Search for a text and copy the previous lines of codes
-
Anything you put before the
\Kwill be effectively “lookbehind”. Before that\K, you can use any valid regex syntax, which will carry the same meaning. So if you want to match thedef, but only if it’s prefaced byabcorxyz, or one-or-more-xes, and with zero or more spaces between it and thedefyou could look for(?:abc|xyz|x+)\h*\Kdef– this will match thedefinabcdeforabc deforabc def(with lots of spaces between, which the forum won’t let me show) orxyz deforxxxxxxx deforxdefor many others.(In your actual example of
xxx, and without the variable number of spaces, there would have been no reason for the\K, and you could have used a normal lookbehind, because the number of characters could be exactly known by the regex engine:(?<=(abc|xyz|xxx) )def. Thus, I changed the example to something that could match any number of characters, and thus wouldn’t work in a normal lookbehind situation.)(I added spaces while writing this up, because your multiple posts and edits were moving in that direction)
-
Examples:
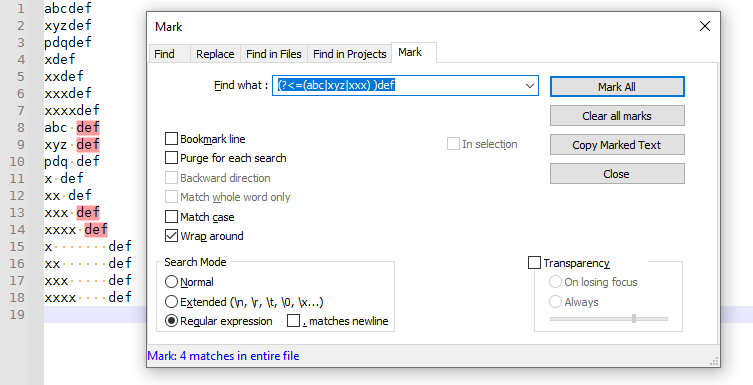
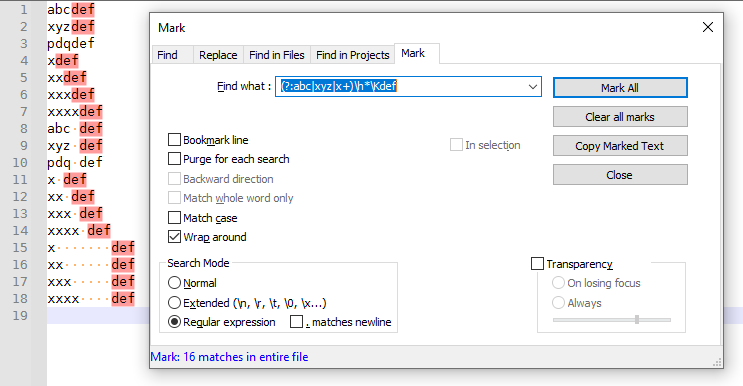
abcdef xyzdef pdqdef xdef xxdef xxxdef xxxxdef abc def xyz def pdq def x def xx def xxx def xxxx def x def xx def xxx def xxxx def -
@PeterJones I want to use the lookbehind RegEx only. Suppose the
defin the string I typed above is the only unique code (or whatever it may be called), how to find all that I asked for above using the lookbehind RegEx? -
@PeterJones Something like
(?<!abc)(?<!xyz)(?<!xxx)(?<=def)? -
@PeterJones I believe your Regex will work but what if I wanted to use the lookbehind RegEx and skip some codes/strings just before a unique code/string?
-
I am not here to be your personal regex writer and regex debugger, sorry. I gave you general principals. I gave you specific examples. We have linked you to regex documentation. I’m not sure what else you can reasonably expect from us.
As we said, if the length varies,
\Kis equivalent to lookbehind. You need to use whatever syntax works for your particular situation. Your brief examples aren’t enough for us to know if they’ll work for your actual needs.As a parting help,
- I have no idea why you suddenly switched to negative lookbehind. All your descriptions have said “I want to match the
defassuming thatabcorxyzorxxxcome before it”. But the regeex you just proposed says “matchdefas long as none ofabcorxyzorxxxcome before it” which is literally the opposite of what you’ve previously asked for. - Why did you put
defin a lookbehind when you wanted it to be part of the match itself. From that, you would just want(?<!abc)(?<!xyz)(?<!xxx)def– with thedefnot in a lookbehind.
But, to use an analogy: it’s time for you to take off the training wheels and try to learn how to balance and bicycle on your own. You need to learn regular expressions enough that you can do it without constantly relying on us to guess whether or not a regular expression will work for the data that we cannot see that you don’t accurately describe to us.
----
Please note: This Community Forum is not a data transformation service; you should not expect to be able to always say “I have data like X and want it to look like Y” and have us do all the work for you. If you are new to the Forum, and new to regular expressions, we will often give help on the first one or two data-transformation questions, especially if they are well-asked and you show a willingness to learn; and we will point you to the documentation where you can learn how to do the data transformations for yourself in the future. But if you repeatedly ask us to do your work for you, you will find that the patience of usually-helpful Community members wears thin. The best way to learn regular expressions is by experimenting with them yourself, and getting a feel for how they work; having us spoon-feed you the answers without you putting in the effort doesn’t help you in the long term and is uninteresting and annoying for us.
----
Do you want regex search/replace help? Then please be patient and polite, show some effort, and be willing to learn; answer questions and requests for clarification that are made of you. All example text should be marked as literal text using the
</>toolbar button or manual Markdown syntax. To makeregex in red(and so they keep their special characters like *), use backticks, like`^.*?blah.*?\z`. Screenshots can be pasted from the clipboard to your post usingCtrl+Vto show graphical items, but any text should be included as literal text in your post so we can easily copy/paste your data. Show the data you have and the text you want to get from that data; include examples of things that should match and be transformed, and things that don’t match and should be left alone; show edge cases and make sure you examples are as varied as your real data. Show the regex you already tried, and why you thought it should work; tell us what’s wrong with what you do get. Read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. If you follow these guidelines, you’re much more likely to get helpful replies that solve your problem in the shortest number of tries.
- I have no idea why you suddenly switched to negative lookbehind. All your descriptions have said “I want to match the
-
@PeterJones OK, thanks a lot. Like you said, I have been experimenting!
-
@PeterJones Just for your information, I had typed, “
(?<=def)” above, not, “(?<!def)”. -
@Scott-Nielson said in Search for a text and copy the previous lines of codes:
Just for your information, I had typed, “(?<=def)” above, not, “(?<!def)”.
Specifically, you typed
(?<!abc)(?<!xyz)(?<!xxx)(?<=def). My previous post stands correctly as a comment on that regular expression as you typed it. It was a group of four sub-expressions: three negative lookbehinds and one positive lookbehind. My point #1 referred to the first three negative lookbehinds. My point#2 referred to the final positive lookbehind. I stand by my previous assessment of your regular expression. -
@PeterJones got it, thanks.
So for the stringBible. <a href=www.jw.org>Jehovah's witnesses</a> Atheists abc xyz xxx </span> </p>if I had to find just, “
</span>” and
“</p>” when the “</p>” is on the next line, this RegEx should be fine right:(?<!/a)(?<!abc)(?<!xyz)(?<!xxx)(?<=/span)>\s*</p>? -
this RegEx should be fine right
I do not believe you have understood what I have tried to explain previously. As I have said to you multiple times, if it works for you, great! This forum doesn’t exist to be a regex “do-your-homework-for you” site, nor a “tell-me-if-my-regex-is-right” site, nor a regex tutorial site, or a “regex-for-dummies” site, nor a “let’s-talk-about-regex-and-nothing-else” site.
Regular expressions are just a small part of what Notepad++ can do, and once we’ve helped a given user a couple times with regular expressions (and trust me, you’ve gone beyond “a couple” at this point), and pointed the same user multiple times to all the resources that on regular expressions – including the Notepad++ Online User Manual section on search/replace for the canonical reference to Notepad++ regular expressions, and the regular expression FAQ with links to lots of online regex-learning resources, both linked above – then we expect that user to make more use of those documents and links, and take the onus of learning regular expressions upon themselves, rather than expecting us to generate or proofread their every regular expression.
Some personal advice: the only way you are going to learn more about regular expressions at this point is to experiment with them yourself, and read the resources, and try it on your own; us giving you a “seal of approval” won’t help, and us spoon-feeding you a regex that works with the small example data you share won’t help you learn how to do it on your own.
Good luck.
-
Hello, @scott-nielson, @peterjones, @alan-kilborn, @terry-r and All,
@scott-nielson, when you said in an older post :
what RegEx can help skip searching for abc in abcdef, xyz in xyzdef and xxx in xxxdef (all at once, with just one RegEx)?
The @peterjones’s answers are just the right ones :
-
(?:abc|xyz|x+)\h*\Kdefwith the\Kconstruction -
(?<=(?:abc|xyz|xxx)\h*)defwith a positive look-behind
Back to your last post, IF you had tried the regex
(?<!/a)(?<!abc)(?<!xyz)(?<!xxx)(?<=/span)>\s*</p>, you could have seen that this regex, as well as all the following ones :(?<!abc)(?<!xyz)(?<!xxx)(?<=/span)>\s*</p>(?<!xyz)(?<!xxx)(?<=/span)>\s*</p>(?<!xxx)(?<=/span)>\s*</p>(?<=/span)>\s*</p>just match a
>, followed by any number of vertical or horizontal blank characters, even none and, next, the</p>stringOf course, if you’re really looking for this, the simple regex
>\s*</p>seems enough ;-))Or, as you said :
If I had to find just, “</span>” and “</p>” when the “</p>” is on the next line …
may be, this other one
</span>\s*</p>
Now, if you looking for any block
</span> ••••• </p>, after a line<a href ••••• > ••••• </a>which do not contain, in the middle, any textabc,xyzandxxx, with this exact case, the following regex should work :SEARCH / MARK
(?s-i)</a>((?<!abc)(?<!xyz)(?<!xxx).)*?\K</span>\s*</p>Test it against this example :
Bible. <a href=www.jw.org>Jehovah's witnesses</a> Atheists abc </span> </p> Bible. <a href=www.jw.org>Jehovah's witnesses</a> xyz Atheists other text added </span> </p> Bible. <a href=www.jw.org>Jehovah's witnesses</a> Atheists Line 1 xxx Line 2 Line 3 </span> </p> Bible. <a href=www.jw.org>Jehovah's witnesses</a> Atheists Line 1 Line 2 Line 3 </span> </p> Bible. <a href=www.jw.org>Jehovah's witnesses</a> Atheists First sentence Second sentence Third sentence </span></p>As you can verify, this regex just matches the
4thand5thblocks, which do not contain any textabc,xyzandxxx, between</a>and</span>
Note that I use the
\Ksyntax, because, due to non-fixed length generated by the*?non-greedy quantifier, a look-behind syntax cannot be used, in this situation !Best Regards,
guy038
-
-
@guy038 thanks a lot. I don’t know what I would have done without your help!
-
@guy038 Suppose if I don’t have a link, that is
</a>and I am not sure what to put there (because it varies), will this RegEx work if I am using the same search strings that you typed above:(?s-i)((?<!abc)(?<!xyz)(?<!xxx).)*?\K</span>\s*</p>?