we get this text :
Product Date/Time C T H Test Field Test Device Serial No Sensor Serial Software Version Battery Code Order No Inspector A7615A4D1AD8C62E8C51DB0AD65185F2 metalo 2021-03-09T14:21:17.600361 0 SUCCESS 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 0316C2C8995F3578FC049D93F6087B75 metalo 2021-03-09T14:21:30.437178 0 SUCCESS 013300000001 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 12CD01162A78F3D098AE55D134F10C0D metalo 2021-03-09T14:21:44.398500 0 SUCCESS 013300000001 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) FB5982FE17A6B421D89F2C1C3754AB6C metalo 2021-03-09T14:21:53.262360 0 SUCCESS 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) C8777C86BC654A5B55062F9F126E963C metalo 2021-03-09T14:22:09.373559 0 FAILED 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) C8777C86BC654A5B55062F9F126E963C metalo 2021-03-09T14:22:23.436083 0 SUCCESS 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 09AD9E8A84D78DB0FBBAF2B3B22AC04F metalo 2021-03-09T14:22:34.567201 0 SUCCESS 013300000001 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) A670A18BC7CEEC1562219ABA149DA153 metalo 2021-03-09T14:23:24.688700 0 SUCCESS 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) E837148B8421B897B4EA8176B631E204 metalo 2021-03-09T14:23:54.831355 0 SUCCESS 013300000001 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 7EB122DDF2B374AE7CDBF2BF473A1D9A metalo 2021-03-09T14:24:11.763923 0 SUCCESS 013300000001 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) B710ABACD63738BF951175D2FDDDE926 metalo 2021-03-09T14:24:23.617504 0 SUCCESS 013300000001 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) A7615A4D1AD8C62E8C51DB0AD65185F2 metalo 2021-03-09T14:24:36.528950 0 SUCCESS 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 1C372C66D8F7B88632648FB6C309E207 metalo 2021-03-09T14:24:50.557704 0 SUCCESS 013300000001 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 8746F0EE21B33577748181E4B4081AC5 metalo 2021-03-09T14:25:04.470269 0 SUCCESS 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) D90B687CC72FC14D9368CEE2F64569D0 metalo 2021-03-09T14:25:20.594258 0 SUCCESS 013300000001 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) E2E65364C81552F7DCAAECA3F16A0E30 metalo 2021-03-09T14:25:48.726621 0 SUCCESS 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) A670A18BC7CEEC1562219ABA149DA153 metalo 2021-03-09T14:26:00.645561 0 FAILED 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 04F68F6226AA322414B35E481A844CF1 metalo 2021-03-09T14:26:12.536780 0 SUCCESS 013300000001 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) A670A18BC7CEEC1562219ABA149DA153 metalo 2021-03-09T14:26:24.438022 0 SUCCESS 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1)Then, select all lines, but the first header line and sort lines with the
Edit > Line Operations > Sort Lines Lexicographically Ascendingmenu commandWe get :
Product Date/Time C T H Test Field Test Device Serial No Sensor Serial Software Version Battery Code Order No Inspector 0316C2C8995F3578FC049D93F6087B75 metalo 2021-03-09T14:21:30.437178 0 SUCCESS 013300000001 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 04F68F6226AA322414B35E481A844CF1 metalo 2021-03-09T14:26:12.536780 0 SUCCESS 013300000001 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 09AD9E8A84D78DB0FBBAF2B3B22AC04F metalo 2021-03-09T14:22:34.567201 0 SUCCESS 013300000001 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 12CD01162A78F3D098AE55D134F10C0D metalo 2021-03-09T14:21:44.398500 0 SUCCESS 013300000001 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 1C372C66D8F7B88632648FB6C309E207 metalo 2021-03-09T14:24:50.557704 0 SUCCESS 013300000001 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 7EB122DDF2B374AE7CDBF2BF473A1D9A metalo 2021-03-09T14:24:11.763923 0 SUCCESS 013300000001 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) 8746F0EE21B33577748181E4B4081AC5 metalo 2021-03-09T14:25:04.470269 0 SUCCESS 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) A670A18BC7CEEC1562219ABA149DA153 metalo 2021-03-09T14:23:24.688700 0 SUCCESS 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) A670A18BC7CEEC1562219ABA149DA153 metalo 2021-03-09T14:26:00.645561 0 FAILED 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) A670A18BC7CEEC1562219ABA149DA153 metalo 2021-03-09T14:26:24.438022 0 SUCCESS 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) A7615A4D1AD8C62E8C51DB0AD65185F2 metalo 2021-03-09T14:21:17.600361 0 SUCCESS 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) A7615A4D1AD8C62E8C51DB0AD65185F2 metalo 2021-03-09T14:24:36.528950 0 SUCCESS 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) B710ABACD63738BF951175D2FDDDE926 metalo 2021-03-09T14:24:23.617504 0 SUCCESS 013300000001 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) C8777C86BC654A5B55062F9F126E963C metalo 2021-03-09T14:22:09.373559 0 FAILED 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) C8777C86BC654A5B55062F9F126E963C metalo 2021-03-09T14:22:23.436083 0 SUCCESS 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) D90B687CC72FC14D9368CEE2F64569D0 metalo 2021-03-09T14:25:20.594258 0 SUCCESS 013300000001 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) E2E65364C81552F7DCAAECA3F16A0E30 metalo 2021-03-09T14:25:48.726621 0 SUCCESS 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) E837148B8421B897B4EA8176B631E204 metalo 2021-03-09T14:23:54.831355 0 SUCCESS 013300000001 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) FB5982FE17A6B421D89F2C1C3754AB6C metalo 2021-03-09T14:21:53.262360 0 SUCCESS 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1)
Now, three options are possible :
-
You would like to get an idea of the different duplicate
MD5strings and lines which need future deletion ( option A ) -
You would like to delete the duplicate
MD5strings, one at a time, with theReplacebutton ( Option B ) -
You are rather confident about all the replacements to achieve . For instance, you have made a backup of your file ! ( Option C )
Whatever the option chosen, remember to :
-
Tick the
Wrap aroundoption -
Select the
Regular expressionsearch mode
-
Option A :
-
Open the Mark dialog (
Ctrl + M)-
SEARCH
(?-s)^.*([[:xdigit:]]{32}).*\R(?:.*\1.*\R)+ -
Tick the
Bookmark lineoption -
Click on the
Mark Allbutton -
Note that using the
Search > Bookmark > Remove Bookmarked Linesoption, you can also delete all the lines with duplicateMD5strings !
-
-
-
Option B :
-
Open the Replace dialog (
Ctrl + H)-
SEARCH
(?-s)^.*([[:xdigit:]]{32}).*\R(?:.*\1.*\R)+ -
REPLACE
Leave EMPTY -
Click several times on the
Replacebutton to delete the first duplicate blocks of lines -
If everything seems OK, you may click once on the
Replace Allbutton
-
-
After deletion of the lines with duplicates, with the options A or B, uses the following regex S/R to get rid of the temporary
MD5strings at beginning of lines ;:-
SEARCH
(?-i)^(?!Product).+?\t(.) -
REPLACE
\1
-
-
-
Option C :
-
Open the Replace dialog (
Ctrl + H)-
SEARCH
(?-is)^.*([[:xdigit:]]{32}).*\R(?:.*\1.*\R)+|^(?!Product).+?\t(.) -
REPLACE
?2\2 -
Click, just once, on the
Replace Allbutton
-
-
Whatever the option A, B, or C used, we obtain that text :
Product Date/Time C T H Test Field Test Device Serial No Sensor Serial Software Version Battery Code Order No Inspector metalo 2021-03-09T14:21:30.437178 0 SUCCESS 013300000001 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:26:12.536780 0 SUCCESS 013300000001 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:22:34.567201 0 SUCCESS 013300000001 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:21:44.398500 0 SUCCESS 013300000001 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:24:50.557704 0 SUCCESS 013300000001 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:24:11.763923 0 SUCCESS 013300000001 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:25:04.470269 0 SUCCESS 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:24:23.617504 0 SUCCESS 013300000001 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:25:20.594258 0 SUCCESS 013300000001 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:25:48.726621 0 SUCCESS 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:23:54.831355 0 SUCCESS 013300000001 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:21:53.262360 0 SUCCESS 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1)Finally, select all lines, but the first header line, again and sort the lines with the
Edit > Line Operations > Sort Lines Lexicographically Ascendingmenu commandYou should get your expected output :
Product Date/Time C T H Test Field Test Device Serial No Sensor Serial Software Version Battery Code Order No Inspector metalo 2021-03-09T14:21:30.437178 0 SUCCESS 013300000001 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:21:44.398500 0 SUCCESS 013300000001 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:21:53.262360 0 SUCCESS 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:22:34.567201 0 SUCCESS 013300000001 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:23:54.831355 0 SUCCESS 013300000001 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:24:11.763923 0 SUCCESS 013300000001 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:24:23.617504 0 SUCCESS 013300000001 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:24:50.557704 0 SUCCESS 013300000001 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:25:04.470269 0 SUCCESS 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:25:20.594258 0 SUCCESS 013300000001 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:25:48.726621 0 SUCCESS 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1) metalo 2021-03-09T14:26:12.536780 0 SUCCESS 013300000001 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF v2.7.1-UROB-20210112085121 (v8.7.1)Best Regards,
guy038
-
It’s weird : Although there is a tabulation char after each word
metalo, the lines are correctly sorted by increasing time if I perform a zero-length selection at column9, right before the year ! -
It’s a chance, for me and you, that the
Date-Timecolumn is located near the beginning of lines. It allows us to find the initial lines order back, with a classical selection ;-))
-
-
@guy038 said in Identical strings in column:
Well, it’s going worse than I initially thought ! And the @alan-kilborn’s assumptions are certainly true, as well !
Intrigued by test reports with mixed outcomes, I run further tests on the same example data aiming to obtain some clarification. As before, tests were run on Windows 7 and NPP v7.9.1 and 7.9.4 RC, and threw the same outcome.
Example data with tabs, zero-length column mode selection in:
column 01 -> sorted correctly, the column mode selection remains unchanged
column 13 -> sorted correctly, but lost the column mode selection and the caret was moved to line 1, column 1
column 17 -> sorted incorrectly, lost the column mode selection and the caret was moved to line 1, column 1Now if I select all the tabs between strings 013300000001 and any checksum with a rectangular selection, backspace to delete them, get a zero-length column, type four spaces and immediately run a sort, then the command is ignored and example data remains unchanged.
Need to make a new zero-length column mode selection at columns 01, 13, or 17 in order to get example data correctly sorted. On the downside, lost the column mode selection and the caret was unexpectedly moved to line 1, column 1.
Hope this makes sense.
-
Hi, @petr-jaja, @peterjones, @astrosofista, @alan-kilborn and All,
@astrosofista, thanks for your insight, but I worked on my side and I’ve found out a coherent explanation which means that is, finally, a predictable bug !
Yes, I’m glad because I find out the algorithm which fully explains how the
column-modesort behaves ;-))
-
First, it only concerns the
TABcharacters, located before the position of your zero-lengthcolumn-modeselection. Now : -
For each
TABcharacter, estimate the numbernof positions, taken by theTABcharacter and, then, note the numbern - 1 -
Add up all these numbers
n- 1( so,n1 - 1+n2 - 1+n3 - 1+ … =S)
This sum
Sis the offset between the user columnCuof your zero-length selection AND the real columnCr, used to perform thecolumn-modesort. Hence the relationCr = Cu + S
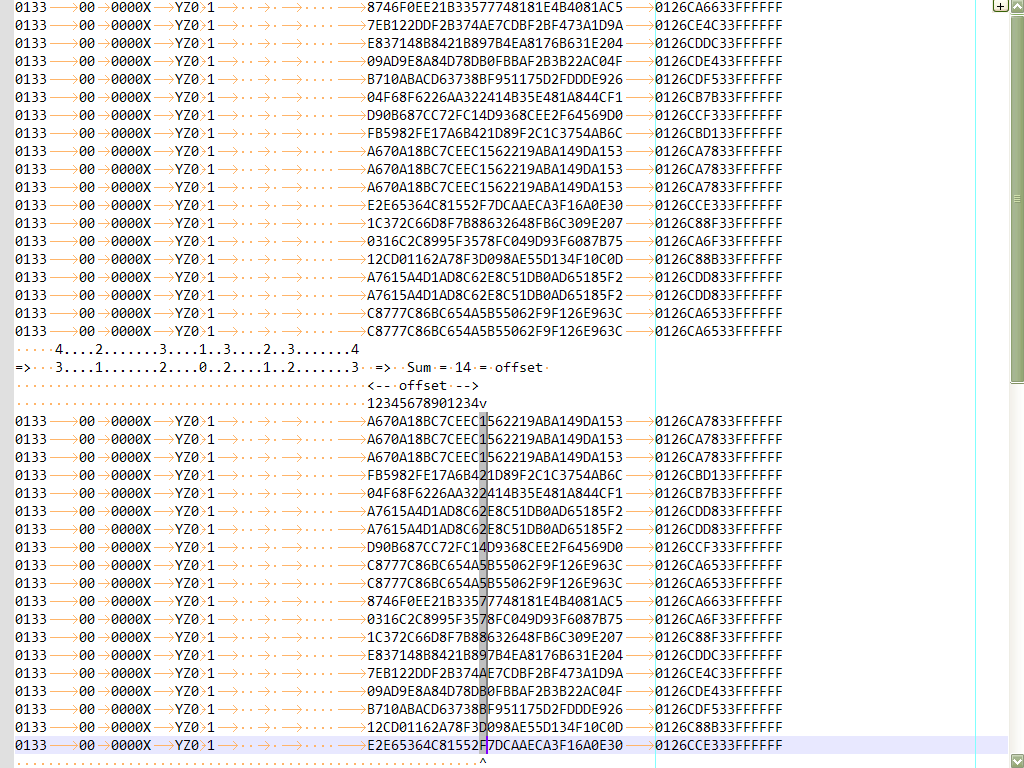
One example ( refer to the picture, below )
-
The first table, before the sort, with a zero-length column-mode selection, at column
45 -
The second table, after the sort, is not sorted, obviously, at column
45 -
Each line contains
8tabulations before column45 -
The positions, taken by each tabulation, are, respectively,
4,2,3,132,3and4 -
So, the numbers
n - 1are, respectively,3,1,2,021,2and3 -
The sum of all these “
n - 1” numbers is14 -
So, although you think to sort at column
45, where you did thecolumn-modeselection, the effective sort will begin at column
45 + 14, so at column59of each line ! ( The column-selected column, in the picture )
Best Regards
guy038
P.S. :
-
I also verified that, after changing the number of positions for tabulations, in
normaltext, either below or above the default value4, in thePreferencesdialog, my algorithm is still correct and always gives, in all cases, the real column of the sort ! -
Text in an
ANSIencoded file, is sorted, using this same algorithm, too
Oh, I forgot to give the raw text :
0133 00 0000X YZ0 1 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF 0133 00 0000X YZ0 1 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF 0133 00 0000X YZ0 1 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF 0133 00 0000X YZ0 1 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF 0133 00 0000X YZ0 1 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF 0133 00 0000X YZ0 1 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF 0133 00 0000X YZ0 1 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF 0133 00 0000X YZ0 1 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF 0133 00 0000X YZ0 1 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 0133 00 0000X YZ0 1 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 0133 00 0000X YZ0 1 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 0133 00 0000X YZ0 1 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF 0133 00 0000X YZ0 1 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF 0133 00 0000X YZ0 1 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF 0133 00 0000X YZ0 1 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF 0133 00 0000X YZ0 1 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 0133 00 0000X YZ0 1 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 0133 00 0000X YZ0 1 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 0133 00 0000X YZ0 1 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF
Last thought :
If you intend to use a
column-modeselection for a sort, starting at a specific column, the best would be to run, first, aEdit > Blank Operations > TAB to Spacecommand in order to delete anytabulationcharacter, without changing the presentation of the text ! -
-
So something smells bad here, and it isn’t just tab characters.
I looked at @guy038 's data, from the post where he said:

If I paste this data into a new tab, and convert tabs-to-spaces (to forget about tabs for now), I get something that appears like this:

If I then try to make a zero-width column selection, it looks like this:
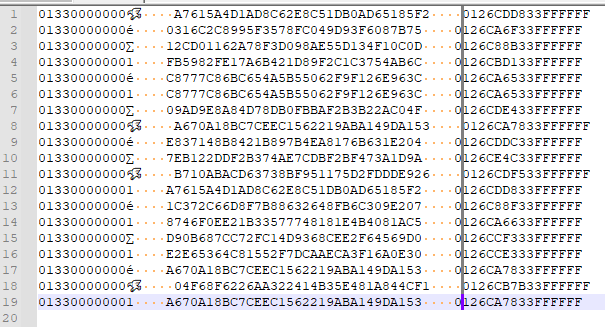
But this isn’t right…the column caret should be to the left of the leading zero of the third column of data for the entire block, but it isn’t.
Thus if I attempt a sort, I definitely don’t obtain what I intend.
And no tabs involved.
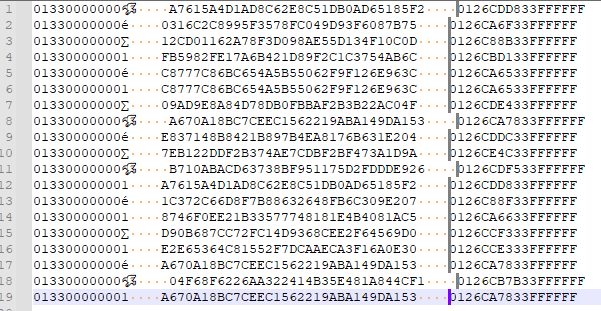
This problem goes deeper than sorting, I think this is a Scintilla problem.
Just because the “little birdie” appears to take up two columns, he doesn’t–he’s only one character, just like all the rest of the final characters in column 1 of the data.The following is what a proper column selection should look like for this data:
-
Hello,
Great :-) It looks very nice. I have tested three files and the algorithm worked fine. I have found there only one problem. If there are more than two equal strings in the file, the sequence 3 indicates only first two of them.
Tested on v.7.9.3 - 32bit -
Thanks for this idea.
I have used at first TextFX Tools – sort lines by column and then marking lines according to your solution. Option A looks most suitable for my issue.
Tested on v.7.9.3 - 32bit -
Hello @alan-kilborn,
As you can see, in the picture below, sometines, even with
Monospacedfonts, some characters as the∑and other symbols like🦅do not have the same width than standardANSIcharacters, when displayed in Notepad++ !The raw text is :
01330000000🦅 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 01330000000é 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF 01330000000∑ 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF 01330000000é C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 01330000000∑ 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF 01330000000🦅 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 01330000000é E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF 01330000000∑ 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF 01330000000🦅 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 01330000000é 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF 01330000000∑ D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF 01330000000é A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 01330000000🦅 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFFSo,if your going to use the
colum-modefeature, I think that the best is to switch, first, to a classical true monospaced font, likeConsolasorCourier New!
Best Regards
guy038
-
@guy038 said in Identical strings in column:
if … use the column-mode feature, … best is to switch … to … true monospaced font, like … Courier New !
So I’m confused.
My screenshots in my immediately previous post WERE made with the font set to Courier New.So remembering that I’ve converted all tabs to spaces, if I put my caret here:

and I press Shift+Alt+downArrow, I should get this:
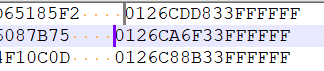
because that is the only way to keep the same number of characters to the left of both carets in their respective lines.
But what I actually obtain is this:
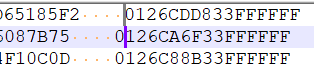
which puts 52 characters to the left of the caret on line 1, and 53 characters to the left of the caret on line 2. And for a column mode selection this makes no sense. It is like it is doing it on a visual basis…and what good is that?!
So as an example that should really hammer this home, what if I insert a character, for example, an
a. Here’s what happens: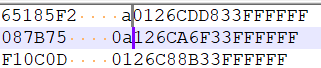
That’s wrong!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login