Entering curly quote marks as UDL operators, or keywords
-
Hi
When I enter “” or ‘’ … the curly counterparts of the quotations marks on our keyboards into any of the Operators of the UDL, to help me find unbalanced curly quotes, it does not register. Entering the straight quotes work. I can see clearly where the text has missed a closed quote. Is there a way for Notepad++ UDL to incorporate the curly quotes?
Thanks.
-
@Ian-Oh ,
The UDL implementation isn’t very strong when it comes to non-ASCII Unicode characters. There have been many bug-reports/feature-requests to improve Unicode handling in the UDL, but none of them have been addressed. Sorry.
However, you might be able to get something good enough for your purposes by using the Search > Mark dialog:
"normal" “blah blah” “imbalanced open “blah” “imbalanced close” blah”FIND =
“[^”]*“[^”]*”|“[^”]*”[^“]*”, purge each search, search-mode = regular expression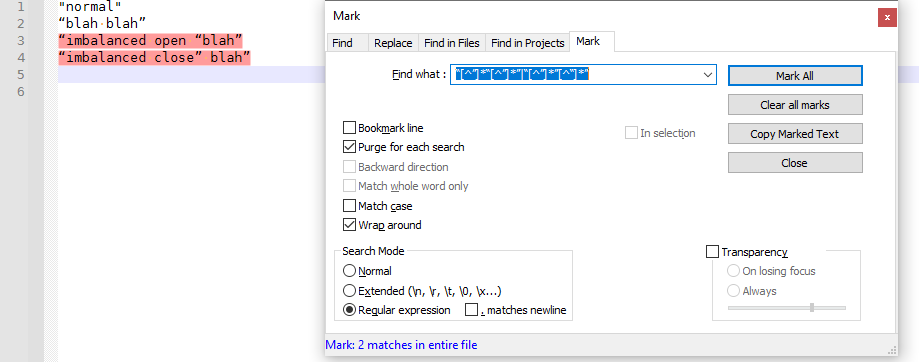
That find looks for (1) an open double-quote followed by 0 or more characters that aren’t a close, followed by another open, followed by 0 or more characters that aren’t a close, followed by a close (thus finding an extra imbalanced open quote); OR (2) open followed by 0-or-more non-close, followed by close, followed by 0-or-more non-open, followed by another close (thus finding an extra imbalanced close quote).
-
Wow! That’s a thing of beauty… or as we’d say down under … Ubewdy! Thank you very much.
And thanks for explaining the limitations of UDL to ASCII.
-
Hello, @ian-oh, @peterjones, @alan-kilborn and All,
Sorry for not being very responsive, but I am currently on vacation and consult our forum rather rarely !
Before presenting the regexes which allow this kind of search, paste the following five lines, in a new tab and let’s study some concepts. Note that line
5contains a full periodStart blah “blah blah” “imbalanced open “blah” “imbalanced close” blah” This is a ““Te”st”“““abc”de”fgh. Ijkl”“mnop”” EndIf we’re going to search the longest area, with well balanced delimiters
“and”, we must, first, consider the total range where to search these areas. Let me explain :-
Case
A: We may suppose that this range is the file contents ( Default case ) -
Case
B: We may suppose that this range is limited to current line contents -
Case
C: Finally, we may suppose that this range is limited to a single sentence contents, within current line
If, by convention, any text, without double curly quotes, is considered as well balanced ( zero
“char and zero”char ), we can say that :-
Regarding case
A:-
The multi-line area, beginning from word
Start, in line1, till the string“mnop”, in line5, forms an area with the same number of opening and closing double curly quotes ! ( The last”, before End, is not included ) -
Then, the final
Endword, preceded with a space char, is a well-balanced area, by default !
-
-
Regarding case
B:-
Line
1and2are well balanced -
Line
3contains the well balanced areaimbalanced open “blah” -
Line
4contains the well balanced area“imbalanced close” blah -
Line
5contains the well balanced areaThis is a ““Te”st”“““abc”de”fgh. Ijkl”“mnop”
-
-
Regarding case
C:-
Line
1to4are identical to caseB -
Line
5contains :-
The well balanced area
This is a ““Te”st”, in the first sentence -
The well balanced area
““abc”de”fgh, right before the period -
The well balanced area
ijkl, preceded with a space char, in the second sentence -
The well balanced area
“mnop” -
The well balanced area
End, preceded with a space char
-
-
So, if we add
+1for any opening double curly quote and-1for any closing double curly quote, we get this table, where any•char refers to an unmatched double curly quote !•--------•---------------------------------------------------• | Line 1 | Start blah | | Count | | •--------•---------------------------------------------------• | Line 2 | “blah blah” | | Count | 1 0 | •--------•---------------------------------------------------• | Line 3 | “imbalanced open “blah” | | Count | • 1 0 | •--------•---------------------------------------------------• | Line 4 | “imbalanced close” blah” | | Count | 1 0 • | •--------•---------------------------------------------------• | Line 5 | This is a ““Te”st”“““abc”de”fgh. Ijkl”“mnop”” End | | Count | 12 1 0•12 1 0 . •1 0• | •--------•---------------------------------------------------•
Thus, @ian-oh, according to the case
A,BorC, you"ll execute the following recursive regexes, in free-spacing mode, beginning at(?x), till the(?1)+syntax :Case A : (?x) (?: ( [^“”] )* ( “ (?: (?1)++ | (?2) )* ” ) )+ (?1)* | (?1)+ Case B : (?x) (?: ( [^“”\r\n] )* ( “ (?: (?1)++ | (?2) )* ” ) )+ (?1)* | (?1)+ Case C : (?x) (?: ( [^“”.!?\r\n] )* ( “ (?: (?1)++ | (?2) )* ” ) )+ (?1)* | (?1)+ ^ ^ | | Groups ---------> 1 2
Notes :
- These regexes are derived from the end of this article, in the official N++ documentation, which explains how to search for well balanced regions with parentheses :
(?x) (?: [^()]* ( \( (?: [^()]++ | (?1) )* \) ) )+ [^()]* | [^()]+-
For case
C, I considered that a sentence ends at a full period and at an interrogation or exclamation mark. Add other characters to this list if necessary ! -
These regexes are mainly composed of non-capturing groups and contain only two groups :
-
A non-recursive group
1which refers to the allowed characters, for each case ( not included the double curly quotes ) -
A recursive group
2, as one reference(?2)is located inside the group2itself, which adds some intelligence to the overall search by a recursive evaluation of the text
-
-
Note that, in case of incoherent results, it is advised to replace any
(?1)syntax by its true value( [^“”] ), or( [^“”\r\n] )or( [^“”.!?\r\n] ). This may helps ! -
Don’t try to perform backward searches : it won’t work !
Here is an other text of
7lines, whith a lot of double curly quotes, for additional tests of these3recursive regexes :““““ab“““cd““ef”””gh”.ij””klm”””” ““ab““““cd“““ef”””gh””””ijkl”””” ““““““ab“cd“ef“”””gh”ijkl””?”mn””””” ““--ab“cd“ef--gh“ij--kl”mn”o!p““qr--st”uv\wx”--”yz””------”abc abcd--------““efghi----jk”----”lmnop------ ““--ab”cdef--ghi.j--klmn---op““qr--stu”vwx--”yz”---- ---abcde-----““qrs”tu--”vwxyz---
If you paste these
7lines in a new tab, you’ll verify that, with the regexAsyntax, the last match is all the well-balanced area, below :abc abcd--------““efghi----jk”----”lmnop------ ““--ab”cdef--ghi.j--klmn---op““qr--stu”vwx--”yz”---- ---abcde-----““qrs”tu--”vwxyz---Which contains, exactly, eight
“opening characters and eight”closing characters !Best Regards
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login