Python Script Regex replace with uppercase
-
Hello again, all. In the midst of constructing a new Python Script regex replacement script, I’ve hit a snag using my usual methods, but found a workaround which has taken care of my use cases so far, but wonder if anybody here knows of a more universal fix. Debug info:
Notepad++ v8.1.3 (32-bit)
Build time : Aug 10 2021 - 00:32:53
Path : C:\Program Files (x86)\Notepad++\Notepad++.exe
Command Line : -multiInst -nosession
Admin mode : OFF
Local Conf mode : OFF
Cloud Config : OFF
OS Name : Windows 10 Enterprise (64-bit)
OS Version : 2004
OS Build : 19041.1165
Current ANSI codepage : 1252
Plugins : ComparePlugin.dll DSpellCheck.dll ElasticTabstops.dll ExtSettings.dll mathpad.dll mimeTools.dll MultiClipboard.dll NppCalc.dll NppConverter.dll NppExport.dll NPPJSONViewer.dll NppQrCode32.dll NppSaveAsAdmin.dll NppTextFX.dll NppXmlTreeviewPlugin.dll PythonScript.dll SessionMgr.dllIt should be noted (again; I have pointed this out in previous topic “Intricacies of Regex Replace via Python Script”) that I deal almost exclusively with ANSI text, Windows-1252 encoded text files, but do process the odd Unicode text file now and then, and prefer my scripts to be able to handle both if possible.
My Python Script code to search for and capture lowercase characters at the start of any line and replace with uppercase:
editor.rereplace(r'(?-i)^([a-z])', ur'\U\1')This has resulted in error message: “SyntaxError: (unicode error) ‘rawunicodeescape’ codec can’t decode bytes in position 0-1: truncated \uXXXX”
I seem to have identified the source of the problem as being
ur'\U\1', apparently because Python is expecting a sequence of digits following the\Uin order to represent some Unicode character, whereas I only want an uppercase character to replace a lowercase character. If I change the code tor'\U\1', it works in my ANSI text test cases — but it was previously suggested to me to useur''in my replacement code in order to have it work with both ANSI and Unicode text. Do I have any other options? -
@M-Andre-Z-Eckenrode said in Python Script Regex replace with uppercase:
Do I have any other options?
Probably. Unfortunately, I am not enough of a Python expert, and I’m not good with the intracies of its “string” vs “Unicode string” handling. I was hoping @Ekopalypse would have chimed in as the regular who seems to best understand the intricacies of Python, but he hasn’t logged in yet this weekend. This @-mention should trigger a notification, so the next time he does log in, it will flag this post for him.
However, I am not sure if PythonScript 1.5.4, which uses Python 2.7.18, will have the
\U= upper-case substitution expression – I don’t see it in the https://docs.python.org/2.7/library/re.html documentation. The Python 3 re doc (https://docs.python.org/3/library/re.html) does list\U, but in the context of embedding a unicode character.But the previous post you linked seems to indicate
editor.rereplaceis using the boost regex engine like Notepad++ uses, in which case it should know the\Unotation – hence why it works for your ASCII strings with a raw-only string for the replacementSo my next guess is that by combining raw and unicode string indicators, it enables the
\unotation (which per https://docs.python.org/2.7/howto/unicode.html#the-unicode-type is available in 2.7), and thus Python turns that into a unicode-escape before it gets to the boost engine. You might want to experiment withur'\\U\1to see if double-escaping the U will allow the\Uto pass through to the boost::regex engine. I don’t know.I don’t know if anything I said will help. Mostly, I replied to let you know “we’re not ignoring you”, and to @-mention @Ekopalypse.
-
@PeterJones said in Python Script Regex replace with uppercase:
You might want to experiment with
ur'\\U\1to see if double-escaping the U will allow the\Uto pass through to the boost::regex engine.Thanks for the reply and suggestions, Peter. Unfortunately, using
\\U\1results in “\U” getting inserted into my text. I’ll hold out hope for some wisdom from @Ekopalypse or anyone else more knowledgeable and experienced than myself. -
Perhaps THIS is a barrier to it working regardless of what’s been discussed so far?
-
@Alan-Kilborn said in Python Script Regex replace with uppercase:
Perhaps THIS is a barrier to it working regardless of what’s been discussed so far?
Good catch and point, though I think there must be something more at play here, since
\LandlDO work for me via Python Script. -
@M-Andre-Z-Eckenrode said in Python Script Regex replace with uppercase:
since \L and l DO work for me via Python Script.
With PS 1.5.4, I tried this and it didn’t replace anything, so
\Ldoesn’t appear to work for me:editor.rereplace(r'(?-i)([A-Z])', ur'\L\1')And yes, I had some uppercase characters in my doc; I also tested by using
@as the replace string, just to verify the replacement in general was working – it was. -
@Alan-Kilborn said in Python Script Regex replace with uppercase:
editor.rereplace(r'(?-i)([A-Z])', ur'\L\1')Interesting… I used a nearly identical line of code here, and it works for me:
editor.rereplace(r'(?-i)^([A-Z])', ur'\L\1')Note that my script file is itself ANSI/Windows-1252, and therefore begins with the following line:
# encoding: Windows-1252I’m guessing yours is Unicode, and maybe that’s the interfering factor?
-
Weird.
I just tried a comparison:
Zz Yy XxXx C_ À Á Â Ã Ä Å-
File that is Encoding > ANSI:
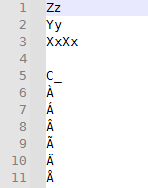 =>
=> editor.rereplace(r'(?-i)^([A-Z])', ur'\L\1')=>
-
File that is Encoding > Charset > Western > Windows-1252: same file, same rereplace line, no characters go lowercase
-
File that is Encoding > UTF-8: same file, same rereplace line, no characters go lowercase
So ANSI works differently than a forced charset or forced UTF-8.
-–
addendum:Notepad++ v8.1.4 (64-bit) Build time : Aug 21 2021 - 13:04:59 Path : C:\usr\local\apps\notepad++\notepad++.exe Command Line : Admin mode : OFF Local Conf mode : ON Cloud Config : OFF OS Name : Windows 10 Enterprise (64-bit) OS Version : 2009 OS Build : 19042.1165 Current ANSI codepage : 1252 Plugins : AutoSave.dll ComparePlugin.dll ExtSettings.dll MarkdownViewerPlusPlus.dll mimeTools.dll NppConsole.dll NppConverter.dll NppEditorConfig.dll NppExec.dll NppExport.dll NppFTP.dll NppUISpy.dll PreviewHTML.dll PythonScript.dll QuickText.dll TagLEET.dll XMLTools.dllPython 2.7.18 (v2.7.18:8d21aa21f2, Apr 20 2020, 13:25:05) [MSC v.1500 64 bit (AMD64)] -
-
Instead of doing the lowercase through a regex replacement in the
rereplace, what about a lambda function?editor.rereplace(r'(?-i)^([A-Z])', lambda m: m.group(1).lower())worked in all three of the test file conditions I listed in my previous post.And the opposite, which your original question asked for,
editor.rereplace(r'(?-i)^([a-z])', lambda m: m.group(1).upper()) -
@PeterJones said in Python Script Regex replace with uppercase:
Instead of doing the lowercase through a regex replacement in the
rereplace, what about a lambda function?I’ve never even heard of that before, but it sounds like a promising work-around unless and until an actual fix for
rereplaceis in place, if possible. Where can I read more about lambda? I see only a passing mention in the Python Script doc page for ‘Editor Object’, and though typing ‘lambda’ in the search box for the online NPP user manual makes it appear that it can be found in numerous sections including ‘Searching’, I’m unable to locate any specific instance of it there using my browser’s ‘Find’ facility. -
@M-Andre-Z-Eckenrode said in Python Script Regex replace with uppercase:
Where can I read more about lambda?
lambda functions are part of Python, not specific to Notepad++'s PythonScript plugin.
Read more about them by “googling” for “lambda functions in Python”.
lambda functions are available in other programming languages as well, so it is not even something specific to Python (but that’s the context here, so…).
-
@Alan-Kilborn said in Python Script Regex replace with uppercase:
Read more about them by “googling” for “lambda functions in Python”.
Ok, thanks much.
-
@M-Andre-Z-Eckenrode said in Python Script Regex replace with uppercase:
@PeterJones said in Python Script Regex replace with uppercase:
I see only a passing mention in the Python Script doc page for ‘Editor Object’,There’s only a passing mention because, as @Alan-Kilborn explained, it’s a standard feature in Python (and elsewhere).
And you don’t even need to know about lambdas for the problem at hand: Really, you just need to learn, as the PythonScript documentation showed, that
rereplaceallows either a replacement expression or a function that it will call on the matching text. A lambda function or a normally-defined function will both work equally well (like the infamousadd_1in the PS docs). The function accesses the text of the match through them.group(#)where # aligns with the capture groups in your regular expression match expression. The function should return the text that you want to replace the entire match with (in your case, the function-based equivalent of\U\1). So whenrereplacefinds a match, it will send that match asmto the function, and then the function returns the replacement value; thenrereplacemoves on to the next match and calls the function again, until no more matches are found. (To make it abundantly clear, your function does not need to loop through the matches; that is handled by therereplace; your function just needs to transform one matchminto some text to return to be used as the replacement.)The call
editor.rereplace(r'(?-i)^([a-z])', lambda m: m.group(1).upper())is exactly equivalent to the longer scriptdef do_capitalize(m): return m.group(1).upper() editor.rereplace(r'(?-i)^([a-z])', do_capitalize)… but it fits nicely in a one-liner. If your replacement function required more than one line (if you wanted to build a more complicated string through various calculations), then you’d have to use the defined-function variant instead of a lambda function.
-
@PeterJones said in Python Script Regex replace with uppercase:
you don’t even need to know about lambdas for the problem at hand: Really, you just need to learn, as the PythonScript documentation showed, that
rereplaceallows either a replacement expression or a function that it will call on the matching text.Noted, and thank you for the more detailed explanation. Although I can’t think of any immediate use for a lambda function other than your helpful suggestion for
rereplacejust now, it’s certainly possible on will come to me in the future, so I’m happy to learn more about it than I absolutely have to for my present needs — even though a refresh and more thorough study of it will surely be necessary when the time comes.Thanks again to you and @Alan-Kilborn for your help.
-
It might have been instructive for the PythonScript docs to have shown the
add_1example as a lambda, e.g.:editor.rereplace('X([0-9]+)', lambda m: 'Y' + str(int(m.group(1)) + 1))
For those without easy access to the PythonScript docs, here’s what they DO show:
def add_1(m): return 'Y' + str(int(m.group(1)) + 1) # replace X followed by numbers by an incremented number # e.g. X56 X39 X999 # becomes # Y57 Y40 Y1000 editor.rereplace('X([0-9]+)', add_1);And, No, I’ve no idea what’s up with the trailing semicolon on the last line of that example.
-
Sorry for the late and already too late reply, but I usually stay away from the computer on weekends.
I assume that Python does its string processing before the boost::regex function gets a chance to interpret the string, but I’ve never really looked into it. The lambda or explicit function solution seem to be the way to solve this problem.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login