Regex: Delete everything that falls between the html comments except some tags
-
Hello, I have this html lines that starts with
<!-- MAIN START -->and ending with<!-- MAIN FINAL --><!-- MAIN START --> <div align="center"> <table width="33" border="0"> <tr> <td> <h1 class="tre" itemprop="sfe">Text here</h1> </td> </tr> <tr> <td class="rest">Something, by Author</td> </tr> </table> <h2 class="blast2"><img src="sfa.jpg" alt="hip" /> <map name="goon" id="m2_34"> <p class="my_2">I love myself</p> <area shape="rect" coords="45,74,582" href="#plata" alt="" /> </map> </h2> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> </div> <p align="justify" class="justify_em">Yes</p> <!-- MAIN FINAL -->I want to remove everything from these comments, and keep only the html tags such as
<p class=...</p>The Output should be"
<!-- MAIN START --> <p class="my_2">I love myself</p> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> <!-- MAIN FINAL -->My regex is not working:
Find:
(<\!-- MAIN START -->).*(?!<p class=.*</p>).*(<\!-- MAIN FINAL -->)Replace by:
\1\2\3 -
I don’t know if it’s possible with Regex and Notepad++, but it’s definitely possible with PoweShell:
$sourcedir = "C:\Folder1\" $resultsdir = "C:\Folder2\" Get-ChildItem -Path $sourcedir -Filter *.html | ForEach-Object{ $output=@() $content = Get-Content -Path $_.FullName $start = $content | Where-Object {$_ -match '<!-- MAIN START -->'} $final = $content | Where-Object {$_ -match '<!-- MAIN FINAL -->'} for($i=0;$i -lt $content.Count;$i++){ if(($i -gt $content.IndexOf($start)) -and ($i -lt $content.IndexOf($final))){ if($content[$i] -notmatch '<p class='){ continue } } $output += $content[$i] } $output | Out-File -FilePath $resultsdir\$($_.name) } -
Our regex guru @guy038 has provided a “generic regex” in this post which provides a generic way of finding specific text (FR) and replacing it with specific text (RR), but only when found between a start-of-region and end-of-region pair (BSR and ESR).

You would have to figure out the FR, RR, BSR, and ESR, and then plug those values into the generic expression…
The find expression will be the hardest, because you want to find any text that isn’t an HTML paragraph. I don’t immediately have an idea of how to do that for sure… The others are pretty straightforward:
- FR = … unsure yet … it’s going to involve lookaheads
- RR = since you want to replace the found text with nothing, you can just leave this blank
- BSR =
<!-- MAIN START --> - ESR =
<!-- MAIN FINAL -->
My initial guess was that the FR was going to be something like
((?!<p.*?</p>).)+… unfortunately, that exact sequence won’t work because when it advances one step beyond the<of the<p..., it is matching again:
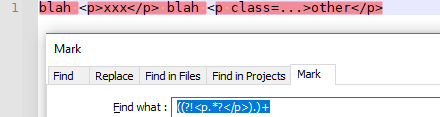
My next guess is that the generic would have to be modified somewhat, probably adding an or-condition next to the ESR… but I’m not sure how. Maybe @guy038 will be able to find time to experiment with this one.
Alternately, it would be pretty easy in some tool other than pure Notepad++. @Vasile-Caraus has provided an off-topic powershell answer. If you wanted to stick closer to Notepad++, you could use one of the scripting plugins like PythonScript to access the file currently open in Notepad++ with your script, but implement the start and end checks similar to what @Vasile-Caraus did, but in Python and using the PythonScript interface to access the contents of the document open in Notepad++.
-
thank you @Vasile-Caraus Works very well with powershell, but it would have been faster and easier with regex
-
Hello, @hellena-crainicu and All,
Before giving, in the second part of this post, the specific solution for @hellena-crainicu, here is a simple example to show you the difficulties I had to face !
Let’s start with this text :
---000000---DEF--- START---12345---6789---1111199999---DEF---STOP ---GHI---000 00000--- START---123---PQR---456---789STOP ---00000000---00---GHI---0000--- START987---AAA---654 ---ZZZ---321---STOP ---0000---000000000And let’s suppose that we want to rewrite all numbers, between the boundaries
STARTandSTOP, each on a new lineIf, in addition, we want to add a line-break, after the
STARTopening section, we need, from the generic regex, discussed before by @peterjones, to slightly modify this regex, as we search for two independent strings, simultaneously. It leads to the regex S/R :(A) SEARCH (?sx-i)(?: (START) | (?!\A)\G ) (?: (?!STOP). )*? (\d+ (\R)? ) (A) REPLACE (?1\1\r\n\r\n)\2(?3:\r\n)and would change the initial text as :
---000000---DEF--- START 12345 6789 1111199999 ---DEF---STOP ---GHI---000 00000--- START 123 456 789 STOP ---00000000---00---GHI---0000--- START 987 654 321 ---STOP ---0000---000000000As you can see :
-
The
STARTboundary is clearly defined -
The different numbers, located between
STARTandSTOPare correctly rewritten one per line and extra stuff is deleted -
However, between the last number and the closing boundary
STOP, some extra characters are still not deleted :-(
No problem, we may modify this S/R to include the search of
STOP, too, within a non-capturing group, giving :(B) SEARCH (?sx-i)(?: (START) | (?!\A)\G ) (?: (?!STOP). )*? (?: ( \d+ (\R)? ) | (STOP) ) (B) REPLACE (?1\1\r\n\r\n)(?2\2(?3:\r\n))(?4\r\n\4)And we will take the opportunity to add a line-break, right before the closing section
STOPThus, we obtain :
---000000---DEF--- START 12345 6789 1111199999 STOP000 00000 123 456 789 STOP00000000 00 0000 987 654 321 STOP0000 000000000Unfortunately, it seems that the
0digits are also processed like the other numbers, although they are not part of aSTART •••••STOPregion :-((Indeed, after matching some stuff ending with
STOP, the search process restarts immediately and considers the following characters as we have specified the(?s)modifier ! So, how to tell the regex engine, to directly jump to the nextSTARTboundary ?I had the idea to only search for the beginning of the
STOPstring, for instance the stringSTand add a negative look-behind(?!OP), executed once only, after theSTARTstring or location of the previous matchSo :
-
First, extra chars before
STOPas well asSTare changed as the string\r\nST -
Now, the regex engine is located right before the
OPstring of the wordSTOP. However, due to the look-ahead(?!OP), it must advance of one position in order that the condition(?!OP)is true. As this new match do not start where the previous match ends, the\Gassertion forces the failure of the match attempt ! -
Thus, the string
OPand further stuff should not be modified and the new match would necessarily catch an other stringSTART, so the beginning of an other allowed region !
(C) SEARCH (?sx-i)(?: (START) | (?!\A)\G ) (?!OP) (?: (?!STOP). )*? (?: ( \d+ (\R)? ) | (ST) ) (C) REPLACE (?1\1\r\n\r\n)(?2\2(?3:\r\n))(?4\r\n\4)After replacement, we get :
---000000---DEF--- START 12345 6789 1111199999 STOP ---GHI---000 00000--- START 123 456 789 STOP ---00000000---00---GHI---0000--- START 987 654 321 STOP ---0000---000000000This time, it easy to see that the parts of text :
-
Before the first
STARTboundary -
After a
STOPboundary and before aSTARTboundary -
After the last
STOPboundary
Are not modified at all by the replacement, as expected !
Now, @hellena-crainicu, as promised, here is the regex S/R to achieve what you want :
SEARCH
(?s)(?:^\h*(<!-- MAIN START -->)(?:\h*\R)+|(?!\A)\G)(?!->)(?:(?!<!-- MAIN FINAL -->).)*?(?:^\h*(<p class=".+?</p>(\R)?)|^(?:\h*\R)*\h*(<!-- MAIN FINAL -))REPLACE
(?1\1\r\n\r\n)\2(?3:\r\n)\4You may test it against this sample text, below, containing two sections
<!-- MAIN START --> ••••• <!-- MAIN FINAL -->, embedded into three other sections !<div align="center"> <table width="33" border="0"> <tr> <td> <h1 class="tre" itemprop="sfe">Text here</h1> </td> </tr> <tr> <td class="rest">Something, by Author</td> </tr> </table> <h2 class="blast2"><img src="sfa.jpg" alt="hip" /> <map name="goon" id="m2_34"> <p class="my_2">I love myself</p> <area shape="rect" coords="45,74,582" href="#plata" alt="" /> </map> </h2> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> </div> <p align="justify" class="justify_em">Yes</p> <!-- MAIN START --> <div align="center"> <table width="33" border="0"> <tr> <td> <h1 class="tre" itemprop="sfe">Text here</h1> </td> </tr> <tr> <td class="rest">Something, by Author</td> </tr> </table> <h2 class="blast2"><img src="sfa.jpg" alt="hip" /> <map name="goon" id="m2_34"> <p class="my_2">I love myself</p> <area shape="rect" coords="45,74,582" href="#plata" alt="" /> </map> </h2> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> </div> <p align="justify" class="justify_em">Yes</p> <!-- MAIN FINAL --> <div align="center"> <table width="33" border="0"> <tr> <td> <h1 class="tre" itemprop="sfe">Text here</h1> </td> </tr> <tr> <td class="rest">Something, by Author</td> </tr> </table> <h2 class="blast2"><img src="sfa.jpg" alt="hip" /> <map name="goon" id="m2_34"> <p class="my_2">I love myself</p> <area shape="rect" coords="45,74,582" href="#plata" alt="" /> </map> </h2> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> </div> <p align="justify" class="justify_em">Yes</p> <!-- MAIN START --> <div align="center"> <table width="33" border="0"> <tr> <td> <h1 class="tre" itemprop="sfe">Text here</h1> </td> </tr> <tr> <td class="rest">Something, by Author</td> </tr> </table> <h2 class="blast2"><img src="sfa.jpg" alt="hip" /> <map name="goon" id="m2_34"> <p class="my_2">I love myself</p> <area shape="rect" coords="45,74,582" href="#plata" alt="" /> </map> </h2> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> </div> <p align="justify" class="justify_em">Yes</p> <!-- MAIN FINAL --> <div align="center"> <table width="33" border="0"> <tr> <td> <h1 class="tre" itemprop="sfe">Text here</h1> </td> </tr> <tr> <td class="rest">Something, by Author</td> </tr> </table> <h2 class="blast2"><img src="sfa.jpg" alt="hip" /> <map name="goon" id="m2_34"> <p class="my_2">I love myself</p> <area shape="rect" coords="45,74,582" href="#plata" alt="" /> </map> </h2> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> </div> <p align="justify" class="justify_em">Yes</p>You should get the expected text :
<div align="center"> <table width="33" border="0"> <tr> <td> <h1 class="tre" itemprop="sfe">Text here</h1> </td> </tr> <tr> <td class="rest">Something, by Author</td> </tr> </table> <h2 class="blast2"><img src="sfa.jpg" alt="hip" /> <map name="goon" id="m2_34"> <p class="my_2">I love myself</p> <area shape="rect" coords="45,74,582" href="#plata" alt="" /> </map> </h2> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> </div> <p align="justify" class="justify_em">Yes</p> <!-- MAIN START --> <p class="my_2">I love myself</p> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> <!-- MAIN FINAL --> <div align="center"> <table width="33" border="0"> <tr> <td> <h1 class="tre" itemprop="sfe">Text here</h1> </td> </tr> <tr> <td class="rest">Something, by Author</td> </tr> </table> <h2 class="blast2"><img src="sfa.jpg" alt="hip" /> <map name="goon" id="m2_34"> <p class="my_2">I love myself</p> <area shape="rect" coords="45,74,582" href="#plata" alt="" /> </map> </h2> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> </div> <p align="justify" class="justify_em">Yes</p> <!-- MAIN START --> <p class="my_2">I love myself</p> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> <!-- MAIN FINAL --> <div align="center"> <table width="33" border="0"> <tr> <td> <h1 class="tre" itemprop="sfe">Text here</h1> </td> </tr> <tr> <td class="rest">Something, by Author</td> </tr> </table> <h2 class="blast2"><img src="sfa.jpg" alt="hip" /> <map name="goon" id="m2_34"> <p class="my_2">I love myself</p> <area shape="rect" coords="45,74,582" href="#plata" alt="" /> </map> </h2> <p class="my_2">Why this text text?</p> <p class="my_3">test text text</p> <p class="my_2">test text text</p> <p class="my_3">test text text</p> </div> <p align="justify" class="justify_em">Yes</p>
Using the free-spacing mode, the search regex can be re-expressed as :
(?xs-i) # FREE-SPACING mode, regex DOT match ANY character and search is SENSITIVE to CASE (?: # START of the 1st NON-CAPTURING group ^\h* # Any LEADING BLANK characters, followed with ... (<!--[ ]MAIN[ ]START[ ]-->) # The string '<!-- MAIN START -->', STORED as group 1 (?:\h*\R)+ # And followed with BLANK or EMPTY lines, in a NON-CAPTURING group | # OR (?!\A)\G # The EMPTY location RIGHT AFTER a previous MATCH ) # END of the 1st NON-CAPTURING group (?!->) # If the TWO NEXT chars are DIFFERENT from the string '->' (?: # START of the 2nd NON-CAPTURING group (?!<!--[ ]MAIN[ ]FINAL[ ]-->). # If CURRENT character is NOT the BEGINNING of the string '<!-- MAIN FINAL -->' ) # END of the 2nd NON-CAPTURING group *? # The SHORTEST, possibly EMPTY, range of ANY character, till... : See •, below (?: # START of the 3rd NON-CAPTURING group ^\h* # • Any LEADING BLANK characters, followed with ... ( # START of group 2 <p[ ]class=".+?</p> # The SHORTEST, NON EMPTY, range of characters between the strings '<p class="' and '</p>' (\R)? # And followed with an OPTIONAL line-break, STORED as group 3 ) # END of group 2 | # OR ^(?:\h*\R)*\h* # • An OPTIONAL range of BLANK or EMPTY lines, followed with OPTIONAL HORIZONTAL BLANK chars (<!--[ ]MAIN[ ]FINAL[ ]-) # And followed with the string '<!-- MAIN FINAL -', STORED as group 4 ) # END of the 3rd NON-CAPTURING group
Notes :
-
In this mode, any literal space char must be escaped with the
\character or written[ ]! -
Following the same method, as previously described, we just search for the ending string
<!-- MAIN FINAL -and the last two chars->are inserted in the negative look-ahead(?!->)
Best Regards,
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login