Adding text at the end of only certain lines that end in a number (variation of numbers)
-
I am trying to convert my VTT subtitles to VTT with cues (adding positions at the end of the time code).
Since I have currently not found a subtitling program with my specific needs for that format, I am looking into converting my VTT files with Notepad++ by adding a few lines.This is what I have so far:

- This is how the VTT looks when exported (only time stamp, no positioning)
- This is how I NEED it to look (with the extra positioning cues at the end of the time stamp)
- Searching for: --> ::. finds my timestamp perfectly! But when I want to add text on, it replaces that text with the literal characters: “–> ::.”
EXAMPLE: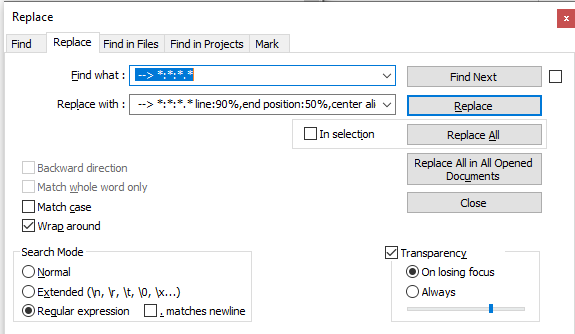
- Trying to search for $ and then adding text at the end of the line puts the extra cues in too many places. I need them in every third line, right after the time stamp.
EXAMPLE: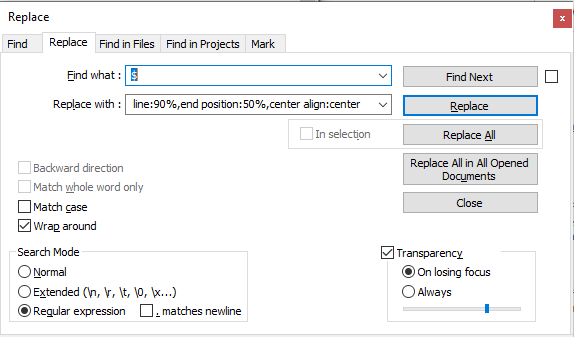
- Searching for: \d{3}$ finds my the numbers at the end of a line perfectly! But once again, when I have to type that same thing into “replace”, it puts the literal characters: \d{3}$
EXAMPLE: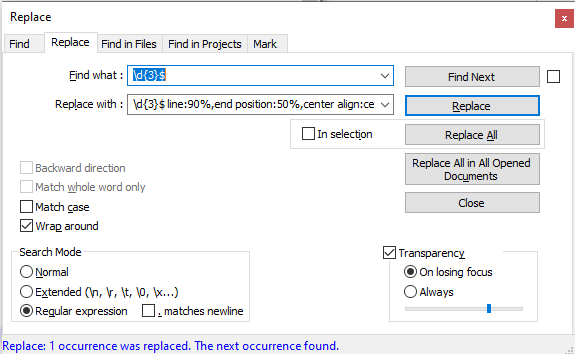
I need to do hundreds of subtitle files with these conversions, so manually doing them is a big deal. I was hoping a simple numbers wildcard search/replace might work. Or anyone know another program that can search and replace like I need it to?
-
Thanks for showing what you’ve tried, and your thought process. That was helpful.
I would use a combination of your 1st and 5th option, plus knowing the magic of substitution escapes, where if you use
${0}in the replacement, it will insert the original matched text at that location.- FIND =
--> \d{2}:\d{2}:\d{2}\.\d{3}$ - REPLACE =
${0} line:90%,end position:50%,center align:center - MODE = regular expression
so
00:00:02.388 --> 00:00:07.625 some text goes here 00:00:08.738 --> 00:00:11.111 some text goes herebecomes
00:00:02.388 --> 00:00:07.625 line:90%,end position:50%,center align:center some text goes here 00:00:08.738 --> 00:00:11.111 line:90%,end position:50%,center align:center some text goes here - FIND =
-
This is a case of needing the grouping operator ‘( )’
Add parenthesis around the entire search string (Find what:) in your first example:
(--> *:*:*.*)And replace the reference to that same string in the replacement with:
\1which means when searching: match this as a group
and when replacing: place the first group here
This can be repeated with additional parenthetic groups and numerically increasing replacement values (which can be used in any order). -
My suggestion joins the party: search for
\d\d:\d\d:\d\d\.\d{3} --> \d\d:\d\d:\d\d\.\d{3}\Kand replace it simply with the text you want to add in.There is a lot of scaryness going on with this suggestion:
(--> *:*:*.*)but amazingly it does seem to match what is desired. -
@PeterJones This worked perfectly! I have to admit, this is my very first post to any internet forum with a question - and I’m blown away by the multiple working solutions that came so fast. Thank you!
-
@artie-finkelstein This also worked great for me! I love the simplicity of it, too! Thank you!
-
@Alan-Kilborn Mmmm, I wasn’t able to get this solution to work (copying/pasting your suggestions into “Find” and typing in my text in “replace”. It gave me an error “zero length match”. I must admit, while I understood the other suggestions (and they worked), I don’t understand this one well, which is probably why I’m executing it wrong. Sorry, but thank you for the help!
-
@Laura-Stiles said in Adding text at the end of only certain lines that end in a number (variation of numbers):
it gave me an error “zero length match”
That’s not an error message, it’s an informational message, with a little arrow indicator at where the match occurred.
As you might think, if you find a zero length match, when you replace it, it doesn’t replace anything existing.
But what it does do, is uses the location where the little arrow points as an insertion point for the replacement text.
So… you could use my expression for Find what , with a Replace with ofline:90%,end position:50%,center align:centerto get at least close to what you want.See where the little arrow points?:

One little caveat is that you would have to use Replace All with a find expression that uses
\Klike this one does. Replace of each occurrence one at a time doesn’t work (Notepad++ bug). -
@Laura-Stiles said in Adding text at the end of only certain lines that end in a number (variation of numbers):
@artie-finkelstein This also worked great for me! I love the simplicity of it, too! Thank you!
Again, a word of warning: That was a dangerous solution (based upon your original input) that is wrong for a number of reasons. It uses the
*in totally the wrong way (more like a command line file wildcard than a regular expression pattern repeater). It just so happens to be “okay” for this application. -
@Alan-Kilborn
Thanks for the warnings!I agree it’s scary, as it relies on the regex engine in use not having grown enough to use even more non-alphabetic characters as operators (this is an observation on regex in general, not Boost or Notepad++ in particular).
I have discovered when using a regex to:
- save the file before starting
- not be afraid to use the undo command
- be willing to admit defeat and abandon the edit session (without saving)
- start again
I’m one of those grey beards that finds it easier to go for it (using the above steps) rather than try to sanitize my way around this weeks/months/years new regex schema. I find regex hard enough without having to keep straight the countless variants that have been developed over the last 40+ years.
I won’t submit suggestions I haven’t tested, and will definitely stay out of the jungles some of the posters fearlessly wade into.
-
@Alan-Kilborn said in Adding text at the end of only certain lines that end in a number (variation of numbers):
--> *:*:*.*So a specific example:
The above regex will match this text:
--> ::::::::::::::::::dddddddddddfffffjjjjea::::zefjajwhich is clearly only like a timestamp in that it has the-->to its left!Basically, the regex will match
-->followed by anything!!! DANGEROUS!@artie-finkelstein said:
I agree it’s scary, as it relies on the regex engine in use not having grown enough to use even more non-alphabetic characters as operators
I’m not following that.
I think it is scary because it misleads one that is not adept in regex that it is doing something other than it is. -
@artie-finkelstein and @Laura-Stiles ,
As Alan says, the
--> *:*:*.*which first showed up in Laura’s screenshot and which Artie repeated does not do what Laura intended it to do, because it appears Laura was using * as though it were a Windows command line filename wildcard, to match "-->followed by a space, then anything, then colon, then anything, then colon, then anything, then dot, then anything. Regexes use different syntax than MS cmd.exe.-->matches that literal text*(space star) matches 0 or more space characters:*(colon star) matches 0 or more colon characters.*(dot star) matches 0 or more of any character
So it was matching “literal
-->followed by 0 or more spaces followed by 0 or more colons followed by 0 or more colons followed by 0 or more of any character”. “0 or more” of the spaces and colons mean it can get to the space beyond the-->, then the “0 or more of any character” matches the rest of the line, whatever it happens to be. When you piece it all together, Alan’s brief description of “Basically, the regex will match --> followed by anything” sums it up.So what was “scary” about the regex is that it appeared to work, but for all the wrong reasons, and to use it thinking that it was matching the pattern that was intended is foolhardy.
I won’t submit suggestions I haven’t tested,
But you obviously didn’t test it against edge cases, because otherwise you would have seen that it matched a line with a single
-->and nothing else.When giving help for a regex, never share a regex that you only test on data that matches, without testing on data that shouldn’t match to make sure you don’t have a fundamental flaw – like a regex that happens to match this one piece of data without meeting any of the criteria given in the problem description!
When asking for help with a regex, never share only data that matches and always include data that shouldn’t match, making sure you’ve thought about edge cases. The answers you get will be much better that way, because the people who are helping you will be able to test against both matching and non-matching data.
-
Thanks for being a different voice saying similar things.
I could see others reading my previous replies and thinking “yea, right, this guy is seriously clueless”. :-) -
Hello, @laura-stiles, @alan-kilborn, @peterjones, @artie-finkelstein and All,
We can transform the @laura-stiles’s regex
--> *:*:*.*with the following equivalent syntax :(?x-s) --> \x20{0,} :{0,} :{0,} .{0,} # A very STRANGE regex ! ------ --- -------- ----- ----- ----- ------------------------- A B C D E F G
To @laura-stiles :
The first part A means that :
-
We’ll use the free-spacing mode
(?x). In this mode :-
Any blank char, as space and tabulation are irrelevant. If you need to search for these characters, literally :
-
Escape them with a
\character -
Use their regex equivalent
\x20and\t -
Use the braket syntax
[ ]for space
-
-
Any range of characters, after a first
#, are irrelevant and seen as comment characters. ( refer to part G ). To search for a litteral#character, use, either, the\#,\x23or[#]syntaxes !
-
-
We won’t use the single line mode
(?-s). In this mode, the.dot regex character matches any character, even EOL characters. As we disable this mode, this means that a regex symbol.just matches a single standard char
To All :
If we consider the subject string
--> 00:00:07.625, we can say that :-
Part B matches the literal string
--> -
Part C matches the space char, after the
-->string -
Part D and E match nothing as no colon char
:exists, after the space char -
Part F,
.{0,}, matches any range, even empty, of standard chars so the remaining chars till the end of the line :00:00:07.625 -
Part G are comments
You may verify my assertions by running the regex S/R , below, against the string
--> 00:00:07.625:SEARCH
(?x-s) ( --> ) ( \x20{0,} ) ( :{0,} ) ( :{0,} ) ( .{0,} )REPLACE
Group 1 >\1<\r\nGroup 2 >\2<\r\nGroup 3 >\3<\r\nGroup 4 >\4<\r\nGroup 5 >\5<\r\n
Similarly, if we consider the @alan-kilborn’s subject string
--> ::::::::::::::::::dddddddddddfffffjjjjea::::zefjaj:-
Part B matches the literal string
--> -
Part C matches the space char, after the
-->string -
Part D,
:{0,}, with a greedy quantifier, matches the greastest number of colon chars. So, the string:::::::::::::::::: -
Thus, the part E,
:{0,}, matches zero:characters. So, an empty string ! -
And the part F,
.{0,}, matches all the remaining chars of the line. So the stringdddddddddddfffffjjjjea::::zefjaj
Again, verify these assertions by running the following regex S/R , below, against the string
--> ::::::::::::::::::dddddddddddfffffjjjjea::::zefjaj:SEARCH
(?x-s) ( --> ) ( \x20{0,} ) ( :{0,} ) ( :{0,} ) ( .{0,} )REPLACE
Group 1 >\1<\r\nGroup 2 >\2<\r\nGroup 3 >\3<\r\nGroup 4 >\4<\r\nGroup 5 >\5<\r\nBest Regards,
guy038
P.S. : Oh, Peter beat me at it ;-))
-
-
Maybe the overall summary is:
Do NOT think of command shell style file globbing
*when you are formulating a regular expression, because it does not help. I suppose that in some cases that is difficult, if you are more familiar with how*works on command lines than you are with regular expressions. -
…OR…
Train yourself such that whenever you are tempted to use
*(from your command-line thinking), to use.*?instead – a rough regex equivalent, meaning: match 0 or more of any character, minimally. The “minimally” part is there mainly for safety. But of course this is just a rough guide, as things go deeper than that.BTW, this is all similar for
?– this is different in regex than it is on the command line as well.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login