I want to compare two files and bookmark the lines containing similar words
-
Hi,
I want to compare two files and bookmark the lines containing similar words, for example:
file1.txtAhmed:12321
Ali:22432
Khalid:567643file2.txt
Ahmed
AliI found a method that could be used here but the lines have to be identical for it to work.
Basically, you should go to the bottom of file1 and put ##### then paste the contents of file two and press ctrl M and use this regex (?-s)^(.+\R)(?=(?s).#####.?\1) with the search mode regular expressions and “bookmark line” box checked then clicking mark all.
If you have knowledge in regular expressions please help me to make it exclude whatever after the : and only compare whatever is before it to file2 contents. -
@Bader-Alharbi said in I want to compare two files and bookmark the lines containing similar words:
(?-s)^(.+\R)(?=(?s).*#####.*?\1)Change the
(.+\R)to(.+?:).*?\R– everything else should stay the same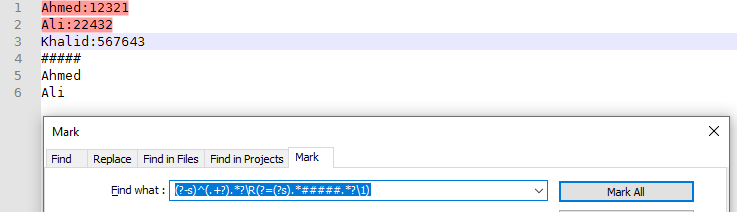
-
Hello, @bader-alharbi, @peterjones and All;
Here is a general solution which marks every word of
File 1ONLY IF this specific word is also present inFile 2:MARK
(?s-i)\b(\w+)\b(?=.+#####.+?\b\1\b)So, for instance, from this initial text :
Ahmed:12321 12345,56789 Ali:22432 Khalid:567643 Alone sentence Queen Elisabeth This is a 789 test ali Mary Thompson ##### Ahmed Mary 789 Elisabeth 567643 test,a is:ThisYou would obtain, after the Mark process :
Ahmed:12321
12345,56789
Ali:22432
Khalid:567643
Alone sentence
QueenElisabeth
Thisisa789test
ali
MaryThompson
#####
Ahmed
Mary 789
Elisabeth
567643
test,a is:This
Notes :
- The words in
File 2can be in any order ;-)) I could have used :
##### Mary 789 Ahmed Elisabeth 567643 test a is!Thisor even :
##### Mary,a,789,is,Ahmed,Elisabeth,This,567643,test
-
The present search is sensitive to case. If you prefer to search identical words, whatever their case, change the beginning of the regex from
(?s-i)to(?si) -
By default, the part
\b(\w+)\blooks for the greatest range of word characters, between2non-word chars. And a word character represents any single letter, accentuated letter, digit or the_character. If you want to modify or add other characters to be considered as words, just go toSettings > Preferences... > Delimiter > Word character list
Best Regards,
guy038
- The words in
-
Hi, @guy038
That worked perfectly for me. Thanks a lot.
I still have one more question, is there a regex to add the line number in multiple places in the line?
For example, if I want to use it like this
mkvmerge -o “line number”.mkv “line number”.mp4 “line number”.srt
mkvmerge -o “line number”.mkv “line number”.mp4 “line number”.srt
mkvmerge -o “line number”.mkv “line number”.mp4 “line number”.srtI’m doing it now using the column editor but I’d like to use it in a macro and apply it to different files with a different number of lines.
-
@PeterJones
I tried the one you posted, and it works too. Thank you.
Please let me know if you can help me with the other question I mentioned in my earlier reply? I would appreciate it. -
@Bader-Alharbi said in I want to compare two files and bookmark the lines containing similar words:
is there a regex to add the line number in multiple places in the line?
Regular expressions cannot count (they have no concept of “increment a number”). Your two options inside Notepad++ are using the Column Editor like you’ve already discovered, or using a scripting plugin like PythonScript and using the full power of a programming language to influence the text in the open file. (I actually just answered a question earlier today on that same concept.)
apply it to different files with a different number of lines.
as linked in that other topic (and the links refenced there), you can make a macro that will do the begin/end-select for column mode… and if you combined that with other controls, like the
Ctrl+Hometo go to the start of the file, andCtrl+Endto go to the end, you could have a macro that does the zeroeth-column select in the macro, then manually typeAlt+Cto bring up the column editor and insert the numbers, then you could use another regex (using multiple capture groups) to distribute the number from the beginning of the line to the various locations throughout the line that you need
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login