Regex error: (SyntaxError: invalid syntax) on Python Script Plugin
-
hello. In my previous post, I update this Python script for making multiple search and replace in all files. And works just fine. The regex is very simple in that case.
# -*- coding: utf-8 -*- from __future__ import print_function from Npp import * import os import sys #---------- class T22601(object): def __init__(self): Path="C:\\python-test" for root, dirs, files in os.walk(Path): nested_levels = root.split('/') if len(nested_levels) > 0: del dirs[:] for filename in files: if filename[-5:] == '.html': notepad.open(root + "\\" + filename) console.write(root + "\\" + filename + "\r\n") notepad.runMenuCommand("Encodage", "Convertir en UTF-8") regex_find_repl_dict_list = [ { 'find' : r'foo', 'replace' : r'bar' }, { 'find' : r'bar', 'replace' : r'gaga' }, ] editor.beginUndoAction() for d in regex_find_repl_dict_list: editor.rereplace(d['find'], d['replace']) editor.endUndoAction() notepad.save() notepad.close() #--------- if __name__ == '__main__': T22601()Now, I test a much complex regex:
line 24 { 'find' : r'<link (.*?)( rel='canonical'/>)', 'replace' : r'<link rel="canonical" \1 />' },line 24 { 'find' : r'<link (.*?)( rel='canonical'/>)', 'replace' : r'<link rel="canonical" \1 />' },and I got this error: SyntaxError: invalid syntax So it is something about regex. But what ?
see this print screen.
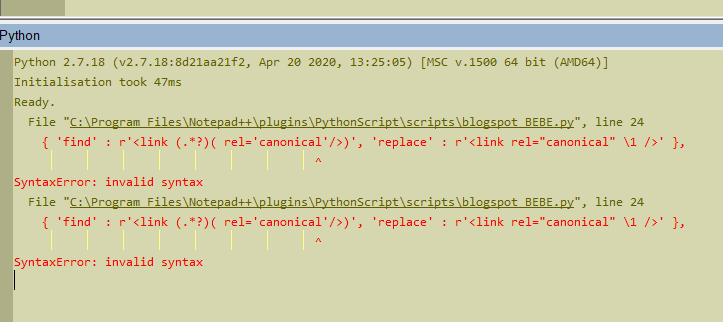
-
maybe I forgot to use flags?
something like:
flags=re.MULTILINE{ 'find' : r'<link (.*?)( rel='canonical'/>)', 'replace' : r'<link rel="canonical" \1 />' }, flags=re.MULTILINE -
Don’t use single quotes inside single quotes, or double quotes inside double quotes
Do use double quotes inside single quotes, or single quotes inside double quotes
-
This post is deleted! -
On complex regex, remember this:
First, you must put
\before any'in your regex. otherwise it will give conflict with the Python syntax that also have the operator'You had to remove the
rafterfind :part. So, should be'foo'instead ofr'foo'In your default example should be (without :
rin front of'foo'{ 'find' : 'foo', 'replace' : r'bar' },Your code, with the new and complex regex, should be like this.
I write a second regex to see much better:
# -*- coding: utf-8 -*- from __future__ import print_function from Npp import * import os import sys #------------------------------------------------------------------------------- class T22601(object): def __init__(self): Path="C:\\python-test" for root, dirs, files in os.walk(Path): nested_levels = root.split('/') if len(nested_levels) > 0: del dirs[:] for filename in files: if filename[-5:] == '.html': notepad.open(root + "\\" + filename) console.write(root + "\\" + filename + "\r\n") notepad.runMenuCommand("Encodage", "Convertir en UTF-8") regex_find_repl_dict_list = [ { 'find' : '<link (.*?)( rel=\'canonical\'/>)', 'replace' : r'<link rel="canonical" \1 />' }, { 'find' : '(<meta content=\')(.*)(\' property=\'og:description\'/>)', 'replace' : r'<meta name="description" content="\2" />' }, ] editor.beginUndoAction() for d in regex_find_repl_dict_list: editor.rereplace(d['find'], d['replace']) editor.endUndoAction() notepad.save() notepad.close() #------------------------------------------------------------------------------- if __name__ == '__main__': T22601()
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login