Issue with Polish letters
-
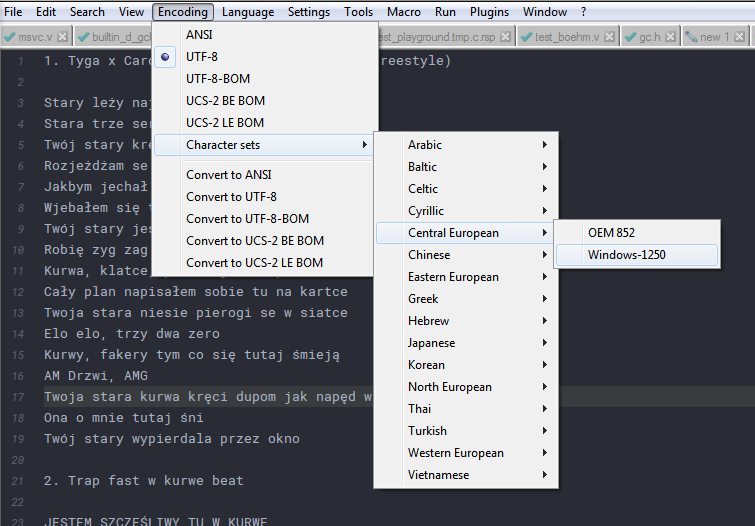
That means, select Windows-1250
and if it looks ok - convert to utf8 - save it - done.
-
@Ekopalypse Thanks Eko a lot!
-
@nightznero - my pleasure.
-
I didn’t follow super-closely, but was there reason to not convert to UTF-8 and then stay with that?
-
We had to find the right (ansi) encoding first, otherwise the conversion to utf-8 would result in incorrect text.
-
Hello, @nightznero, @alan-kilborn, @ekopalypse and All,
Encoding notions are really difficult to handle and are usually a nightmare for most of us !
From the @nightznero’s problem, I tried to build a method to guess the right encoding of an
ANSIencoded file, containing characters wrongly displayed !
- First, copy all the text, below, in the clipboard :
•--------•---------•---------•---------•---------•---------•---------•---------• | Code | Win1250 | Win1251 | Win1252 | Win1253 | Win1254 | Win1257 | Win1258 | •--------•---------•---------•---------•---------•---------•---------•---------• | 80 | € | Ђ | € | € | € | € | € | | 81 | ◊ | Ѓ | ◊ | ◊ | ◊ | ◊ | ◊ | | 82 | ‚ | ‚ | ‚ | ‚ | ‚ | ‚ | ‚ | | 83 | ◊ | ѓ | ƒ | ƒ | ƒ | ◊ | ƒ | | 84 | „ | „ | „ | „ | „ | „ | „ | | 85 | … | … | … | … | … | … | … | | 86 | † | † | † | † | † | † | † | | 87 | ‡ | ‡ | ‡ | ‡ | ‡ | ‡ | ‡ | | 88 | ◊ | € | ˆ | ◊ | ˆ | ◊ | ˆ | | 89 | ‰ | ‰ | ‰ | ‰ | ‰ | ‰ | ‰ | | 8A | Š | Љ | Š | ◊ | Š | ◊ | ◊ | | 8B | ‹ | ‹ | ‹ | ‹ | ‹ | ‹ | ‹ | | 8C | Ś | Њ | Œ | ◊ | Œ | ◊ | Œ | | 8D | Ť | Ќ | ◊ | ◊ | ◊ | ¨ | ◊ | | 8E | Ž | Ћ | Ž | ◊ | ◊ | ˇ | ◊ | | 8F | Ź | Џ | ◊ | ◊ | ◊ | ¸ | ◊ | | 90 | ◊ | ђ | ◊ | ◊ | ◊ | ◊ | ◊ | | 91 | ‘ | ‘ | ‘ | ‘ | ‘ | ‘ | ‘ | | 92 | ’ | ’ | ’ | ’ | ’ | ’ | ’ | | 93 | “ | “ | “ | “ | “ | “ | “ | | 94 | ” | ” | ” | ” | ” | ” | ” | | 95 | • | • | • | • | • | • | • | | 96 | – | – | – | – | – | – | – | | 97 | — | — | — | — | — | — | — | | 98 | ◊ | ◊ | ˜ | ◊ | ˜ | ◊ | ˜ | | 99 | ™ | ™ | ™ | ™ | ™ | ™ | ™ | | 9A | š | љ | š | ◊ | š | ◊ | ◊ | | 9B | › | › | › | › | › | › | › | | 9C | ś | њ | œ | ◊ | œ | ◊ | œ | | 9D | ť | ќ | ◊ | ◊ | ◊ | ¯ | ◊ | | 9E | ž | ћ | ž | ◊ | ◊ | ˛ | ◊ | | 9F | ź | џ | Ÿ | ◊ | Ÿ | ◊ | Ÿ | •--------•---------•---------•---------•---------•---------•---------•---------• | A0 | | | | | | | | | A1 | ˇ | Ў | ¡ | ΅ | ¡ | ◊ | ¡ | | A2 | ˘ | ў | ¢ | Ά | ¢ | ¢ | ¢ | | A3 | Ł | Ј | £ | £ | £ | £ | £ | | A4 | ¤ | ¤ | ¤ | ¤ | ¤ | ¤ | ¤ | | A5 | Ą | Ґ | ¥ | ¥ | ¥ | ◊ | ¥ | | A6 | ¦ | ¦ | ¦ | ¦ | ¦ | ¦ | ¦ | | A7 | § | § | § | § | § | § | § | | A8 | ¨ | Ё | ¨ | ¨ | ¨ | Ø | ¨ | | A9 | © | © | © | © | © | © | © | | AA | Ş | Є | ª | ◊ | ª | Ŗ | ª | | AB | « | « | « | « | « | « | « | | AC | ¬ | ¬ | ¬ | ¬ | ¬ | ¬ | ¬ | | AD | | | | | | | | | AE | ® | ® | ® | ® | ® | ® | ® | | AF | Ż | Ї | ¯ | ― | ¯ | Æ | ¯ | | B0 | ° | ° | ° | ° | ° | ° | ° | | B1 | ± | ± | ± | ± | ± | ± | ± | | B2 | ˛ | І | ² | ² | ² | ² | ² | | B3 | ł | і | ³ | ³ | ³ | ³ | ³ | | B4 | ´ | ґ | ´ | ΄ | ´ | ´ | ´ | | B5 | µ | µ | µ | µ | µ | µ | µ | | B6 | ¶ | ¶ | ¶ | ¶ | ¶ | ¶ | ¶ | | B7 | · | · | · | · | · | · | · | | B8 | ¸ | ё | ¸ | Έ | ¸ | ø | ¸ | | B9 | ą | № | ¹ | Ή | ¹ | ¹ | ¹ | | BA | ş | є | º | Ί | º | ŗ | º | | BB | » | » | » | » | » | » | » | | BC | Ľ | ј | ¼ | Ό | ¼ | ¼ | ¼ | | BD | ˝ | Ѕ | ½ | ½ | ½ | ½ | ½ | | BE | ľ | ѕ | ¾ | Ύ | ¾ | ¾ | ¾ | | BF | ż | ї | ¿ | Ώ | ¿ | æ | ¿ | •--------•---------•---------•---------•---------•---------•---------•---------• | C0 | Ŕ | А | À | ΐ | À | Ą | À | | C1 | Á | Б | Á | Α | Á | Į | Á | | C2 |  | В |  | Β |  | Ā |  | | C3 | Ă | Г | à | Γ | à | Ć | Ă | | C4 | Ä | Д | Ä | Δ | Ä | Ä | Ä | | C5 | Ĺ | Е | Å | Ε | Å | Å | Å | | C6 | Ć | Ж | Æ | Ζ | Æ | Ę | Æ | | C7 | Ç | З | Ç | Η | Ç | Ē | Ç | | C8 | Č | И | È | Θ | È | Č | È | | C9 | É | Й | É | Ι | É | É | É |ֹ | CA | Ę | К | Ê | Κ | Ê | Ź | Ê |ֺ | CB | Ë | Л | Ë | Λ | Ë | Ė | Ë | | CC | Ě | М | Ì | Μ | Ì | Ģ | ̀ | | CD | Í | Н | Í | Ν | Í | Ķ | Í | | CE | Î | О | Î | Ξ | Î | Ī | Î | | CF | Ď | П | Ï | Ο | Ï | Ļ | Ï | | D0 | Đ | Р | Ð | Π | Ğ | Š | Đ | | D1 | Ń | С | Ñ | Ρ | Ñ | Ń | Ñ | | D2 | Ň | Т | Ò | ◊ | Ò | Ņ | ̉ | | D3 | Ó | У | Ó | Σ | Ó | Ó | Ó | | D4 | Ô | Ф | Ô | Τ | Ô | Ō | Ô | | D5 | Ő | Х | Õ | Υ | Õ | Õ | Ơ | | D6 | Ö | Ц | Ö | Φ | Ö | Ö | Ö | | D7 | × | Ч | × | Χ | × | × | × | | D8 | Ř | Ш | Ø | Ψ | Ø | Ų | Ø | | D9 | Ů | Щ | Ù | Ω | Ù | Ł | Ù | | DA | Ú | Ъ | Ú | Ϊ | Ú | Ś | Ú | | DB | Ű | Ы | Û | Ϋ | Û | Ū | Û | | DC | Ü | Ь | Ü | ά | Ü | Ü | Ü | | DD | Ý | Э | Ý | έ | İ | Ż | Ư | | DE | Ţ | Ю | Þ | ή | Ş | Ž | ̃ | | DF | ß | Я | ß | ί | ß | ß | ß | •--------•---------•---------•---------•---------•---------•---------•---------• | E0 | ŕ | а | à | ΰ | à | ą | à | | E1 | á | б | á | α | á | į | á | | E2 | â | в | â | β | â | ā | â | | E3 | ă | г | ã | γ | ã | ć | ă | | E4 | ä | д | ä | δ | ä | ä | ä | | E5 | ĺ | е | å | ε | å | å | å | | E6 | ć | ж | æ | ζ | æ | ę | æ | | E7 | ç | з | ç | η | ç | ē | ç | | E8 | č | и | è | θ | è | č | è | | E9 | é | й | é | ι | é | é | é | | EA | ę | к | ê | κ | ê | ź | ê | | EB | ë | л | ë | λ | ë | ė | ë | | EC | ě | м | ì | μ | ì | ģ | ́ | | ED | í | н | í | ν | í | ķ | í | | EE | î | о | î | ξ | î | ī | î | | EF | ď | п | ï | ο | ï | ļ | ï | | F0 | đ | р | ð | π | ğ | š | đ | | F1 | ń | с | ñ | ρ | ñ | ń | ñ | | F2 | ň | т | ò | ς | ò | ņ | ̣ | | F3 | ó | у | ó | σ | ó | ó | ó | | F4 | ô | ф | ô | τ | ô | ō | ô | | F5 | ő | х | õ | υ | õ | õ | ơ | | F6 | ö | ц | ö | φ | ö | ö | ö | | F7 | ÷ | ч | ÷ | χ | ÷ | ÷ | ÷ | | F8 | ř | ш | ø | ψ | ø | ų | ø | | F9 | ů | щ | ù | ω | ù | ł | ù | | FA | ú | ъ | ú | ϊ | ú | ś | ú | | FB | ű | ы | û | ϋ | û | ū | û | | FC | ü | ь | ü | ό | ü | ü | ü | | FD | ý | э | ý | ύ | ı | ż | ư | | FE | ţ | ю | þ | ώ | ş | ž | ₫ | | FF | ˙ | я | ÿ | ◊ | ÿ | ˙ | ÿ | •--------•---------•---------•---------•---------•---------•---------•---------•Note that, in this table, the
◊character means that the character is not defined for the corresponding encoding !
-
Open a new N++ tab (
Ctrl + N) -
Run the command
Encoding > Convert to UTF-8-BOM( IMPORTANT ) -
Paste the clipboard contents in that new tab (
Ctrl + V) -
Save this file as
Windows_European_Encodings.txt -
From the first word, not correctly displayed of your
ANSIfile (le¿yin @nightznero’s text ), select the wrong character (¿) -
Open the Find dialog (
Ctrl + F) -
Tick the
March caseand theWrap aroundoptions -
Select the
Normalsearch mode -
Switch back to the
Windows_European_Encodings.txtfile, that we just created -
Click on the
Find Nextbutton
=> The caret should be on the line :
| BF | ż | ї | ¿ | Ώ | ¿ | æ | ¿ |Necessarily, your correct character, instead of the
¿char, must be found within that line !And @nightznero would have easily detected that the right character was
ż, forming the wordleży! Now, as theżbelongs to theWindows-1250encoding :- Select the command
Encoding > Character Sets > Central European > Windows-1250
=> All the text seems, now, completely readable ;-))
-
So, encode this file with the
UTF-8encoding, running one of these two commands :-
Encoding > Convert to UTF-8 -
Encoding > Convert to UTF-8-BOM
-
-
Save the changed contents (
Ctrl + S)
Note that we could have searched for other characters, listed below, which are accentuated characters from @nightznero’s text :
•--------•---------• •---------• | Code | Win1252 | | Win1250 | •--------•---------• •---------• | 8C | Œ | | Ś | | 9C | œ | | ś | | 9F | Ÿ | | ź | | A3 | £ | | Ł | | A5 | ¥ | | Ą | | AF | ¯ | | Ż | | B3 | ³ | => | ł | | B9 | ¹ | | ą | | BF | ¿ | | ż | | C6 | Æ | | Ć | | E6 | æ | | ć | | EA | ê | | ę | | F1 | ñ | | ń | •--------•---------• •---------•BTW, I found out a character which is different in all the different
Windows-125#Windows encodings. This is theANSIchar\x{de}. To write it, simply hold down theAltkey and hit, successively, the keys0,2,2and2, from the numeric keypad !•--------•--------------•--------------•--------------•--------------•--------------•--------------•--------------•--------------•--------------• | Code | Win-1250 | Win-1251 | Win-1252 | Win-1253 | Win-1254 | Win-1257 | Win-1258 | Win-1255 | Win-1256 | | ALT •--------------•--------------•--------------•--------------•--------------•--------------•--------------•--------------•--------------• | + 0222 | Centr. Eur. | Cyrillic | West. Eur. | Greek | Turkish | Baltic | Vietnamese | Hebrew | Arabic | •--------•--------------•--------------•--------------•--------------•--------------•--------------•--------------•--------------•--------------• | DE | Ţ | Ю | Þ | ή | Ş | Ž | ̃ | Undefined | ق | •--------•--------------•--------------•--------------•--------------•--------------•--------------•--------------•--------------•--------------•So, for instance, if you type the
\x{de}character, in anANSIencoded file :-
If the character displayed is
ή, this means that your currentANSIcodepage is probablyWin-1253 -
If the character displayed is
Ţ, this means that your currentANSIcodepage must beWin-1250
Just run the command
? > Debug Info...to verify !
To end with, from this link, you should be convinced to always manage
UTF-8encoded files ! ( ~96,7 %of all files coded in Websites ! )You may also click, to the left part, on the yearly list, which perfectly shows the growth of the
UTF-8encoding and the decrease of all other encodings, during these last ten years !Now, to get the contents of the Windows encodings, as text files, click on : https://www.unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS
Best Regards,
guy038
-
For polish he should use ISO 8859-2 (Eastern European), but nowadays I would rather recommend UTF-8.
@nightznero To twoja twórczość?
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login