Regex: Show the string result from searching ALL FILES, between 2 parts
-
maybe @guy038 has a better aproach
-
It sounds like you don’t realize that your task requires two phases and that you are only doing the first.
First phase gathers all lines that contain the text of interest into a search results area. I think you’ve achieved this. Copy these results into a new editor file.
The second task is to do a find & replace on this new file, stripping everything but the file names you care about. Do you know how to do replacement? Have you spent a little time with https://npp-user-manual.org/docs/searching/ and tried a few simple cases?
Also, I see your look-behinds and look-aheads contain characters that you want treated as literals but are actually regex directives. It may be that by luck this was not causing you a problem (because files you were searching probably had no text that would produce false matches). But to be safe you should surround some text with
\Q&\E(the regex doc calls this “verbatim mode” or “quoted”), thus:(?s)(?<=\Q <a href="https://website.com/en/\E).*?(?=\Q.html"><img src="index_files/flag_lang_en.jpg\E) -
@neil-schipper said in Regex: Show the string result from searching ALL FILES, between 2 parts:
Do you know how to do replacement?
Here is some homework for you, in case someone else doesn’t come save you with a complete solution.
Using a regex, convert:
big red car big blue car big black car big green carto
red blue black greenIf you can figure this out, you’ll be 5% along the way of being a regex master, able to solve many problems on your own.
-
@neil-schipper said in Regex: Show the string result from searching ALL FILES, between 2 parts:
in case someone else doesn’t come save you with a complete solution.
This may be unlikely as the OP is a “repeat regex asker” offender. :-)
-
@alan-kilborn said in Regex: Show the string result from searching ALL FILES, between 2 parts:
the OP is a “repeat regex asker” offender. :-)
Well, you and @PeterJones and @Ekopalypse and @guy038 and @terry-r are all serious repeat offenders of the “don’t spoil 'em rotten” rule.
I’ve been guilty too but I’m trying to reform.
-
But to be safe you should surround some text with
\Q&\E(the regex doc calls this “verbatim mode” or “quoted”), thus:(?s)(?<=\Q <a href="https://website.com/en/\E).*?(?=\Q.html"><img src="index_files/flag_lang_en.jpg\E)@neil-schipper thank you sir. I test your regex, but it gives the same result as my regex. So, If I search in “All Files” with your regex, the result is not only the english part:
quo-vadis, but all the links to all languages folder. The same as my regex result.It is king of tricky…hard to find a solution.
-
On the data you’ve shown, @Neil-Schipper 's regex matches the desired result – I tried it.
If you have a case where it doesn’t, perhaps you should show that data.
-
@alan-kilborn OK,
BUT how can I copy all results (from each of the html) into a new notepad++ file? Because, If I try to search in the folder with “Find in Files” option, cannot do that.
So, as to test my idea. Please try to make 2 html/txt file with my content from the beginning of my post. Then try to search and copy with the regex (“Find in Files” ) only the result I want, so I can obtain something like this:
quo-vadis
quo-vadisYou will see that this is not possible with my regex or with @neil-schipper regex
-
@robin-cruise said:
So, If I search in “All Files” with your regex, the result is not only the english part …
You did not read my first post carefully.
You must understand that your task requires several steps.
Really.
Several steps.
There is no regex that you can use in a “Find in Files” that will output a list of the /en/ filenames as you require.
There is
no regex
that you can use in a “Find in Files”
that will output a list of the /en/ filenames as you require.You have succeeded in doing the first step.
You must learn to do the second step.
Before doing the second step, start a new empty file, copy text from Search Results (pane or window) into this new file. Can you do this?
After that, a new Find & Replace must be carried out.
Before learning how to do that, let’s look at the homework I gave.
The parts of the regex docs that are important for the homework and your problem are:
Capture Groups and Backreferences (subset) ⇒ Numbered Capture Group: Parentheses mark a subset of the regular expression, also known as a subset expression or capture group. The string matched by the contents of the parentheses (indicated by subset in this example) can be re-used with a backreference or as part of a replace operation Substitutions $ℕ, ${ℕ}, \ℕ ⇒ Returns what matched the ℕth subexpression (numbered capture group), where ℕ is a positive integer (1 or larger).Now try each of these find and replace operations on the homework text. (You can use Undo = Ctl-z after each operation):
Find:
(big) red car
Replace with:$1and alsoZZ$1ZZand alsoZZ $1 ZZFind:
(big) (red) (car)
Replace with:\3and alsoZZ \2 ZZand alsoZZ$3ZZ ZZ$2ZZ$1ZZand also\3\2\1and also${3} ${2} ${1}and also${2} ${2} ${3} ${3} ${1}Try making a very small change to Find text and see what happens.
Try making a very small change to the Replace text and see what happens.
Make a good effort.
If you have trouble, give examples of what is not working the way you expect.
-
@neil-schipper super, yes, I got it.
I copy all results into a new text file with mine or yours regex.
FIND:
.*((?s)(?<=FIRST-PART).*?(?=SECOND-PART)).*
FIND:.*((?s)(?<=\QFIRST-PART\E).*?(?=\QSECOND-PART\E)).*In my case:
FIND:
.*((?s)(?<= <a href="https://website.com/en/).*?(?=.html"><img src="index_files/flag_lang_en.jpg)).*REPLACE BY:
\1\3 -
@neil-schipper said in Regex: Show the string result from searching ALL FILES, between 2 parts:
copy text from Search Results (pane or window) into this new file.
There are 2 ways to do this, depending on whether or not you need information about the files to carry over in the copy.
This method will get you the search/file/line info along with the lines-of-match:
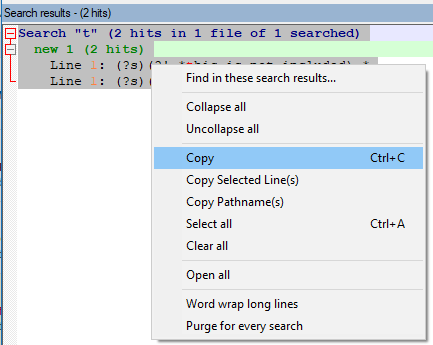
will get:
Search "t" (2 hits in 1 file of 1 searched) new 1 (2 hits) Line 1: (?s)(?!.*this_is_not_included).* Line 1: (?s)(?!.*this_is_not_included).*
This method will get you only the line data of the match:
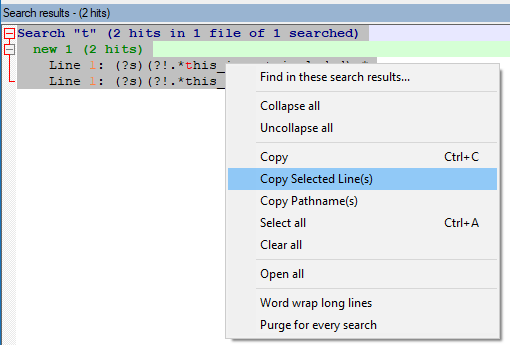
will get:
(?s)(?!.*this_is_not_included).*Note that in the second example, since there are 2 results but the matched lines are the same line, only ONE copy of the line data is put into the clipboard.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login