lexing/styling with PythonScript
-
In the Scintilla docs near HERE is found the following:
The styling messages allow you to assign styles to text. If your styling needs can be met by one of the standard lexers, or if you can write your own, then a lexer is probably the easiest way to style your document. If you choose to use the container to do the styling you can use the SCI_SETILEXER command to select NULL, in which case the container is sent a SCN_STYLENEEDED notification each time text needs styling for display.The problematic part here is
SCI_SETILEXERbecause I don’t see aneditor.setILexer()command in the PythonScript docs.There is
editor.setLexer()and I’ve triededitor.setLexer(0)just on a whim, but I don’t think that is what is needed because I don’t appear to be getting theSCINTILLANOTIFICATION.STYLENEEDEDnotifications after I do that.Any hints and help appreciated.
-
Couldn’t you use
ctypes.windll.user32.SendMessageWto send the SCI_SETILEXER message to the Scintilla instance, regardless of whether or not PythonScript plugin implements its own wrapper around that message? (You’ll probably have to do somectypes.windll.user32.FindWindowWand similar calls to find the Notepad++ and child Scintilla hWnds for doing the SendMessage, but Eko’s shared plenty of examples of those in the forum already.)I have avoided delving into the specifics of lexers and iLexers, so they aren’t implemented in my PerlScript yet… but that means I don’t have any lexer-specific advice.
-
@PeterJones said in lexing/styling with PythonScript:
Couldn’t you use ctypes.windll.user32.SendMessageW to send the SCI_SETILEXER
I suppose so, it just seems a bit strange to “resort” to that when all of the other direct support seems to be there. :-)
-
SCI_SETILEXER is a new function introduced for the ILexer5 interface, afaik.
Lexing can still be done, hopefully as I have not tested it since some long time ago, as provided in the examples with PS. -
@Ekopalypse said in lexing/styling with PythonScript:
as provided in the examples with PS
Ah. I didn’t even think to look there, but yes I see some, e.g. ColumnLexer, LogFileLexer. These should get me where I need to go! Thanks, all.
-
I started what I want to do by looking at ColumnLexer and LogFileLexer, as indicated before.
I found that those were a little, well, contrived examples, because they require you to run the script “on” each file that you want to lex. Not very realistic when you want files of a certain extension (not one known by N++) to always be lexed.
So I modified the examples to test for my specific extension, and that sort of worked with the buffer-activated callback logic, but I found that the lexing would occur on the screen view below where my caret is, so I’d have to scroll down to see it. Not very useful.
I noticed that the sample scripts do a pass through the entire document the first time they are run. Since I want to run automatically, this doesn’t work for me, so I had to try to figure out when/how to do this “full scan”.
I settled on setting a property on the document in the buffer-activated callback to indicate that the full scan had already happened (if it had) and then not doing it, or doing it if it had never been done on the document. This cleared up my problem of the lines at my current viewport view not being lexed.
But then I noticed that if I do something that causes my lexed document to be reloaded (such as externally modifying the file), that doesn’t clear the property value I had set earlier, and then my document doesn’t get lexed at all.
So I seem to have the problem of “wanting it all” and yet not being able to achieve it. Maybe this relates to not having a full grasp on how exactly the lexing is done.
I guess as I’m typing this I’m realizing that I’m going to have to post some code if I want help. I can do that, but I have to change it some to hide my data and its format somewhat…TIME GOES BY AS HE CHANGES CODE… Ok, so here’s my “data format”, in a file with an
.szpextension:// this is my log file format: 2.331450 [008] 8F 00 00 25 00 D0 20 02 // I'm a comment! 2.372829 [008] EF D1 44 E6 84 43 0D 35 // I'm a comment! 2.375929 [008] 9F 00 0A 07 01 DE 00 00 // I'm a comment! 2.747191 [008] 5F 02 00 59 0A D2 B5 96 // I'm a comment! 2.747506 [008] CF 0E 0C D6 62 00 00 01 // I'm a comment! 3.090998 [008] CF 90 00 FF FF 00 F5 F5 // I'm a comment! 3.097475 [008] CF 0E 0C D6 62 FF B8 01 // I'm a comment! 3.137851 [008] BF 00 00 00 00 45 69 00 // I'm a comment! 3.418316 [005] 9F 7C 7C 00 00 // I'm a comment! 3.482137 [008] AF 3B 3F F0 3F F0 03 00 // I'm a comment! 3.708105 [008] 8F 00 00 00 00 D0 02 02 // I'm a comment! 3.747221 [008] BF 02 09 AC 00 27 00 00 // I'm a comment! 3.748187 [008] 8F 00 00 00 00 D0 02 02 // I'm a comment! 3.794235 [008] BF 00 00 00 CB 45 6A 00 // I'm a comment! 3.798133 [008] BF 02 09 AC 00 27 00 00 // I'm a comment! 3.856565 [008] FF 00 00 56 0E 1A 80 00 // I'm a comment! 3.858136 [008] AF 3A 3F F0 3F F0 0D 00 // I'm a comment! 17.685254 [007] 95 02 FF 9A 62 86 2F // I'm a comment! 17.686466 [008] 6F 11 00 55 10 00 00 00 // I'm a comment! 17.686797 [008] 6F 33 00 64 10 00 00 01 // I'm a comment! 17.687096 [008] 6F 11 00 64 10 00 00 01 // I'm a comment! 17.687296 [008] 7F 0B 36 04 F6 05 50 6D // I'm a comment! 17.687655 [008] FF 00 00 00 00 00 02 0A // I'm a comment! 17.687935 [003] 22 F1 A0 // I'm a comment! 17.688169 [007] DF 00 00 00 00 00 00 // I'm a comment! 17.688878 [003] CF 0E BA // I'm a comment! 17.689223 [008] EF 51 44 00 78 46 0D 35 // I'm a comment! 17.689352 [008] 4F 61 29 9D 00 00 00 00 // I'm a comment! 17.689630 [003] 91 02 AF // I'm a comment! 17.690542 [008] AF 3B 3F F0 3F F0 03 00 // I'm a comment! 17.691101 [003] A2 02 FF // I'm a comment! 17.691294 [008] 4F 61 29 A5 00 00 00 00 // I'm a comment! 17.691509 [008] AF 3B 3F F0 3F F0 03 00 // I'm a comment! 17.691627 [008] 3F 00 00 00 3E 80 00 00 // I'm a comment! 17.692622 [008] 8F 00 01 23 00 D0 20 01 // I'm a comment! 17.692986 [003] 22 F0 B3 // I'm a comment! 17.693291 [008] BF 01 00 00 00 00 00 00 // I'm a comment! 17.693567 [008] 7F 01 85 00 E6 00 E6 25 // I'm a comment! 17.693770 [008] BF 01 00 00 00 00 00 00 // I'm a comment! 17.695391 [008] FF 00 00 00 00 09 02 0A // I'm a comment! 17.698086 [008] FF 01 5F 02 00 00 00 00 // I'm a comment! 17.699054 [008] FF 00 00 00 00 00 02 1E // I'm a comment! 17.699855 [008] EF 51 44 00 78 46 0D 35 // I'm a comment! 17.701804 [008] FF 00 00 00 00 09 02 0A // I'm a comment! 17.703749 [003] CF 0E AC // I'm a comment! 17.704021 [008] 6F 11 00 55 10 00 00 00 // I'm a comment! 17.705100 [007] DF 00 00 00 00 00 00 // I'm a comment! 17.707857 [008] DF 01 00 2D 00 00 02 01 // I'm a comment! 17.708049 [008] 8F 00 00 00 00 D0 02 02 // I'm a comment! 17.708243 [008] CF 00 00 30 00 00 00 00 // I'm a comment! 17.708367 [008] DF 62 3F 0C 3E 00 BE 24 // I'm a comment! 17.708603 [008] 3F 00 00 00 3E 80 00 00 // I'm a comment! 17.708743 [008] FF 00 00 5E 0E 24 80 00 // I'm a comment! 17.708887 [008] CF 00 18 FF FF 00 E5 E6 // I'm a comment! 17.709061 [008] FF 00 00 5E 00 00 00 00 // I'm a comment! 17.709189 [008] DF 62 3F 0D 06 08 B7 59 // I'm a comment! 17.710623 [008] 5F 02 00 61 0A D2 1F 00 // I'm a comment! 17.722293 [008] 4F 62 2A 18 00 00 00 00 // I'm a comment! 17.722311 [008] EF 51 44 A6 78 46 0D 35 // I'm a comment! 17.760595 [008] DF 62 3F 0C 3E 06 DA 24 // I'm a comment! 19.247839 [008] 9F 4E 27 37 49 52 00 00 // I'm a comment! 19.263558 [008] CF 00 18 FF FF 00 E5 E6 // I'm a comment! 19.269914 [003] CF 0E AC // I'm a comment! 19.271769 [008] 9F 62 4A 37 49 51 0D 0C // I'm a comment! 19.279313 [008] 6F 22 00 64 10 00 00 01 // I'm a comment! 19.292532 [008] CF 00 18 FF FF 00 E5 E6 // I'm a comment! 19.325982 [008] 6F 11 00 64 10 00 00 01 // I'm a comment! 19.326740 [008] 8F 00 00 00 00 D0 02 02 // I'm a comment! 19.327430 [008] EF 34 66 00 00 40 52 04 // I'm a comment! 19.328585 [002] 72 03 // I'm a comment! 19.328935 [007] EF 00 00 00 00 03 03 // I'm a comment! 19.329275 [008] BF 00 00 01 11 45 6A 00 // I'm a comment! 19.329572 [008] 4F 62 2A 23 00 00 00 00 // I'm a comment! 19.330305 [008] FF 00 00 5E 00 00 00 00 // I'm a comment! 19.331285 [008] FF 00 00 5E 00 00 00 00 // I'm a comment! 19.331795 [003] 22 F1 90 // I'm a comment! 19.332246 [008] BF 00 00 00 EF 45 6A 00 // I'm a comment! 19.332458 [008] CF 90 00 FF FF 00 F5 F5 // I'm a comment! 19.332647 [008] 9F 00 0A 07 01 DE 00 00 // I'm a comment! 19.332764 [008] 3F 00 00 00 3E 80 00 00 // I'm a comment! 19.333642 [008] EF 00 00 00 00 00 FF FE // I'm a comment! 19.334515 [008] FF 00 00 00 00 00 01 00 // I'm a comment! 19.334955 [008] CF 0E 0C D6 62 02 10 40 // I'm a comment! 19.335581 [008] DF 00 00 00 00 FF FD 00 // I'm a comment! 19.335864 [008] 8F 00 00 00 00 D0 02 02 // I'm a comment! 19.336225 [008] AF 3B 3F F0 3F F0 03 00 // I'm a comment! 19.336559 [008] FF 00 00 5E 00 00 00 00 // I'm a comment! 19.336873 [008] DF 00 00 00 00 FF FD 00 // I'm a comment! 19.337449 [008] BF 00 00 00 00 45 69 00 // I'm a comment! 19.337692 [008] AF 3B 3F F0 3F F0 03 00 // I'm a comment! 19.338476 [008] CF 90 92 00 00 00 FC FC // I'm a comment! 19.339280 [008] 3F 00 00 00 3E 80 00 00 // I'm a comment! 19.342542 [008] 7F 01 8C 00 E6 00 E6 25 // I'm a comment! 19.343846 [008] 4F 61 29 9E 00 00 00 00 // I'm a comment! 19.345305 [008] 7F 01 8C 00 E6 00 E6 25 // I'm a comment! 19.345333 [008] AF 00 00 00 01 00 02 00 // I'm a comment! 19.345825 [008] 9F 37 00 37 48 53 00 00 // I'm a comment! 19.358343 [008] BF 00 07 08 00 07 00 00 // I'm a comment! 19.358574 [008] CF 00 00 30 00 00 00 00 // I'm a comment! 19.358701 [005] 9F 85 85 00 00 // I'm a comment! 19.358830 [008] 7F 01 94 04 74 04 BA 25 // I'm a comment! 19.358953 [008] EF 2F 3A FF FF 90 B6 04 // I'm a comment! 19.359166 [008] CF 0E 0C D6 62 02 00 40 // I'm a comment! 19.359290 [008] EF 33 E7 00 00 51 00 04 // I'm a comment! 19.371638 [008] FF 00 00 00 00 00 02 17 // I'm a comment!And here’s what I want it to look like when it is all prettily lexed:

And here’s my script that (mostly) achieves it:
# -*- coding: utf-8 -*- from Npp import * import re try: # on first run this will generate a NameError exception Szpfile_lexer().main() except NameError: class Szpfile_lexer(object): DEFAULT_STYLE = 0 # the current default style COMMENT_STYLE = 60 RED_STYLE = 61 BOLD_STYLE = 62 ORANGE_STYLE = 63 STYLE_TABLE = [ # index is regex group number -1, # we don't use group 0 COMMENT_STYLE, # group 1 : //... RED_STYLE, # group 2 : timestamp BOLD_STYLE, # group 3 : length of data ORANGE_STYLE, # group 4 : data bytes COMMENT_STYLE, # group 5 : //... ] SZP_LINE_REGEX = r'^\s*(?:(//[^\r\n]*)|(?:(\d+\.\d+)\s+\[(\d{3})\]\s+([0-9A-F]{2}(?:\s[0-9A-F]{2})*)\s+(//[^\r\n]*)))' def __init__(self): editor.callbackSync(self.styleneeded_callback, [SCINTILLANOTIFICATION.STYLENEEDED]) notepad.callback(self.bufferactivated_callback, [NOTIFICATION.BUFFERACTIVATED]) def do_lexing(self, start_pos, end_pos): #print('start_pos:', start_pos, 'end_pos:', end_pos) # first everything will be styled with default style if end_pos - start_pos >= 0: editor.startStyling(start_pos, 0) # the second parameter is unused editor.setStyling(end_pos - start_pos, self.DEFAULT_STYLE) for line in range(editor.lineFromPosition(start_pos), editor.lineFromPosition(end_pos)): line_start_pos = editor.positionFromLine(line) line_contents = editor.getLine(line).rstrip('\r\n') if len(line_contents) > 0: m = re.match(self.SZP_LINE_REGEX, line_contents) if m: #print(m.span(0)) for j in range(len(self.STYLE_TABLE) - 1): k = j + 1 if self.STYLE_TABLE[k] == -1: continue if m.group(k) != None: styling_starting_pos = line_start_pos + m.span(k)[0] length = m.span(k)[1] - m.span(k)[0] editor.startStyling(styling_starting_pos, 0) # the second parameter is unused editor.setStyling(length, self.STYLE_TABLE[k]) if k == 1: break # if we have group 1, we know we WON'T have the rest of the groups! # this needs to stay and to be the last line, to signal scintilla we are done! editor.startStyling(end_pos, 0) # the second parameter is unused def init_configured_styles(self): if editor.getLexer() != LEXER.CONTAINER: editor.setLexer(LEXER.CONTAINER) editor.styleSetFore(self.COMMENT_STYLE, (0, 128, 0)) editor.styleSetItalic(self.COMMENT_STYLE, True) editor.styleSetBold(self.BOLD_STYLE, True) editor.styleSetFore(self.RED_STYLE, (255, 0, 0)) editor.styleSetUnderline(self.RED_STYLE, True) editor.styleSetFore(self.ORANGE_STYLE, (255, 128, 0)) def is_lexer_doc(self): f = notepad.getCurrentFilename() return True if len(f) > 4 and f[-4:].lower() == '.szp' else False def styleneeded_callback(self,args): if self.is_lexer_doc(): startPos = editor.getEndStyled() lineNumber = editor.lineFromPosition(startPos) startPos = editor.positionFromLine(lineNumber) endPos = args['position'] self.do_lexing(startPos, endPos) def bufferactivated_callback(self,args): if self.is_lexer_doc(): self.init_configured_styles() p = editor.getPropertyInt('szp_lexed', 0) if p == 0: editor.setProperty('szp_lexed', 1) self.do_lexing(0, editor.getLength()) Szpfile_lexer()So here’s one way to generate a problem: If I have line 25 at the top of my editing window and I do a File > Reload from disk command, I get this:
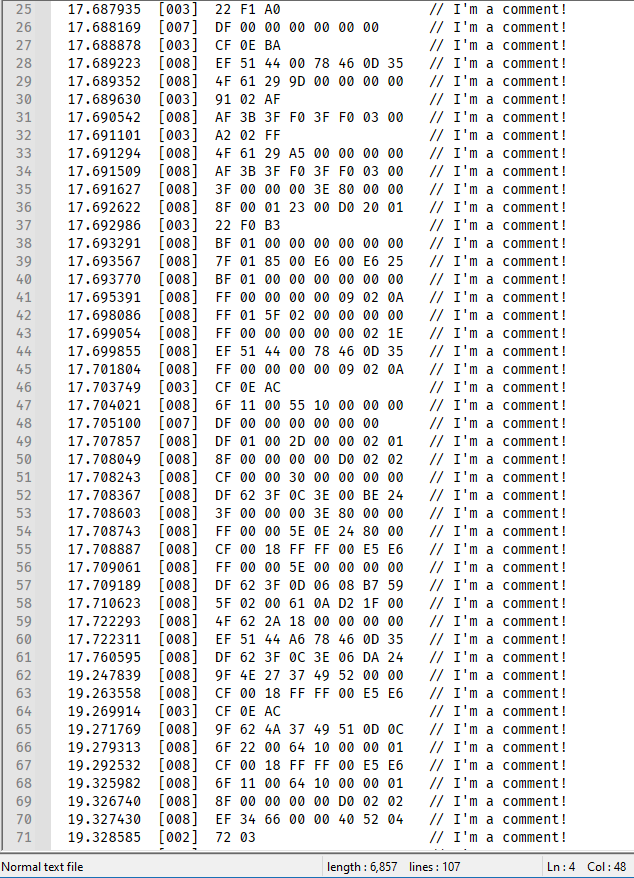
But if I then scroll down some, I see:

So the lexing kicks in at some point…
So long-story-very-long, the bottom line in what I’m asking, is, How can I make this super-robust, given what I want to achieve (a real world thing, not a contrived example like what I started with)?
-
It appears that in my original posting, my code listing was a victim of the forum bug where it steals a backslash-then-bracket combination and removes the backslash. This will cause the code to fail to work correctly. In the code I’m about to post below, I will try to compensate for the forum bug and get it right. BUT, geez, it sure would be nice if that forum bug could be fixed – I’d even take fixing that over fancy new features being added.
Ok, so I wanted to post an update to this to show that, with the help of someone else (thank you!), I was able to obtain the robustness I was looking for in this styling code. Or at least after a few days of testing it feels robust.
The key change to make it work was really in the buffer-activated callback function, although there were some slight changes to the other parts of the code. Anyone interested in the changes should diff the original and changed versions.
Anyway, here’s the new code, which can serve as a “real world” example of how to do custom lexing with a PythonScript:
# -*- coding: utf-8 -*- from Npp import * import re try: # on first run this will generate a NameError exception Szpfile_lexer().main() except NameError: class Szpfile_lexer(object): DEFAULT_STYLE = 0 # the current default style COMMENT_STYLE = 60 RED_STYLE = 61 BOLD_STYLE = 62 ORANGE_STYLE = 63 STYLE_TABLE = [ # index is regex group number -1, # we don't use group 0 COMMENT_STYLE, # group 1 : //... RED_STYLE, # group 2 : timestamp BOLD_STYLE, # group 3 : length of data ORANGE_STYLE, # group 4 : data bytes COMMENT_STYLE, # group 5 : //... ] SZP_LINE_REGEX = r'^\s*(?:(//[^\r\n]*)|(?:(\d+\.\d+)\s+\\[(\d{3})\\]\s+([0-9A-F]{2}(?:\s[0-9A-F]{2})*)\s+(//[^\r\n]*)))' def __init__(self): editor.callbackSync(self.styleneeded_callback, [SCINTILLANOTIFICATION.STYLENEEDED]) notepad.callback(self.bufferactivated_callback, [NOTIFICATION.BUFFERACTIVATED]) self.previous_buffer_id = None def do_lexing(self, start_pos, end_pos): #print('start_pos:', start_pos, 'end_pos:', end_pos) # first everything will be styled with default style if end_pos - start_pos >= 0: editor.startStyling(start_pos, 0) # the second parameter is unused editor.setStyling(end_pos - start_pos, self.DEFAULT_STYLE) for line in range(editor.lineFromPosition(start_pos), editor.lineFromPosition(end_pos)): line_start_pos = editor.positionFromLine(line) line_contents = editor.getLine(line).rstrip('\r\n') if len(line_contents) > 0: m = re.match(self.SZP_LINE_REGEX, line_contents) if m: #print(m.span(0)) for k in range(1, len(self.STYLE_TABLE)): if self.STYLE_TABLE[k] == -1: continue if m.group(k) != None: styling_starting_pos = line_start_pos + m.span(k)[0] length = m.span(k)[1] - m.span(k)[0] editor.startStyling(styling_starting_pos, 0) # the second parameter is unused editor.setStyling(length, self.STYLE_TABLE[k]) if k == 1: break # if we have group 1, we know we WON'T have the rest of the groups! # this needs to stay and to be the last line, to signal scintilla we are done! editor.startStyling(end_pos, 0) # the second parameter is unused def init_configured_styles(self): if editor.getLexer() != LEXER.CONTAINER: editor.setLexer(LEXER.CONTAINER) editor.styleSetFore(self.COMMENT_STYLE, (0, 128, 0)) editor.styleSetItalic(self.COMMENT_STYLE, True) editor.styleSetBold(self.BOLD_STYLE, True) editor.styleSetFore(self.RED_STYLE, (255, 0, 0)) editor.styleSetUnderline(self.RED_STYLE, True) editor.styleSetFore(self.ORANGE_STYLE, (255, 128, 0)) def is_lexer_doc(self): f = notepad.getCurrentFilename() return True if len(f) > 4 and f[-4:].lower() == '.szp' else False def styleneeded_callback(self,args): if self.is_lexer_doc(): startPos = editor.getEndStyled() lineNumber = editor.lineFromPosition(startPos) startPos = editor.positionFromLine(lineNumber) endPos = args['position'] self.do_lexing(startPos, endPos) def bufferactivated_callback(self,args): if self.is_lexer_doc(): self.init_configured_styles() p = editor.getPropertyInt('szp_lexed', 0) if p == 0 or self.previous_buffer_id == args['bufferID'] or self.previous_buffer_id is None: editor.setProperty('szp_lexed', 1) self.do_lexing(0, editor.getLength()) self.previous_buffer_id = args['bufferID'] Szpfile_lexer() -
Hello, @alan-kilborn
Independently from your Python script, I think that, regexlly speaking, your overall regex could be simplified as :
^\s*(?:(\d+\.\d+)\s+\\[(\d{3})\\]\s+((?:[0-9A-F]{2}\s)+))?\s*(//[^\r\n]*)Of course, in case of a match of a single comment, in a line, groups
1,2and3are empty and group4contains the comment text !and, if your
Pythonscript support the(?-s)notation, the below regex could be used :(?-s)^\s*(?:(\d+\.\d+)\s+\\[(\d{3})\\]\s+((?:[0-9A-F]{2}\s)+))?\s*(//.*)Finally, if your records of your log are just mono-line and not like below :
2.331450 [008] 8F 00 00 25 00 D0 20 02 // I'm a comment!The final try, below, could be enough !
(?-s)^\h*(?:(\d+\.\d+)\h+\\[(\d{3})\\]\h+((?:[0-9A-F]{2}\h)+))?\h*(//.*)Best Regards,
guy038
-
Hello @guy038
Well…yes. But as I stated above, my data file format isn’t my real format, I had to hide it somewhat so that I could the data. I just “carved up” my original regex quickly so that I could perform this hiding. Thus, optimizing the regex is of limited value. But thanks anyway!
-
@guy038 said in lexing/styling with PythonScript:
…and, if your Python script support the (?-s) notation…
So just a note on that comment:
There are a couple of ways to use regular expressions in a PythonScript.
One way is by using the PythonScript-specific functions, e.g.
editor.research(). When you use this function, you are operating on editor data only(!) and you are using a Boost-compatible regular expression.The other way is to use Python’s (e.g.)
re.search()function. This time, you are using Python’s own regex engine and you are acting on data that you specify, i.e., it cannot be data from the editor, directly. It can, of course be data that is copied from the editor into a Python variable.The second means described above is what my demo script above is using. Since Python’s regex flavor doesn’t accept
(?-s)syntax, it isn’t possible to use it.Of course, the script could be reworked somewhat, in order to use the first method of data access, above, and then
(?-s)would be available. -
 A Alan Kilborn referenced this topic on
A Alan Kilborn referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login