can't find ASCII characters !
-
@neculai-i-fantanaru
Is there a question here?
-
@alan-kilborn is an observation. :)
I wonder if you have encountered this problem before and how can it be solved?
-
@neculai-i-fantanaru said in can't find ASCII characters !:
I wonder if you have encountered this problem before and how can it be solved?
You are going to have to tell us what the problem is, before we can offer solutions.
-
@neculai-i-fantanaru
If (like me) you don’t mind hacking until you get things to do what you want, enableEdit | Character Panel, and, in the Find dialog change the mode to Extended, and use the\xformat with ascii codes (for ex.\31to find ‘1’, and\41to find ‘A’).If you want an understanding of how unconventional characters are encoded and detected (and don’t mind doing some reading), use the magnifier icon at the top of this page and search for
character convertand you’ll find some good discussions on these topics.A good skill to develop is how to ask a focused question. Images are great but you’re making the reader have to guess what you’re after.
-
@neil-schipper said in can't find ASCII characters !:
(for ex. \31 to find ‘1’, and \41 to find ‘A’)
You mean,
\x31will match1and\x41will matchA. Without thex, your examples are wrong.@Neculai-I-Fantanaru ,
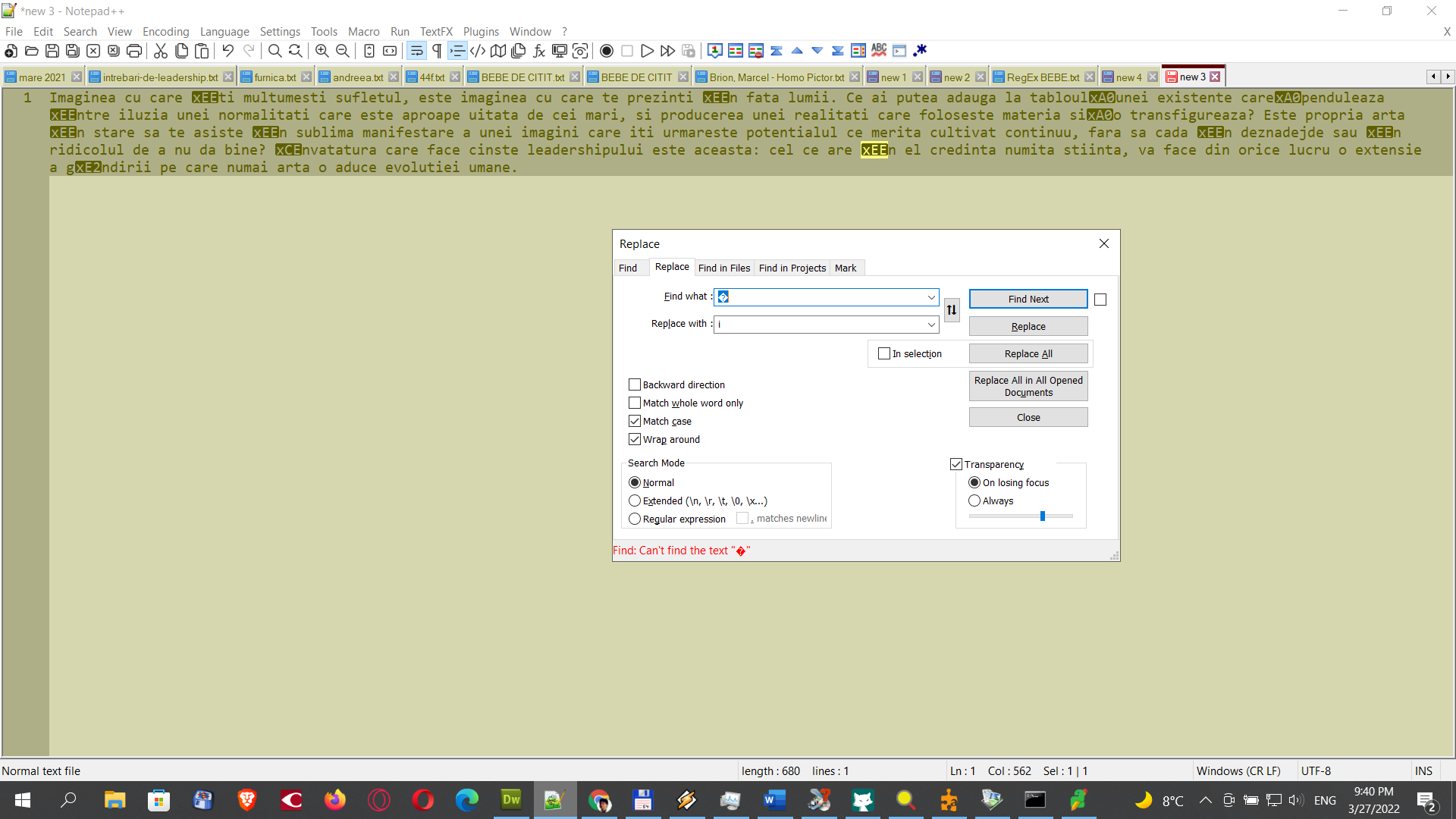
Your subject of “can’t find ASCII characters” is a misphrasing of the problem you are having. The problem is that you have selected a non-ASCII character (not in the 7bit range; all ASCII characters are 7bit; anything in the 128-255 is non-ASCII, either part of the badly named “extended ASCII”, or one of the ANSI-style encodings which uses ASCII as the first 128 characters and a well-defined character in each of the other 128 positions, depending on which character set it came from). In fact, it is a byte that is not a valid UTF-8 character as currently encoded (specifically, the
xEEin a black box, which represents the byte 0xEE).Your status bar shows that Notepad++ was reading the file as a UTF-8 file, in which the byte 0xEE is not a valid character by itself; the byte 0xEE in a UTF-8 file is supposed to be the first byte of a three-byte sequence: the first byte will be somewhere between 0xE0 and 0xEF, and the second and third bytes must be in between 0x80 thru 0xBF. The sequence Notepad++ found was 0xEE followed by an
n(in the one that’s highlighted yellow in your screenshot), which is 0x6E. The byte sequence 0xEE 0x6E is not valid UTF-8 (guesswork on what it really is, in a little bit). So you misunderstood the file when you told Notepad++ to interpret it as UTF-8, or Notepad++ mis-guessed that you wanted it to be interpreted as UTF-8, or the file was meant to be UTF-8 but has errors of some sort.If your goal is to take that character, and replace it with an
i, it is possible to do. But when you selected the “charcter” xEE, which isn’t a real character, Notepad++ couldn’t find it. Instead, if you switched to Regular Expression mode, and searched for\xEE, as @neil-schipper hinted, it will match that byte, even though it isn’t a valid character.However, I think you are going about this wrong. You should just tell Notepad++ what character set was really used, rather than letting Notepad++ think that your file was UTF-8.
When I typed your first three wordsImaginea cu careinto Google translate, it said it was Romanian for “The image with which…”. Looking up Romanian characters sets, I see it might be ISO 8859-2, in which case the xEE might beî, which would beImaginea cu care îti multumesti sufletulwhich Google says means “The image with which you satisfy your soul”, which might be a valid phrase, so it might be that your file is actually ISO 8859-2. Alternately, 8859-16 also has the same character at codepoint 0xEE. And really, even 8859-1 hasîat that codepoint. (And since you want to replace it with ani, that seems like I might be on the right track.)Assuming your file is really 8859-2, to “fix” Notepad++'s interpretation, just go to the Encoding menu, and first choose ANSI, so that it’s not trying to read those bytes
- Original Interpretation:

- Encoding menu, ANSI:
 =>
=> 
And now it will probably be correct. - If you have other characters that weren’t interpreted correctly, then it didn’t pick the right character set for your ANSI file, so you might go to Encoding > Character Set > Eastern European > ISO 8859-2 or some other
At this point, if you want to save the file as UTF-8 (which I recommend, because that is more universal), then go to Encoding > Convert to UTF-8 (not to be confused with **Encoding > UTF-8, which will just get you back to the wrong interpretation that you showed above):
It will still show the right characters,

but once you save, theîwill be represented on disk as the bytes 0xC3 0xAE, which is the correct way to encodeU+00EE, and Notepad++ should interpret it correctly from then on out.If you are going to deal with multi-lingual texts in the modern era, especially with texts that are not western-European in origin, you unfortunately still have to go back and learn the old 1980s style character sets, because so many applications still foolishly use the character set encodings as their primary file format, despite the fact that UTF-8 has existed for decades, and is a much more universal way of encoding the files in an unambigous manner. You need to understand what the common sets are for your documents, and know how your tools will allow you to interact with those ancient encodings. It is worth your time, because you aren’t always going to find someone like me who will write up multi-paragraph answers, with lots of extra research, just to help you read a file correctly.
- Original Interpretation:
-
@peterjones said:
You mean, \x31 will match 1 and \x41 will match A. Without the x, your examples are wrong.
You’re right. It was
\x61typo on my part.I also underestimated, again, the willingness of folks such as yourself to, as you say,
write up multi-paragraph answers, with lots of extra research, just to help…
a poster who hasn’t constructed even a sentence or two describing what he’s starting with and what he’s hoping to achieve, and who appears to be at the shallow end of the learning curve for this topic.
If the info in your reply were in an FAQ about non-Western charsets, or better, in a chapter in the manual, wouldn’t the overall effort on your part, compared to the effort of authoring all these individualized explanations (over years) be considerably less?
-
@neil-schipper said in can't find ASCII characters !:
If the info in your reply were in an FAQ about non-Western charsets, or better, in a chapter in the manual, wouldn’t the overall effort on your part, compared to the effort of authoring all these individualized explanations (over years) be considerably less?
Whilst I would agree in principle about adding as a FAQ as these extensive replies by @peterjones are often very enlightening, the issue will likely be that it will fall on deaf ears.
How often have we had to tell posters to “format their post” especially their example data. And that is after they post in the Help wanted section which has a “Please read this before posting” pinned to the start. And that refers them to other posts which will help them understand why.
Personally, I think those needing help are so fixated on getting their post into this forum they don’t put any thought into how that initial post might read to those wanting to help. I could probably count on one hand those that have fallen into this situation, but after being asked to follow the FAQs have ACTUALLY done so. Most still persist on trying to get help after we ask them to read the FAQ posts, but never comply.
So back to the idea of adding this (with a generalised subject matter) to a FAQ, I think that as this subject matter doesn’t appear to occur often it may not be worthwhile. If we put in FAQ on every subject matter we run the risk of having so many FAQs, first time posters will not attempt to find info before posting. Not that they do now anyways for the most part. Additionally, first time posters often have no idea what the real problem is, just that what they see on screen isn’t what they expected. It’s the seasoned members here who can elicit the right information from posters by asking the right questions.
Terry
-
good day, to all. Thank you for answers.
The problem is: what if I have several files? Should I convert all to UTF-8 or UTF-8-BOM ? How can I do that ?
-
@neculai-i-fantanaru ,
what if I have several files?
Notepad++ is meant as a text editor, not as a bulk file-encoding converter. There are free off-the-shelf bulk converters, like
iconv. (This post has a link to iconv for windows, and shows an example of how to use it to convert from ISO 8859-2 to UTF-8, which may be exactly what you need.)Alternately, if you have the PythonScript plugin, you could write a script which would go through every open file and run the “Encoding” menu sequences that I showed earlier on each open file; or you could do a script which would open each file, do the conversion, save, and close the file. But to do that, you’d have to have at least a slight familiarity with Python (or other similar programming languages, and be willing to look up the specific syntax for Python, which is how I taught myself basic Python using PythonScript plugin and my general programming knowledge from other languages), and have to be able to read the PythonScript documentation to try to find how to use the Notepad++-specific python syntax that the plugin provides.
-
@guy038 put this 2 formulas, that are very good.
iconv -f ISO-8859-2 -t UTF-8 Test.txt > Test_ICONV.txticonv -f WINDOWS-1250 -t UTF-8 Test.txt > Test_2.txtBut, for multiple files, for example a directory with 345 text files, what is the formula in this case with iconv? Can anyone tell?
-
@neculai-i-fantanaru said in can't find ASCII characters !:
what is the formula in this case with iconv? Can anyone tell?
Did you see the line I had in the exact post I linked – the one written by me?
FOR %f in (*.srt) do @( iconv -f ISO-8859-2 -t utf-8 "%f" > "%~nf.utf8%~xf" )In your case, just switch from
*.srtto*.txt– or if it’s all files in the folder,*.*. You need to make sure you’re at the command prompt; if you are in a .bat file, every%will need to be%%instead. The fancy stuff at the end just auto-generates the new name with .utf8 in the new filename, but otherwise uses the filename that it matched during the loop.(That is a command-line question, not a Notepad++ question.
cmd.exehas a for loop syntax as shown above. if you use powershell, you will need to find powershell loop syntax help elsewhere, as it’s not on-topic for a Notepad++ forum)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login