Identical strings in column
-
Hi, @alan-kilborn,
Don’t be bothered by my reply. Results can be different because of:
-
My old
Win XPmachine -
Old versions of some of my fonts
-
The
substitutionfonts, used by the system, to display particularUnicodeblocks -
The
fallbackfont used by the system
So, just be patient, for a while, and we’ll speak about this later, when I finally get this bloody
Win 10laptop ;-)) Otherwise, I’ll won’t be able to follow the latest N++ releases, any more !BR
guy038
-
-
Hmmm, well, Courier New seems to be about as “vanilla” as one can get, given that it is the default font in Notepad++, and every Windows computer since time began has it (I suppose).
It seems like a non-power user trying to do what I’ve shown, is going to encounter a similar problem, and complain. I guess it is debatable whether or not a non-power user is going to be doing column blocking, but maybe not out of the question.
I’m willing to keep talking about this (if there’s more to say), in the context of your old computer, because I feel this has been in existence in N++ for a long time, so such discussions should be valid.
-
Sorry. I thought briefly about that condition when I started, but I didn’t notice your 3+ example in your data when I was debugging my answer, so forgot.i am on my phone now. Maybe later today, I will get a chance to be on the computer and work on this more.
Also, maybe @guy038 solution would work better for you. ( I haven’t tried it. )
-
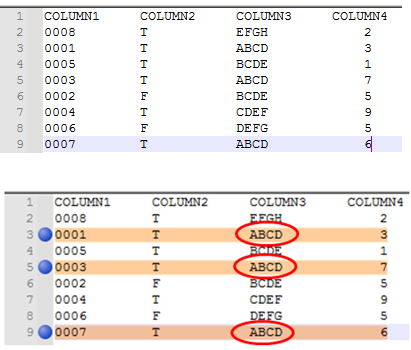
@Petr-Jaja said in Identical strings in column:
If there are more than two equal strings in the file, the sequence 3 indicates only first two of them.
Okay, I found a workaround. I tried a clever alternation with \K on one of them, or anchoring on \G, but that wasn’t working easily. So, as I often do for practical solutions rather than optimized solutions, I added another step.
Step 4 (as listed above) will catch 2, or 4, or 6, or any even number of replicated rows. But any odd number of rows will miss the last row. So added a step 4b:
- Find What =
(?-s)^([[:alnum:]]{32}).✗\x20{3}.*\R\K\1\x20{5}
Replace With =$1\x20✗\x20\x20\x20
This will take care of the odd rows out. (I tried on 2,3,4,5,6, and 7 repeats, and I see no reason it woudn’t work beyond that)
Someone cleverer than I am might be able to come up with the magical formula to reduce the number of steps. And that’s great if you’re writing an application that will be running the regex millions of times, where the efficiency improvement might save significant time (and thus money) over the lifetime of the regex. But for a sequence that you’re just running once, or only occasionally on a small number of rows, efficiency isn’t the most important.
- Find What =
-
I also tried @guy038 solution from his “I think that a solution, in fewer steps, should be possible !” post: it worked first try, without modification, on your example data, or on data modified to have two, three, four, five, six, and seven repeat rows (and thus there is no reason it shouldn’t on reasonable n>7). So his should work for you, too.
-
I have tested your solutions and both work fine. However, for futher work I will use probably the solution from @guy038 because it is a little bit faster.
Thank you very very much for your help.Tested - NP v.7.9.3 on Win10, Win7
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login