Python script plugin console to open multiple files
-
I have a ‘filenames.txt’ where each line has the full path to a file, and I want to open all the files in the ‘filenames.txt’ from Python Script Plugin console. And here’s what I’m doing:
f = open("C:/Users/junew/Desktop/filesnames.txt", "r"); lines = f.readlines(); for i in lines: notepad.open(i)When I try lines[0], the output is
'F:/06__Other_Models/Transport/round1/convert2/58542_\xd0\x9f\xd0\xbe\xd0\xb3\xd1\x80\xd1\x83\xd0\xb7\xd1\x87\xd0\xb8\xd0\xba.mtl\n'the true path is
F:/06__Other_Models/Transport/round1/convert2/58542_Погрузчик.mtlI can open it using notepad.open(‘F:/06__Other_Models/Transport/round1/convert2/58542_Погрузчик.mtl’). But from python console using above code, notepad++ keeps saying ‘File F:/06__Other_Models/Transport/round1/convert2/58542_Погрузчик.mtl doesn’t exist’, I think it has something to do with the non UTF-8 encoded file(names).
Any idea how to get around it?
-
-
@June-Wang said in Python script plugin console to open multiple files:
I can open it using notepad.open(‘F:/06__Other_Models/Transport/round1/convert2/58542_Погрузчик.mtl’). But from python console using above code, notepad++ keeps saying ‘File F:/06__Other_Models/Transport/round1/convert2/58542_Погрузчик.mtl doesn’t exist’, I think it has something to do with the non UTF-8 encoded file(names).
Actually,
\xd0\x9fis the two-byte sequence to representПin UTF-8. However, it may be that there is an encoding/decoding trick that you need to take in Python to convert the raw UTF-8 bytes read from the file to translate to the valid pathname. I’m not an expert on Python+encoding.However, I see one more problem:
.mtl\n': because you read the line from a newline-delimited file, you still have a newline in each line. You should really remove the trailing newline sequence before passing it to thenotepad.open()command. -
Ah, @Ekopalypse showed it working with the name represented with the \x## notation, so that doesn’t appear to be the problem. I then think it’s the newline sequence at the end of your text line, because the real filename doesn’t end in newline.
-
I confirmed:
>>> n = 'C:/Users/peter.jones/Downloads/TempData/nppCommunity/\xd0\x9f\xd0\xbe\xd0\xb3\xd1\x80\xd1\x83\xd0\xb7\xd1\x87\xd0\xb8\xd0\xba.mtl' >>> notepad.open(n)opened the file just fine, but
>>> n = 'C:/Users/peter.jones/Downloads/TempData/nppCommunity/\xd0\x9f\xd0\xbe\xd0\xb3\xd1\x80\xd1\x83\xd0\xb7\xd1\x87\xd0\xb8\xd0\xba.mtl\n' >>> notepad.open(n)shows
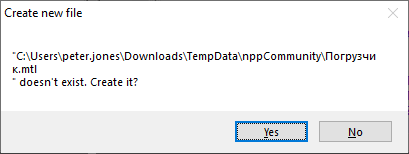
Notice the newline between
.mtland the end-quote" -
@June-Wang said in Python script plugin console to open multiple files:
notepad.open(i)
So maybe OP should try:
notepad.open(i.rstrip()) -
@Alan-Kilborn said in Python script plugin console to open multiple files:
notepad.open(i.rstrip())
That worked ! Thank you all so much! @Ekopalypse @PeterJones
-
@PeterJones @Ekopalypse @Alan-Kilborn
Btw, anyone knows how to tell if a file selects ANSI or Character sets ? Right now if a file that has Character sets selected, and a file that has ANSI selected will both return true on the following commands.notepad.runMenuCommand("Encoding", 'Character sets') notepad.runMenuCommand("Encoding", 'ANSI') -
These commands are used to call menu items and just return true if a menu item was found.
Do you want to find out which encoding has been assigned by notepad++? -
@Ekopalypse said in Python script plugin console to open multiple files:
Do you want to find out which encoding has been assigned by notepad++?
Is this one going to end HERE?
-
Eventually, we could find a solution to read the value from the status bar if that is really what is being looked for, but it must be clear that this is just an estimate from Npp and in the worst case it is just wrong.
-
@Ekopalypse said in Python script plugin console to open multiple files:
@June-Wang
Do you want to find out which encoding has been assigned by notepad++?Kind of, I don’t know much about encoding methods. Just trying to check if Encoding->Character sets selected in a file, continue; if NTF-8 selected, close; else, convert to NTF-8, save N close. I just read the other thread mentioned above, and put together this code.
if notepad.runMenuCommand("Encoding", "Character sets") and notepad.getEncoding() =='Npp.BUFFERENCODING.COOKIE': continue elseif notepad.runMenuCommand("Encoding", "NTF-8"): notepad.close() else: notepad.runMenuCommand("Encoding", "Convert to UTF-8") notepad.save() notepad.close()Thought it should work. However, for a file that has Character sets selected, when I do notepad.getEncoding() from console, it returns Npp.BUFFERENCODING.COOKIE. But when I do a compare notepad.getEncoding() ==‘Npp.BUFFERENCODING.COOKIE’, it returns false.
-
I guess this one should do what you are looking for.
As for ANSI and CharacterSet, they are basically the same thing, they are the 8bit encoding.
ANSI is what the system is currently configured with and CharacterSet can be used if you want to display a different 8bit encoding.
For example, if you have a German setup, ANSI is equal to Windows-1252,
but if you get a Russian text, you may need to select Windows-1251 to see the Cyrillic symbols.import ctypes from ctypes.wintypes import HWND, UINT, LPARAM, WPARAM, LPCWSTR user32 = ctypes.WinDLL('user32') LRESULT = LPARAM SendMessage = user32.SendMessageW SendMessage.argtypes = [HWND, UINT, WPARAM, LPARAM] SendMessage.restype = LRESULT FindWindow = user32.FindWindowW FindWindow.argtypes = [LPCWSTR, LPCWSTR] FindWindow.restype = HWND FindWindowEx = user32.FindWindowExW FindWindowEx.restype = HWND FindWindowEx.argtypes = [HWND, HWND, LPCWSTR, LPCWSTR] WM_USER = 1024 SB_GETTEXTW = WM_USER+13 SB_GETTEXTLENGTHW = WM_USER+12 def get_assumed_encoding(statusbar_hwnd): buffer_length = user32.SendMessageW(statusbar_hwnd, SB_GETTEXTLENGTHW, 4, 0) buffer = ctypes.create_unicode_buffer(buffer_length+1) user32.SendMessageW(statusbar_hwnd, SB_GETTEXTW, 4, ctypes.addressof(buffer)) return buffer.value def main(): npp_hwnd = FindWindow(u'Notepad++', None) statusbar_hwnd = FindWindowEx(npp_hwnd, None, u"msctls_statusbar32", None) # for each file in ... do encoding = get_assumed_encoding(statusbar_hwnd) if encoding == 'UTF-8': notepad.close() elif encoding in ['UTF-8-BOM', 'UCS-2 BE BOM', 'UCS-2 LE BOM']: # what to do here?? pass else: # ANSI and Character set notepad.runMenuCommand("Encoding", "Convert to UTF-8") notepad.save() notepad.close() main()UPDATE: A word of warning, Npp can only ACCEPT the coding, it has no chance to be 100 sure this is the correct one.
-
this
UPDATE: A word of warning, Npp can only ACCEPT the coding, it has no chance to be 100 sure this is the correct one.
should be
UPDATE: A word of warning, Npp can onlyASSUMEthe encoding, it has no chance to be 100 sure this is the correct one. -
@Ekopalypse said in Python script plugin console to open multiple files:
As for ANSI and CharacterSet, they are basically the same thing, they are the 8bit encoding.
else: # ANSI and Character set notepad.runMenuCommand("Encoding", "Convert to UTF-8") notepad.save() notepad.close()Thank you. So there’s no way to tell if a file is Character sets selected or not? But notepad.getEncoding() outputs differently tho.
On Character sets selected file, it outputsNpp.BUFFERENCODING.COOKIEOn ANSI selected file, it outputs
Npp.BUFFERENCODING.ENC8BIT -
If you use the code I posted, you can distinguish between
ANSI and CharacterSet by checking for ANSI, with another elif branchelif encoding == 'ANSI' ...But why would you want to do that??
-
@Ekopalypse
Nice, that worked!
The software I used to output my current data is unable to output unicode data when it comes to foreign language, sometimes it’s ANSI in Npp++, sometimes it’s Character sets selected, but, i.e. Хромм_слабe turns out to be 孚把抉技技_扼抖忘忌e . Now I need to import those data to another software, but it only accepts UTF-8 encoded. So I have to convert ANSI to UTF-8, and manually fix the ones that have Character sets selected, otherwise they show up as boxes. Not fun :( -
@June-Wang said in Python script plugin console to open multiple files:
The software I used to output my current data is unable to output unicode data
Unicode was invented in 1991 ↗, and UTF-8 encoding was invented in 1992 ↗. Software developers have had 30 years to adapt. And most software I’ve seen from the last decade or so knows how to use UTF-8. Any software still under active development should have figured out UTF-8 by now; if they haven’t, and if you (or a company you work for) are a paying customer, I would start making frequent requests to find out what their schedule for upgrading from pre-1990’s technology is.
That said, I’m glad that Notepad++ (plus plugins) is able to help you overcome this extreme deficiency in output ability of this other software. Good luck.
-
This post is deleted!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login