Regex: Select the text between certain words, only from the file that contains a certain word
-
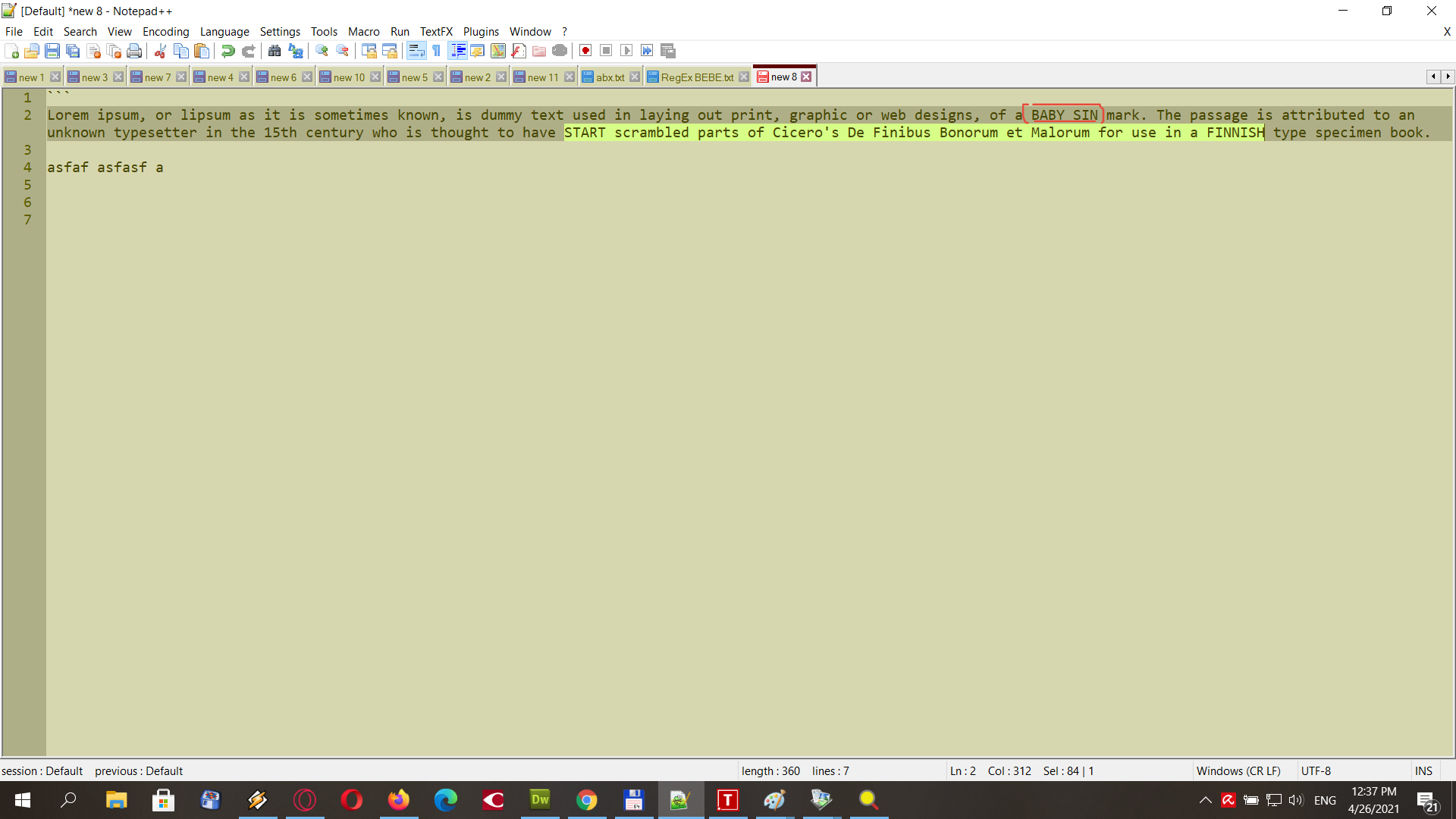
hello, this is what I want to select, only if the file contains the words BABY SIN
-
Hi , @robin-cruise,
Ah… OK. So, when you said :
I have to select SOME text between words start and finnish
you wanted to express :
I would like to select ALL text between the two words
STARTandFININSHI agree that the nuance is subtle ;-))
Now, from your picture, I see that, apparently, you also want to match the two delimiters
STARTandFINNISH, themselves-
However, you didn’t answer me about the possible locations of the
BABY SINstring ( inside, .outside theSTART•••••••••••FINNISHsection or before / after it ). -
Also, does your
HTMLtext contain only ONE or severalSTART•••••••••••FINNISHsections ?
BR
guy038
-
-
oh, yes.
Baby Sincan be located anywhere in the file. And my html contain only oneSTART•••••••••••FINNISHsection.(but as an alternative, it may be the case that I have 2
START•••••••••••FINNISHsections and I should select the first one, or other case the last one. -
Hello, @Robin-cruise and All,
The general problem is that the regex engine always searches from the left to the right. So, one the
BABY SINlocation is over, there no means for the regex engine to remember that current file contains that specific string :-((
Or course, there’s a simple solution, used many times in regex topics ! Before speaking about it, in the second part of this post, I also considered the possibility to catch the
BABY SINstring with this kind of regex :(?s-i)(?=\A.*?(BABY SIN))(*F)|(?(1).*?\KSTART.+?FINNISH)So, when the regex engine is right before the first char of current file :
-
The regex engine tests the first alternative
(?s-i)(?=\A.*?(BABY SIN))(*F)and match an empty string if the stringBABY SINexists. So, now, the group1is defined asBABY SIN. Note that, at the end, the control verb(*F)cancels the current alternative but, luckily, does not reset the group1 -
So, due to the
(*F)syntax, the regex engine switches to the next alternative(?(1).*?\KSTART.+?FINNISH)which is a conditional expression that is true ONLY IF group1exists. So, still from the very beginning of file, it looks for minimum stuff (.*?), forgotten because of the\Ksyntax, and, finally, looks for and finds the firstSTART•••••••••FINNISHsection. Nice ! -
However, let’s imagine that the current file contain a second
START•••••FINNISHsection. So, the regex engine goes on processing the overall regex :-
Current position is obviously not at the very beginning of file, so the first alternative cannot match and the group
1is not defined. Moreover, this first alternative is canceled due to the(*F)syntax -
Thus the second alternative
(?(1).*?\KSTART.+?FINNISH)is processed. Note that this regex is equivalent to the regex(?(1).*?\KSTART.+?FINNISH|)with an empty ELSE part. As the group1is not defined, this empty ELSE part simply matches an empty string at the location right after theFINNISHword and in all the subsequent locations till the end of file !
-
This is absolutely not what is expected ! Unfortunately, and unlike programs and scripts, the regex groups and subroutines calls cannot be stored over two consecutive search processes !
Thus, the sole practical and easy solution is to place an specific indicator at the very end of current document, which can be noticed with an look-ahead, and, for instance, the syntax
(?=.*indicator\z)As you deal with
HTML, I suppose that a comment after the last</html>tag, is allowed by the language ?So, we could change the last line
</html>into the line</html><!-- Y -->with this regex S/RSEARCH
(?s-i)\A.*BABY SIN.*</html>\KREPLACE
<!-- Y -->Note that changing, LATER, the
Yletter ( Yes ) to theNletter or anything else, in anHTMLfile, would not trigger the search of aSTART•••••FINNISHsection for this specific file and vice-versa !
Now, the search of a particular
START•••••FINNISHsection is rather easy ! To search for :-
The first
START•••••FINNISHsection, use the regex(?s-i)\A.*?\KSTART.+?FINNISH(?=.*<!-- Y -->\Z) -
The last
START•••••FINNISHsection, use the regex(?s-i)\A.*\KSTART.+?FINNISH(?=.*<!-- Y -->\Z) -
The subsequent
START•••••FINNISHsections, use the regex(?s-i).*?\KSTART.+?FINNISH(?=.*<!-- Y -->\Z)
Remember to move the caret at the very beginning of current file, in case of an individual search with a click on the
Find Nextbutton !Best regards,
guy038
-
-
ok, I don’t quite understand the last part from the last 3 regex, more special this
<!-- Y -->(?s-i)\A.*?\KSTART.+?FINNISH(?=.*<!-- Y -->\Z)(?s-i)\A.*\KSTART.+?FINNISH(?=.*<!-- Y -->\Z)(?s-i).*?\KSTART.+?FINNISH(?=.*<!-- Y -->\Z)In my case, in this last 3 example, where should I place the words
BABY SIN?something like this, will work:
(?s-i)(?=\A.*?(BABY SIN))(*F)|(?s-i)\A.*?\KSTART.+?FINNISH -
Hi @robin-cruise,
But, if you remove totally any
BABY SINkeyword from your file, your last regex, derived from my own attempt, still findsSTART.....FINNISHsections ! Not what it is expected, isn’t it ?Moreover, even if your file contains a
BABY SINstring, your last regex would find the firstSTART.....FINNISHsection, only, and not the subsequent ones, in case of several sections !
I’m trying to rephrase my last post ! See you later
BR
guy038
guy038
-
SELECT ALL INSTANCES:
(?s-i)(?=\A.*?(BABY SIN))(*F)|(?s-i).*?\KSTART.+?FINNISHSELECT FIRST INSTANCE:
(?s-i)(?=\A.*?(BABY SIN))(*F)|(?s-i)\A.*\KSTART.+?FINNISHSELECT LAST INSTANCE:
(?s-i)(?=\A.*?(BABY SIN))(*F)|(?s-i)\A.*\KSTART.+?FINNISHthanks, @guy038
-
Hi, @robin-cruise,
I regret, but these three provided regexes do not give you initial goal which was to find
START..... FINNISHsections ONLY IF the stringBABY SINis found anywhere in current file !In addition, your second and third regexes seem identical !?
So, just wait for my next reply !
BR
guy038
-
Hello, @robin-cruise and All,
Robin, as you want to search for
START•••••FINNISHsection(s) in someHTMLfiles but ONLY IF current file contains the stringBABY SIN, and taking into account the limitations, outlined at the very beginning of my previous post :https://community.notepad-plus-plus.org/post/65328
My goal, that I slightly improved, is then :
FIRST step :
-
To add the
<!-- Y -->comment at the very end of anyHTMLfile which contains, at least, one stringBABY SIN -
To add the
<!-- N -->comment at the very end of anyHTMLfile which does not contain any stringBABY SIN -
So, open either :
-
The
Find in filesdialog, if you need to search theSTART•••••FINNISHsection(s) in severalHTMLfiles -
The
Replacedialog, if you need to search theSTART•••••FINNISHsection(s) in a singleHTMLfile
-
-
SEARCH
(?s-i)\A(?:.*(BABY SIN)|).*</html>(?!<)\K -
REPLACE
?1<!-- Y -->:<!-- N --> -
Select
*.htmlin theFilterszone, if necessary -
Tick the
Wrap aroundoption -
Click on the
Replace AllorReplace in Filesbutton
Now, after this first step, you should have :
-
Some
HTMLfiles with en ending comment<!-- Y -->( Those which contain aBABY SINstring ) -
Some
HTMLfiles with en ending comment<!-- N -->( Those which do not contain anyBABY SINstring )
SECOND step :
Now, thanks to that ending comment added, after the
</html>tag, we can easily search for :-
The first
START•••••FINNISHregion, of currentHTMLfile, if aBABY SINstring exists in current file :(?s-i)\A.*?\KSTART.+?FINNISH(?=.*<!-- Y -->\Z)
-
The last
START•••••FINNISHregion, of currentHTMLfile, if aBABY SINstring exists in current file :(?s-i)\A.*\KSTART.+?FINNISH(?=.*<!-- Y -->\Z)
-
Any
START•••••FINNISHregion, in currentHTMLfile, if aBABY SINstring exists in current file :(?s-i).*?\KSTART.+?FINNISH(?=.*<!-- Y -->\Z)
And :
-
The first
START•••••FINNISHregion, of currentHTMLfile, if noBABY SINstring exists in current file :(?s-i)\A.*?\KSTART.+?FINNISH(?=.*<!-- N -->\Z)
-
The last
START•••••FINNISHregion, of currentHTMLfile, if noBABY SINstring exists in current file :(?s-i)\A.*\KSTART.+?FINNISH(?=.*<!-- N -->\Z)
-
Any
START•••••FINNISHregion, in currentHTMLfile, if noBABY SINstring exists in current file :(?s-i).*?\KSTART.+?FINNISH(?=.*<!-- N -->\Z)
Best Regards,
guy038
-
-
super answer, thank you sir @guy038