How to delete a character in lines with same beginning and ending, but different in between?
-
I want to delete the [/b] in lines like these::
[m3][c #0A5D00]▸[i] You’d get up early[/i][/b][/c][/m3]
[m3][c #0A5D00]▸[i] We prefer cheese[/i][/b][/c][/m3]
[m3][c #0A5D00]▸[i] They never came[/i][/b][/c][/m3]
Of course there are other lines in the file with the same ending, and I want to leave them intact. for example:
[m3][c #0A5D555]▸[b][i] charity fund[/i][/b][/c][/m3]
What can I do? Please help. -
The first step is to follow the instructions for submitting such questions, found HERE.
-
@Alan-Kilborn Thanks for the instructions. I’ll try to follow them, though I’m not sure whether I can do it correctly.
-
For others reading this conversation: This conversation was continued in “Deleting a group of characters in lines with same beginning and ending, but different in between (re-post)”.
After replies have been made, please do not delete your post. That makes the conversation confusing. A moderator has restored your original post here for context.
You could have just posted a new reply to this conversation, with the template-styled information, without needing a separate topic.
-
Here is the answer you want:
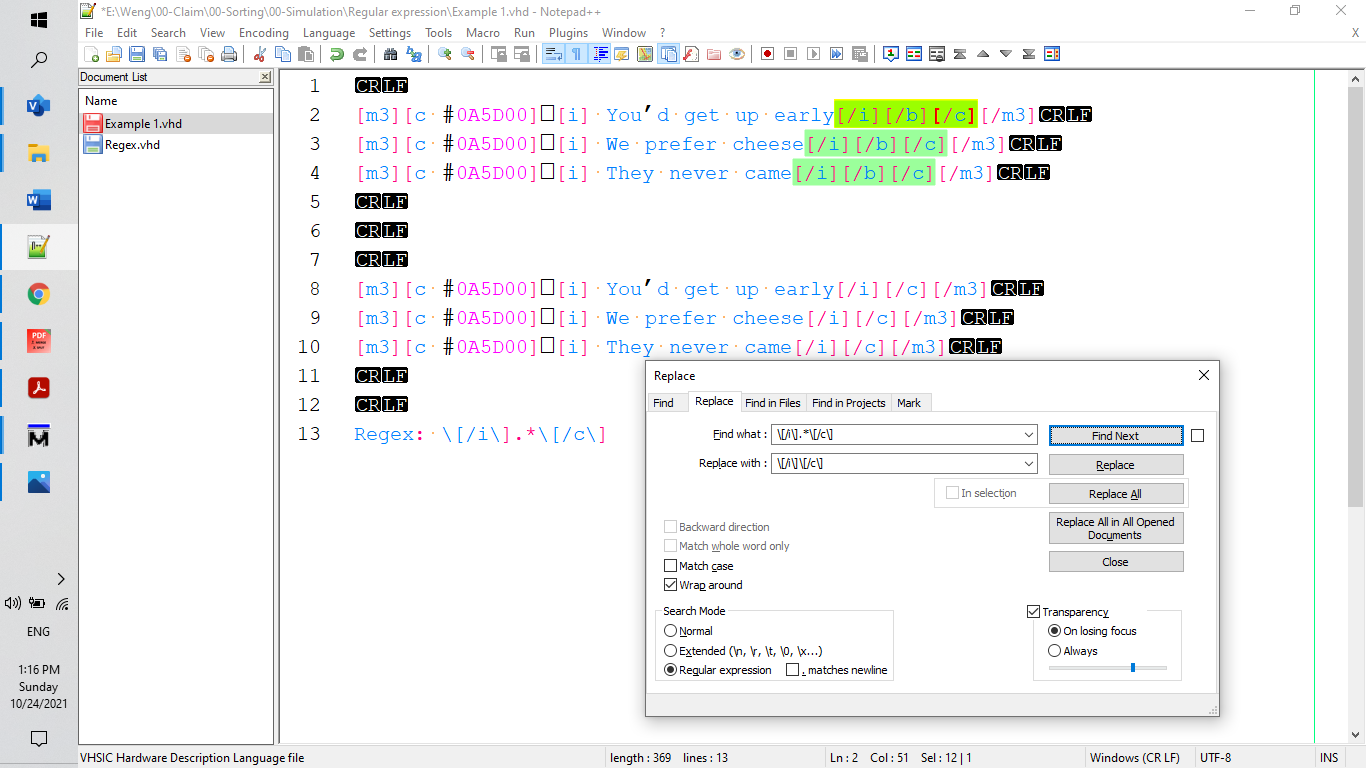
Command is:[/i].*[/c] to search for what you want to find
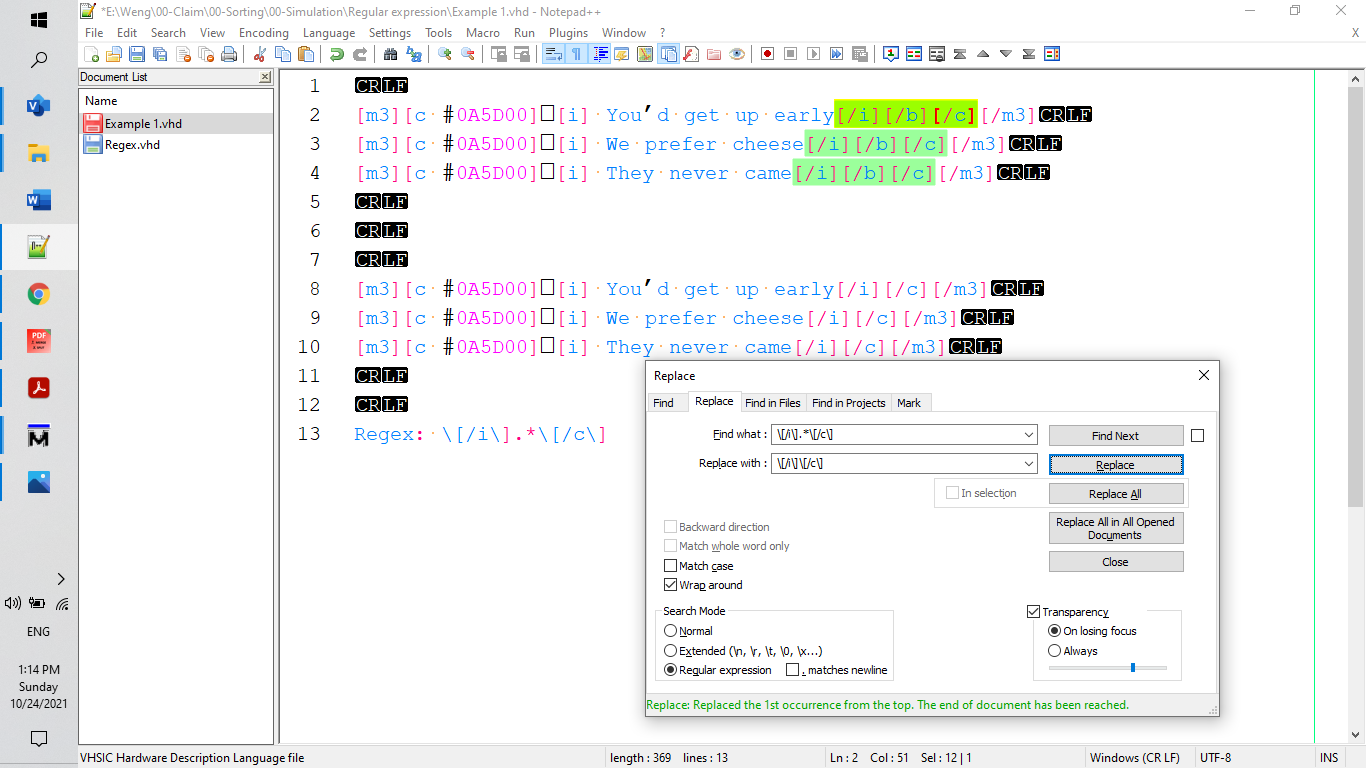
At replace position to enter what you want to replace:
In your situation, replace = [/i][/c] to delete what you want to delete.comment:
[] are metacharacters, if it is used, use '' before ‘[’ to represent ‘[’ character
.: Matches any single character (many applications exclude newlines, and exactly which characters are considered newlines is flavor-, character-encoding-, and platform-specific, but it is safe to assume that the line feed character is included). Within POSIX bracket expressions, the dot character matches a literal dot. For example, a.c matches “abc”, etc., but [a.c] matches only “a”, “.”, or “c”.: Matches the preceding element zero or more times. For example, abc matches “ac”, “abc”, “abbbc”, etc. [xyz]* matches “”, “x”, “y”, “z”, “zx”, “zyx”, “xyzzy”, and so on. (ab)* matches “”, “ab”, “abab”, “ababab”, and so on.
Then use the replace key with item = what you want. In your case just delete “.*” in find command
Tips:
- Before using Regex, at NP++, click View --> Show Simble --> Show All Characters as shown in pictures.
- Before replacing, click “Find Next” and it will show you what you want to identify.
-
@W-TX ,
He already got multiple other working solutions in the other thread that was created.
Though you inadvertently showed another reason for not starting a second copy of the same question: it makes people waste their time answering something that has already been answered.
-
@W-TX Thanks for replying, but it seems you misunderstood my question.
What I really want is to keep back everything except the [/b] element in lines beginning with [m3][c #0A5D00]▸[i], NOT in lines beginning with [m3][c #0A5D55]▸[b][i]. They have the same ending, but different beginning. -
@W-TX Here’s a re-presentation of my question, followng a template suggested by Alan Kilborn.
Fellow Notepad++ Users,
Could you please help me the the following search-and-replace problem I am having?
I want to delete the [/b] in lines with the same beginning and ending, but different characters in between, like these:Here is the data I currently have (“before” data):
[m3][c #0A5D00]▸[i] You’d get up early[/i][/b][/c][/m3] [m3][c #0A5D00]▸[i] We prefer cheese[/i][/b][/c][/m3] [m3][c #0A5D55]▸[b][i] charity fund[/i][/b][/c][/m3] [m3][c #0A5D00]▸[i] They never came[/i][/b][/c][/m3] [m3][c #0A5D55]▸[b][i] board of charity[/i][/b][/c][/m3]Here is how I would like that data to look (“after” data):
[m3][c #0A5D00]▸[i] You’d get up early[/i][/c][/m3] [m3][c #0A5D00]▸[i] We prefer cheese[/i][/c][/m3] [m3][c #0A5D55]▸[b][i] charity fund[/i][/b][/c][/m3] [m3][c #0A5D00]▸[i] They never came[/i][/c][/m3] [m3][c #0A5D55]▸[b][i] board of charity[/i][/b][/c][/m3]To accomplish this, I have tried using the following Find/Replace expressions and settings
• Find What =[m3][c #0A5D00]▸[i]*[/i][/b][/c][/m3]
• Replace With =[m3][c #0A5D00]▸[i]*[/i][/c][/m3]
• Search Mode = all the three, one after another (REGULAR EXPRESSION, then NORMAL, then EXTENDED)
• Dot Matches Newline = NOT CHECKED
I tried the Find What function first, but it didn’t work, and I’m not sure why.
Could you please help me understand what went wrong and help me find the solution?
Thank you. -
The cake is fully baked, wonderful scents are coming out of the kitchen, go to other thread here as mentioned by @PeterJones in his post above:
This conversation was continued in “Deleting a group of characters in lines with same beginning and ending, but different in between (re-post)”.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login