Interrupted list
-
Hi to all!
I have a problem with matching regex strings. So, I tried but I still need help.I summarized my situation in four points below:
- a string like this to be matched:
Abc 2:5a; 24:51d, 53; 1:9b, 22-23c; 1:22-23, 9; 1:22-23, 24-25; - this string should not be matched if it is found at the start of a line, that is, a new row; only in the middle o at the end of a row.
- if in the middle or at the end of a string/row, it should match only if it starts with capital letter. E.g. Abc, not abc
- After matching the Replacing I need is like this:
Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23c; Abc 1:22-23, 9; Abc 1:22-23, 24-25;
This what I tried, but it is not good enough: ((((\d)?\w*(.)?\s\d*:\d*)((-|:|,)?\s)?)(((-)?|(\d*))?(,)?(\s)?){5})
Thank you for any help.
Dumitru. - a string like this to be matched:
-
Hello, @dumitru-s and All,
I think it would be good to use two successive steps :
1) Identify the lines where a replacement must occur ( String beginning with an upper-case letter followed with some lower-case letters, not at the very start of current line and followed with a space and some digit characters
2) Replace any
;character with the same;, followed with a space char and the first word beginning the line, after the leading space characters
-
First, I advice you to backup the file(s), involved in the future replacements ;-))
-
Then, use this first regex S/R, which re- copies the key-word at the very end of curent line after the last
;character-
SEARCH
(?-is)(?!^)(\u\l+)(?=\x20\d+).+ -
REPLACE
$0\1
-
Just tell me if this regex seems to be not restrictive enough and matches something else, which is unwanted !
-
Now, if this first step is OK, use this second regex S/R, below, which :
-
Adds, after any ; char, except the last one, on the appropriate lines, a space char and the first word, beginning the line after the leading space chars
-
Deletes the temporary first word, located after the last
;character-
SEARCH
(?-is);(?=.+;(\u\l+)$)|\u\l+$ -
REPLACE
?1;\x20\1
-
-
If OK, I could give you some explanations on these regex S/R, next time !
Best Regards,
guy038
-
-
Yes. Both steps work very well, and it was just as you said. Also, the first regex is indeed not restrictive enough – if there is another word or another sentence after that, this regex captures it all all the way until CR/LF that mark the end of the paragraph.
Thank you! -
@Dumitru-S ,
You’ll notice that @guy038 had to make guesses, and wasn’t able to guess right. Do you know why this is? Because you gave one line of text which should match, and that was it. The regex you had tried helped give insight into your difficulty – so thank you for sharing that – but that’s not enough.
Read and take to heart the advice below. It will get you better answers in the future. The better you describe what you have and what you want (with good examples), the better our answers will be.
-—
Do you want regex search/replace help? Then please be patient and polite, show some effort, and be willing to learn; answer questions and requests for clarification that are made of you. All example text should be marked as literal text using the
</>toolbar button or manual Markdown syntax. To makeregex in red(and so they keep their special characters like *), use backticks, like`^.*?blah.*?\z`. Screenshots can be pasted from the clipboard to your post usingCtrl+Vto show graphical items, but any text should be included as literal text in your post so we can easily copy/paste your data. Show the data you have and the text you want to get from that data; include examples of things that should match and be transformed, and things that don’t match and should be left alone; show edge cases and make sure you examples are as varied as your real data. Show the regex you already tried, and why you thought it should work; tell us what’s wrong with what you do get. Read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. If you follow these guidelines, you’re much more likely to get helpful replies that solve your problem in the shortest number of tries. -
You are right. I did not realized I was not very accurate. Thank you for your honest comment.
By the way, I downloaded some books that I found checking out your link Regular Expression FAQ. I already started to learn from the sites provided by you, but I would really like to know it better. So, thank you.
-
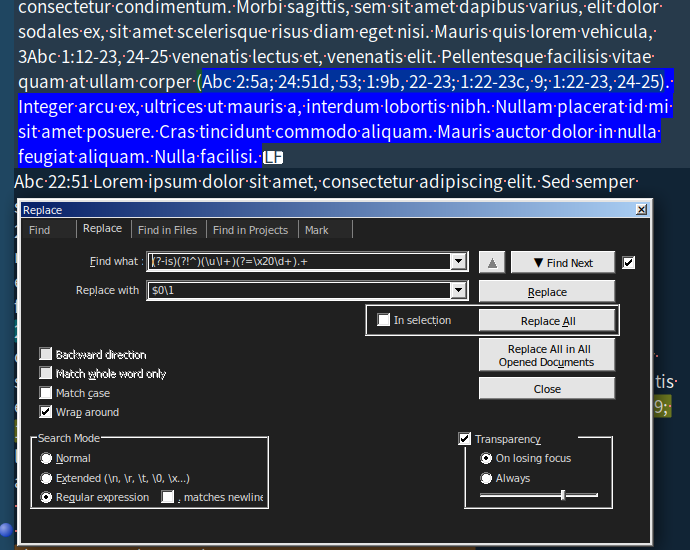
As shown in the picture below, what I need is to find this:
Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25;
(Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25)
(3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25)
3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25; -
and to be replaced with this:
Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25;
(Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25)
(3Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25)
3Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25;

- As @guy038 said both steps work very well, and it was just as he said. Also, the first regex is indeed not restrictive enough. As an example, you can see how it goes all the way to the end of the paragraph, as shown in the picture below:
I hope this time I was much more accurate, and that I do show that I am willing to learn.
Have a good day!
Thank you! -
-
Hi, @dumitru-s, @peterjones and All,
OK ! So, the way to achieve your problem has not changed : once the strings are well identified, with an appropriate search regex, we re-copy the key string (
Abc), right after each string.However, as we cannot rely on the end of line location, we must locate this key string, in a unique way. I chose the temporary sequence
@Abc@
So, starting with this text, ( manually ! ) extracted from your picture :
fermentum (Abc 22:51). Mauris fringilla et massa (3Ab 24:51, 53; 3Ab 24:51,53) eget congue frigilla, Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25; malesuada nisi a turpis Abc 1:9, 22-23; 3Ab 1:22-23, 9 efficitur. lorem vehicula, 3Abc 1:12-23, 24-25 venelactis lectus at ullamcorper (Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25). Integer arcu Abc 22:51 Lorem ipsum fermentum (Abc 22:51). Mauris fringilla et massa (3Ab 24:51, 53; 3Ab 24:51,53) eget congue a turpis (3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25). Praesent consectetur vitae quam 3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25; at ullamcorper.I’ll express the regexes with the free-spacing mode, for a better readability. In this mode, any space char is not part of the regex ( Use
\x20or escape the space char with\, to search for a space char ! )However, note that this mode is not available for the replacement regex !
So, this first regex S/R :
-
Looks for the correct strings needing modifications
-
Inserts the key word
Abc, surrounded by@chars, at the end of each string :
SEARCH
(?x-i) (?<=\x20) \(? (\d+)? ( \u\l+ ) ( \x20 \d+ : \d+ \l? (- \d+ \l? )? ( ,\x20 \d+ (- \d+)? )? [;)] ) {2,}REPLACE
$0@\2@and gives this changed text :
fermentum (Abc 22:51). Mauris fringilla et massa (3Ab 24:51, 53; 3Ab 24:51,53) eget congue frigilla, Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25;@Abc@ malesuada nisi a turpis Abc 1:9, 22-23; 3Ab 1:22-23, 9 efficitur. lorem vehicula, 3Abc 1:12-23, 24-25 venelactis lectus at ullamcorper (Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25)@Abc@. Integer arcu Abc 22:51 Lorem ipsum fermentum (Abc 22:51). Mauris fringilla et massa (3Ab 24:51, 53; 3Ab 24:51,53) eget congue a turpis (3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25)@Abc@. Praesent consectetur vitae quam 3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25;@Abc@ at ullamcorper.You probably noticed that some parts like :
-
(3Ab 24:51, 53; 3Ab 24:51,53), already in its final state -
Abc 22:51, beginning the line -
3Abc 1:12-23, 24-25being a one -section string
are correctly ignored by the search regex !
Now, the second regex S/R :
-
Looks for any
;character, not at end of each expression, and replace it with a;char, followed with a space char and the key wordAbc -
And, at end of each string, deletes the temporary string
@Abc@
SEARCH
(?x-is) ; (?= .+ [;)] @ ( \u\l+ ) @ ) | @ .+? @REPLACE
?1;\x20\1Giving your expected text :
fermentum (Abc 22:51). Mauris fringilla et massa (3Ab 24:51, 53; 3Ab 24:51,53) eget congue frigilla, Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25; malesuada nisi a turpis Abc 1:9, 22-23; 3Ab 1:22-23, 9 efficitur. lorem vehicula, 3Abc 1:12-23, 24-25 venelactis lectus at ullamcorper (Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25). Integer arcu Abc 22:51 Lorem ipsum fermentum (Abc 22:51). Mauris fringilla et massa (3Ab 24:51, 53; 3Ab 24:51,53) eget congue a turpis (3Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25). Praesent consectetur vitae quam 3Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25; at ullamcorper.
As usual, tick, preferably, the
Wrap aroundoption and select theRegular expressionsearch modeNote also that the key-words can be different for each string (
Abc,Abcdef,3Ztest,456Test, … )Best Regards,
guy038
-
-
@guy038 said in Interrupted list:
REPLACE $0@\2@
Thank you @guy038!
I marveled when I saw that what you wrote really worked. They work as a charm and that goes to your credit and credibility. That is why I am coming back to simply point that out.- To resume, your two step regex worked nicely in two steps:
This 1st Step:
SEARCH: (?x-i) (?<=\x20) (? (\d+)? ( \u\l+ ) ( \x20 \d+ : \d+ \l? (- \d+ \l? )? ( ,\x20 \d+ (- \d+)? )? [;)] ) {2,}
REPLACE $0@\2@
made this text:
text before Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25;
text before (Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25)
text before (3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25)
text before 3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25;into this:
text before Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25;@Abc@
text before (Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25)@Abc@
text before (3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25)@Abc@
text before 3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25;@Abc@
And this 2d Step:
SEARCH: (?x-is) ; (?= .+ [;)] @ ( \u\l+ ) @ ) | @ .+? @
REPLACE: ?1;\x20\1made the (above produced) text:
text before Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25;@Abc@
text before (Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25)@Abc@
text before (3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25)@Abc@
text before 3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25;@Abc@into this:
text before Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25;
text before (Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25)
text before (3Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25)
text before 3Abc 2:5a; Abc 24:51d, 53; Abc 1:9b, 22-23; Abc 1:22-23c, 9; Abc 1:22-23, 24-25;- Thank you @guy038 for this real masterpiece!I could never have done that. I have to study more. I really like the accurate way you work, and this pushed me also to be more accurate. I have actually never thought that I am so sloppy until now. This makes me work more on my regex cases and when I have some more time to work on it I will just come back to you soon enough. So thank you for this and have a nice day today! I go back to study some more.
Dumitru.
- To resume, your two step regex worked nicely in two steps:
-
Hi @guy038 !
In a previous post you mentioned that you might give some explanation on these regex S/R. So, I would like to ask whether you would you like to help me understand what just happened especially with the following two sets of regex that you offered me:SEARCH:
(?x-i) (?<=\x20) (? (\d+)? ( \u\l+ ) ( \x20 \d+ : \d+ \l? (- \d+ \l? )? ( ,\x20 \d+ (- \d+)? )? [;)] ) {2,}
REPLACE$0@\2@SEARCH:
(?x-is) ; (?= .+ [;)] @ ( \u\l+ ) @ ) | @ .+? @
REPLACE:?1;\x20\1This explanation of the regex above would be a real help and a true progress for me personally.
Thank you! -
Hi @guy038 and all!
I went and I studied all that you did above and I understood everything except\x20. So, if you do not mind to explain what it stands for, that would be wonderful. Thank you! -
@Dumitru-S
\x20is another way of expressing a single space character.
It is often used in regular expression posts here because it is much easier to see than a space. -
@Alan-Kilborn said in Interrupted list:
\x20is another way of expressing a single space character.
It is often used in regular expression posts here because it is much easier to see than a space.@Dumitru-S ,
Further to what Alan said: because the FIND expression you are using includes the
(?x-i)and(?x-is)syntax, normal whitespace in the regular expression is used only for readability and will not match space characters; in order to match the space character in a(?x)expression, you have to encode the space – and, as Alan explained,\x20is one way to encode the space character: see the description of\xℕℕin the usermanual. -
Hello, @dumitru-s, @peterjones, @alan-kilborn and All,
Sorry for my very late reply ! Anyway, the good thing is that you studied some regex formulations, in between ;-)) Thanks to Alan and Peter, you have the explanation about the
\x20syntax. When using the redMarkdownmarking, I very often adopt this form, instead of a true space char, for the reason below :On our forum, multiples space characters are normally compressed to a simple one ! Indeed, create a new post start a reply to someone and type in
abc, then hit10times the space bar and type indef, as below :abc defIt corresponds to a regex, which, simply, looks for the string
abc, followed by10space characters and the stringdefAs you can see, in the preview panel, on the right side, we simply get the string
abc def. But, if I decide to use, instead, the regexabc\x20{10}def, no more ambiguity !The
\xNNor\x{NN}syntaxes, where eachNrepresents an single hexadecimal digit from0toFcan be used to search any character, with hexadecimal codeNN, in anANSIencoded fileIn order to find any Unicode char, of the
BMP( Basic multilingual Plane ), in an Unicode encoded file, use, preferably, the\x{NNNN}syntaxNow, if you really want to insert a text, containing multiple consecutive space chars, use for instance, this
Mardownsyntax :~~~z
Raw text here, with respect of SPACE chars~~~
Let’s go back to the regex explanations ! If we use the
ABNFsyntax ( Augmented Backus–Naur Form ) ( Refer here ) with the definitions :SP = %x20 ; SPACE char upper = %41-5A ; A-Z lower = %61-7A ; a-z digit = %30-39 ; 0-9 number = 1*digit ; From 1 to any numberAnd being aware of the general notations
[X Y ... Z]which means0*1(X Y ... Z)and(X/Y/...Z)which meansX OR Y OR .... OR ZYour expression
(3Abc 2:5a; 24:51d, 53; 1:9b, 22-23; 1:22-23c, 9; 1:22-23, 24-25), preceded by aspacechar, can be expressed as :SP ["("] [number] upper 1*lower 2*( SP number ":" number [lower] [ "-" number [lower] ] [ "," SP number [ "-" number ] ] ( ";" / ")" ) )leading to the search expression of the first regex S/R :
(?x-i) # FREE-SPACING mode / NON-INSENSITIVE to case (?<=\x20) # IF PRECEDED with a SPACE char, searches for ... \(? # an OPTIONAL OPENING parenthese followed with ... (\d+)? # an OPTIONAL GROUP 1 containing a NUMBER and ... ( \u\l+ ) # an UPPER-CASE letter, followed with some LOWER-CASE letters, stored as GROUP 2, which will be inserted, during REPLACEMENT, between TWO AROBAS chars ( # START of GROUP 3 \x20 \d+ : \d+ \l? # A SPACE char followed with a NUMBER, a COLON char, an other NUMBER and an OPTIONAL LOWER-CASE letter ( - \d+ \l? ) ? # An OPTIONAL GROUP 4, containing a DASH, followed with a NUMBER and aN OPTIONAL LOWER-CASE letter ( # START of an OPTIONAL GROUP 5, containing : , \x20 \d+ (- \d+)? # A COMMA followed with a SPACE char, then a NUMBER followed by an OPTIONAL GROUP 6, containing a DASH char followed with a NUMBER )? # END of the OPTIONAL GROUP 5 [;)] # Ending with, either, a SEMMICOLON char OR a CLOSING parenthese ) {2,} # End of GROUP 3, present, at LEAST, TWO timesIn replacement, we simply rewrite the overall match
$0, followed with the group 2,\2, between two@chars !
Now, regarding the second regex S/R, we must :
-
Add the string, located between two
@chars, after each;, but the last -
And, of course, delete the temporary string
@ ••••• @, added by the first S/R, above
leading to this search regex :
(?x-is) # FREE-SPACING mode / NON-INSENSITIVE to case / A DOT matches a SINGLE STANDARD character ONLY ; # Searches for a SEMICOLON char ... (?= # ONLY IF : .+ # followed with the GREATEST range of chars till ... [;)] # a LAST ; character OR a CLOSING parenthese @ # followed with an ARROBAS and ... ( \u\l+ ) # an UPPER-CASE letter and some LOWER-CASE letters, stored as GROUP 1 @ # and followed by a LAST ARROBAS char ) # END of the LOOK-AHEAD assertion | # OR @ .+? @ # searches an ARROBAS char, followed by the SMALLEST range of STANDARD characters, till ... a SECOND ARROBAS charIn replacement :
-
we use a conditional syntax
?1••••which means that the searched semicolon will be replaced by itself, followed with a space char\x20and the contents of group 1\1ONLY IF thegroup 1exists ( i.e. if the first alternative matched ! ) -
If the second alternative matches, as
group 1does not exist, the temporary string@•••••@is then deleted !
Best Regards,
guy038
-
-
Hi to all!
Thank you a lot for your very comprehensive response.
I appreciate it.Have a nice day today!
Best regards,
Dumitru
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login