Notepad++ encoding auto-detect potential problems
-
So there was an ISSUE that came up recently that I did a bit of trolling on. :-)
What came out of it was that Notepad++, when loading files, can get a file’s encoding wrong. Of course I’d heard of this issue before, but I never gave it a deeper dive. The issue does seem relatively rare, but apparently detection of a file’s encoding is a difficult thing, with no clear roadmap of a fix in Notepad++.
Basically what happens is that a user can create and save a UTF-8 file (BOM-less), and when this file is closed and later reloaded, its encoding is detected by Notepad++ as something other than UTF-8. This causes (silent) corruption of the file when further edits/saves happen. It is easy for this to go unnoticed if you are opening a file to make changes in an area of the file that is far away from the point of corruption, and that area contains data that is simply normal “A-z” type text. (I mention UTF-8, but I suppose it is possible for this poor encoding autodetect to happen with other encodings as well.)
Being someone that primarily works with UTF-8 files, but occasionally has a need to work with files with older encodings, I like Notepad++'s auto-detection of file encoding. But…not so much if it is subject to getting it wrong.
So I thought, what if I have Notepad++ inform me when it loads a file that is NOT UTF-8? Thus normally I won’t be “bothered”, but if a file encoding is detected as non-UTF-8, I’ll get a popup when the file is loaded. At that point I can ask myself, is this file supposed to be in the encoding it is indicating? If so, all is good, and I dismiss the popup and continue on. If not, well, then I can take appropriate measures to get my file and Notepad++ on the same “page” (“codepage” pun fully intended) concerning its encoding.
I implemented this with a Pythonscript, I call it
EncodingDifferentThanUtf8Alert.py:# -*- coding: utf-8 -*- from __future__ import print_function from Npp import * import inspect import os import NotepadGetStatusBar class EDTU8A(object): def __init__(self): self.already_warned_paths_list = [] # only warn once per file self.this_script_name = inspect.getframeinfo(inspect.currentframe()).filename.split(os.sep)[-1].rsplit('.', 1)[0] self.ngsb = NotepadGetStatusBar.NGSB() notepad.callback(self.bufferactivated_notify, [NOTIFICATION.BUFFERACTIVATED]) notepad.callback(self.filebeforeclose_notify, [NOTIFICATION.FILEBEFORECLOSE]) def bufferactivated_notify(self, args): f = notepad.getBufferFilename(args['bufferID']) # can't call notepad.getEncoding() here because it will return Npp.BUFFERENCODING.COOKIE for UTF-8 files and some non UTF-8 files!! # for more info, see https://community.notepad-plus-plus.org/topic/20142/what-is-bufferencoding-cookie # to solve this problem, read what N++ thinks the encoding is off of the status bar encoding_on_status_bar = self.ngsb.get_statusbar_by_section(STATUSBARSECTION.UNICODETYPE) if encoding_on_status_bar != 'UTF-8' and f not in self.already_warned_paths_list: notepad.messageBox('The encoding for:\r\n\r\n{f}\r\n\r\nis:\r\n\r\n{e}'.format(f=f, e=encoding_on_status_bar), self.this_script_name) self.already_warned_paths_list.append(f) def filebeforeclose_notify(self, args): f = notepad.getBufferFilename(args['bufferID']) if f in self.already_warned_paths_list: self.already_warned_paths_list.remove(f) if __name__ == '__main__': EDTU8A()I linked the script to auto-load when Notepad++ starts by putting the following in my user
startup.pyfile:import EncodingDifferentThanUtf8Alert edtu8a = EncodingDifferentThanUtf8Alert.EDTU8A()Note that this script uses another script, referenced HERE, so that script needs to be present as well.
Now when I open a file, if its encoding is not detected as UTF-8, I’ll get an alert popup such as the following:
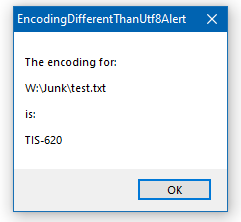
-
@alan-kilborn said in Notepad++ encoding auto-detect potential problems:
Now when I open a file, if its encoding is not detected as UTF-8, I’ll get an alert popup such as the following:
ABSOLUTELY BRILLIANT!
-
@michael-vincent said in Notepad++ encoding auto-detect potential problems:
ABSOLUTELY BRILLIANT!
I don’t know about that. :-)
Desperate times call for desperate measures.
I’d much rather be able to count on N++ always getting it right !! :-( -
@alan-kilborn said:
but apparently detection of a file’s encoding is a difficult thing
Impossible is more accurate. Especially for codepage (character sets) it is a pure guess. It works better for html and other internet files which may explicitly define the encoding within the content. Despite the obvious “chicken and egg” problem.
As was said many times before, Notepad++ should have an option to be utf-8 biased. First try to decode a file as UTF-8 and only if it fails, because file contains byte sequences that are invalid for utf-8, move to auto detection. Perhaps the auto detection already works that way. I don’t know.
The next thing should be for a user to define acceptable encodings that will limit auto detection space and warn for files that do not match anything in the set. This would be a generalization of @Alan-Kilborn neat python trick.
It is unhealthy to work with multiple encodings.
Working with utf-8 and some other 16 bit encoding when switching between Linux and Windows is quite common. Auto detection is unlikely to confuse 8 bit encoding with 16 bit encoding.
Working with multiple languages (spoken not software) can unfortunately happen with multiple similar encodings although it shouldn’t. -
 A Alan Kilborn referenced this topic on
A Alan Kilborn referenced this topic on
-
A Alan Kilborn referenced this topic on
-
@gstavi said in Notepad++ encoding auto-detect potential problems:
Auto detection is unlikely to confuse 8 bit encoding with 16 bit encoding.
Yes, I don’t really have concerns about Notepad++ confusing these… the concern is confusion between BOMless (the usual case) UTF-8 and “older” character set encodings.
-
@gstavi said in Notepad++ encoding auto-detect potential problems:
Notepad++ should have an option to be utf-8 biased. First try to decode a file as UTF-8 and only if it fails, because file contains byte sequences that are invalid for utf-8, move to auto detection.
I like that. :-)
Perhaps the auto detection already works that way. I don’t know.
My guess is that it isn’t currently that way, or it is that way and there’s a bug with it.
The next thing should be for a user to define acceptable encodings that will limit auto detection space and warn for files that do not match anything in the set.
This is also a very good idea.
-
A Alan Kilborn referenced this topic on
-
I see at Github that Notepad++ can have a preference setting stored not to “auto detect encoding”. The effect seems to be that a file is treated as “UTF-8 without BOM”, including your “test.txt” file.
Also in https://npp-user-manual.org/docs/command-prompt/
launch settings now exist to choose a different location of stored settings (allowing alternative settings,), to launch a second or third Notepad++ window when one is open already, which may or may not have independent settings, and to set a “language” (programming language) and “localization” (whose effect I don’t know). So you could perhaps run “normal” Notepad++ alongside “only UTF-8” Notepad++.
Also, option: -qf=“D:\path to\file”
“Launch ghost typing to display a file content”
types the file into the open or “new 1” tab possibly treating any file as UTF-8 - it does not mutilate your “test.txt”. However, this is slow and it does not really solve any problem. The “Encoding” menu does not seem to help, either.And none of this means that there isn’t a bug. On the other hand… I expect it’s possible to create a text file which really can’t have its encoding auto detected. Strictly, without assuming an encoding first, you can’t interpret a file.
-
 R Robert Carnegie referenced this topic on
R Robert Carnegie referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login