Regex: Select and delete the content of tags from xml file with skiping other tags
-
Hello, I have this rss.xml file. I want to use regex to delete only those tags from <url> to </url> that contains a link like
https://my-website.com/stamina-art(number)<url> <loc>https://my-website.com/en/wild-one.html</loc> <lastmod>2018-11-30T17:19:37+00:00</lastmod> <changefreq>weekly</changefreq> <priority>0.6400</priority> </url> <url> <loc>https://my-website.com/stamina-art60/en/wild-two.html</loc> <lastmod>2018-11-30T17:19:37+00:00</lastmod> <changefreq>weekly</changefreq> <priority>0.6400</priority> </url> <url> <loc>https://my-website.com/stamina-art20/en/wild-three.html</loc> <lastmod>2018-11-30T17:19:37+00:00</lastmod> <changefreq>weekly</changefreq> <priority>0.6400</priority> </url> <url> <loc>https://my-website.com/en/wild-four.html</loc> <lastmod>2018-11-30T17:19:37+00:00</lastmod> <changefreq>weekly</changefreq> <priority>0.6400</priority> </url> <url> <loc>https://my-website.com/en/wild-five.html</loc> <lastmod>2018-11-30T17:19:37+00:00</lastmod> <changefreq>weekly</changefreq> <priority>0.6400</priority> </url>The Output should be:
<url> <loc>https://my-website.com/en/number-1.html</loc> <lastmod>2018-11-30T17:19:37+00:00</lastmod> <changefreq>weekly</changefreq> <priority>0.6400</priority> </url> <url> <loc>https://my-website.com/en/number-4.html</loc> <lastmod>2018-11-30T17:19:37+00:00</lastmod> <changefreq>weekly</changefreq> <priority>0.6400</priority> </url> <url> <loc>https://my-website.com/en/number-5.html</loc> <lastmod>2018-11-30T17:19:37+00:00</lastmod> <changefreq>weekly</changefreq> <priority>0.6400</priority> </url>I made a regex, but I don’t know why it selects/delete more than I want:
FIND:
(?:<url>).*?(?=https://my-website.com/stamina-art\d+).*?(html.*?</url>) -
@Robin-Cruise said in Regex: Select and delete the content of tags from xml file with skiping other tags:
I made a regex, but I don’t know why it selects/delete more than I want:
FIND: (?:<url>).?(?=https://my-website.com/stamina-art\d+).?(html.*?</url>)Actually, that regex doesn’t match any of your text.
Can you show us a real one that does match, and more than you intend? -
@Alan-Kilborn My regex match also the first
<url></url>(that I don’t want), but I forgot to mention the .matches newsline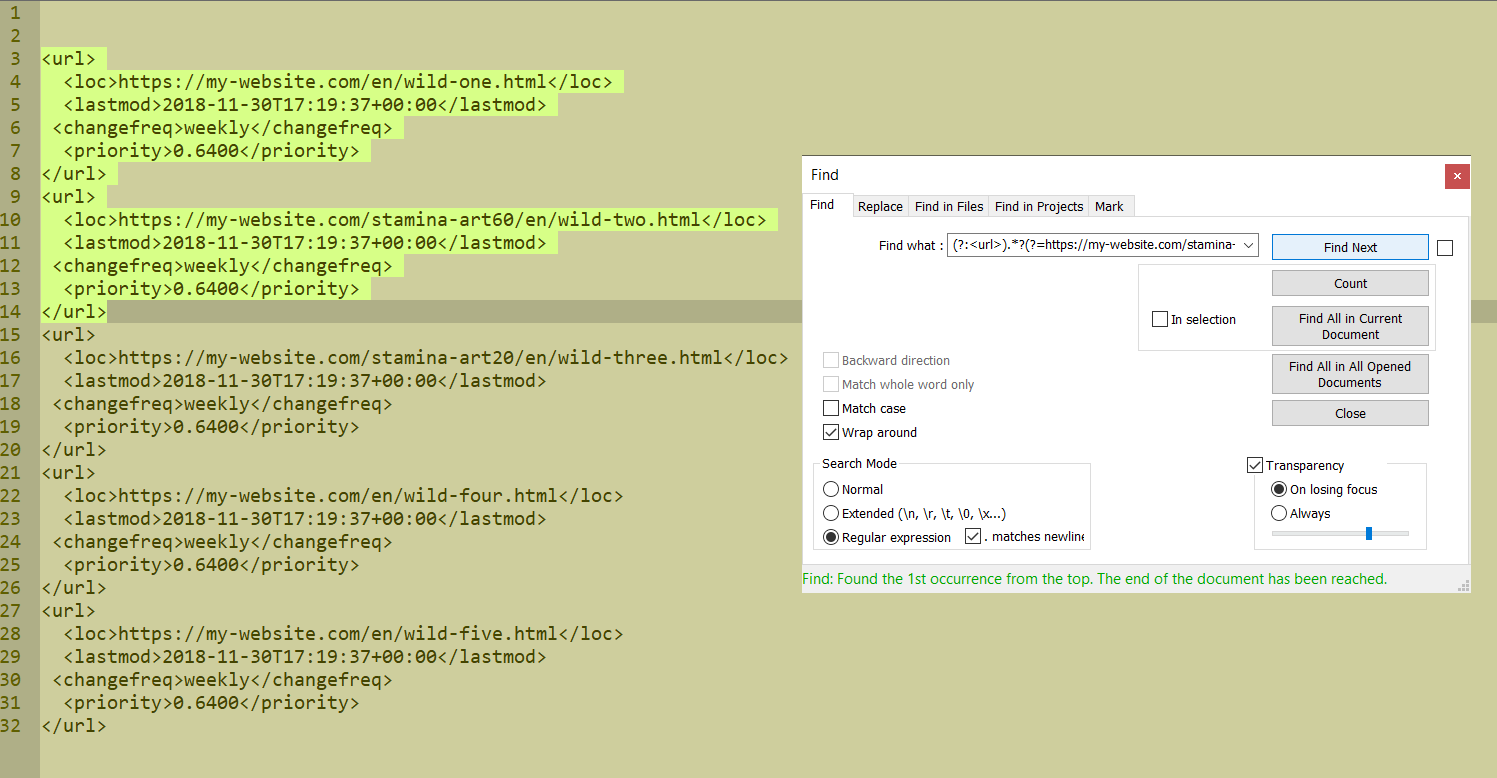
-
Hi, @robin-cruise, @alan-kilborn and All,
@Robin-cruise I going to show you the different steps to get the right regex S/R. Note that I’ll use the free-spacing mode
(?x)for a better readability !-
First, let’s start with the simple regex, below, which searches for an entire area
<url>•••••</url>:
(?xs-i) <url> .+? </url> \R- Note that we use the
(?s)modifier as we need to match a multi-lines area. We also use the(?-i)modifier to match</url>and, for instance, not</UrL>nor<URL>
- Note that we use the
-
Now, as we need to match an entire section
<url>•••••</url>ONLY IF it contains the string https://my-website.com/stamina-art followed with a number, the first idea is to use the usual regex :
(?xs-i) <url> .+? https://my-website.com/stamina-art\d+/ .+? </url> \R- Almost identical to your own try, it does not match as expected as, shown in your picture, because it matches the first two sections
<url>•••••</url>!. Indeed, logically, the first part of the regex ((?s-i)<url>.+?https://my-website.com/stamina-art\d+/) matches from the first string<url>found to the nearest stringhttps://my-website.com/stamina-art\d+/.
- Almost identical to your own try, it does not match as expected as, shown in your picture, because it matches the first two sections
-
As we see that this range of chars crosses the
</url>ending tag, a possible approach would be to verify that, at any position, there is no</url>string met, with the regex :
(?xs-i) <url> ( (?!</url>) .)+? https://my-website.com/stamina-art\d+/ .+? </url>\R- Bingo ! This time, it does select the
<url>•••••</url>sections2and3, only, containing the https://my-website.com/stamina-art string
- Bingo ! This time, it does select the
-
However, if we notice that all the
URLaddresses come next, after the<url>opening tag and the<loc>tag, a more simple regex is possible :
(?xs-i) <url> \s+ <loc> https://my-website.com/stamina-art\d+/ .+? </url> \R-
Indeed, between the
<url>and https://my-website.com/stamina-art parts, we just have the regex\s+<loc>which is enough restritive to prevent from a wrong long match ! -
And the regex part
.+?, with the lazy quantifier+?? will match the smallest range of chars, after the address till the first</url>ending tag found
-
So my final solution is :
SEARCH
(?xs-i) <url> \s+ <loc> https://my-website.com/stamina-art\d+/ .+? </url> \RREPLACE
Leave EMPTYHope this helps !
Best Regards,
guy038
-
-
thank you @guy038
-
@guy038 said in Regex: Select and delete the content of tags from xml file with skiping other tags:
(?xs-i)
@guy038 What exactly does
(?xs-i)in the example of regex? It is not the same as(?s)? -
I forgot to mention the .matches newline
Ah, okay. That’s an important part of it.
What exactly does (?xs-i) in the example of regex? It is not the same as (?s)
It isn’t the same, but
(?xs-i)will do the(?s)functionality as well as other things.It works like this:
(?turnOnOptions-turnOffOptions)The options of value are:
x : free-spacing mode (embedded spaces are ignored)
s : single-line mode (bad name), turning on is equivalent to. matches newlineticked, turning off is same as unticked
i : ignore caseIf you turn “on” ignore case, then case will be insignificant (both
aandAwill match if you useain your espression.
If you turn “off” ignore case, then you are saying case matters (ais different fromA) -
In my previous post, I said, at the beginning :
Note that I’ll use the free-spacing mode
(?x)for a better readabilityAnd, two lines after I said :
- Note that we use the
(?s)modifier as we need to match a multi-lines area. We also use the(?-i)modifier to match</url>and, for instance, not</UrL>nor<URL>
Now, as always, everything is in the fucking manual ! So, first, go to the official N++ documentation :
https://npp-user-manual.org/docs/searching/#search-modifiers
And you may have a look to these two
HTMLpages, below, on theregular-expressions.infosite :https://www.regular-expressions.info/modifiers.html
https://www.regular-expressions.info/freespacing.html
Note that the N++
Boostregex engine just handles the four modifiersi,s,xandmand their negative counterparts-i,-s,-xand-m!
Enjoy your reading !
Afterwards, you should be able to understand the
(?xs-i)group of in-line modifiers, which is definitively different from the shorter(?s)syntax !BR
guy038
- Note that we use the
-
@guy038 said in Regex: Select and delete the content of tags from xml file with skiping other tags:
Now, as always, everything is in the fucking manual ! So, first, go to the official N++ documentation
Whoa, whoa, WHOA!
Could it be that the ever-patient @guy038 is getting tired of all the repetitive regex stuff here?? Say it isn’t so.
I get tired of it as well…so tired…but I haven’t yet been driven to use the alternate definition of RTFM (the normal definition being Read That Fine Manual).Seriously, though, when I look at that section of the manual, it reads more like formula rather than specific application (and that’s ok).
In the manual we have:
(?enable-disable)which, well, isn’t exactly crystal clear for those that don’t already know what it means.
So my attempt, in explaining the (?.. : …) construct was to help clarify.
I don’t know if I succeeded.