How to show ascii value of one selected character or a double byte character?
-
@c-bacca ,
If you are willing to use the PythonScript plugin, then install this script following these instructions to give yourself an on-demand reference as to what Unicode character is at the current cursor position.
But if you are pasting “smart quotes” into a UTF8 tab in Notepad++ and it is not showing up as smart quotes but as multiple characters, then I am confused, because that shouldn’t happen. Please share a screenshot with those characters and the full status bar shown.
Addendum: for example, here is an animated screenshot of my pasting in the “smart quotes” from above, showing the underlying character using the script I linked to, and showing that it only takes a single backspace to delete each smart quote:

-
@peterjones When I paste text into NPP that has smart quotes, (as an example of a 2 byte character) the smart quotes appear in NPP. The problem is I don’t want smart quotes in my UTF-8 file. So I put my cursor to the right of the smart quote, hit the BACKSPACE key once, and the character is deleted, EXCEPT there is now an invisible character (the first byte of the double byte character) that is still there and needs to be deleted by hitting backspace a second time.
If I forget to delete that hidden first byte this causes more problems when I try to use the DELETE or BACKSPACE key in that line.
The details here are: there appears to be at least 2 pairs of extended ASCII smartquote characters. One that has this problem, the other doesn’t. One set appears to be a single byte of an extended ASCII character above the value of 128. The other appears to be a double byte character, which has the problem I mentioned above.
Unfortunately I cannot tell which characters have the problem just by looking at them.
Does that make sense?
p.s. If I find the website which produces double-byte smart quotes in NPP I will try to update you here so you can do what I do.
-
You really haven’t given any more info than your first posting.
Have you done everything Peter suggested that you do? -
@c-bacca ,
I cannot find any of the “quotation marks” in Unicode that show that problem in Notepad++.
I am wondering if you have an encoding problem: maybe whatever you are copying from is putting a UTF16 sequence as two raw bytes into the clipboard, and the clipboard is pasting the two raw bytes into Notepad++… but if that were the case, I wouldn’t expect the visible character to be “correct” as a smart quote.
Using my
WhatUniChar.pyscript linked above will help identify what character(s) are being put into Notepad++. And the script here will put little black boxes with text for any (most) invisible characters – so that could also help identify what was going on. But either of those is going to take you installing PythonScript and actually running the script to tell us more details. -
@c-bacca, you could also try the GotoLineCol plugin. The plugin will display the ANSI byte value, the UTF-8 byte sequence and the Unicode code point. All this info is displayed in the side panel and as a calltip when you navigate the doc using the side panel controls. See the sample clip below.
When I find some rare emojis being used on Twitter, I copy & paste it into NPP and use GotoLineCol to ascertain the Unicode info.
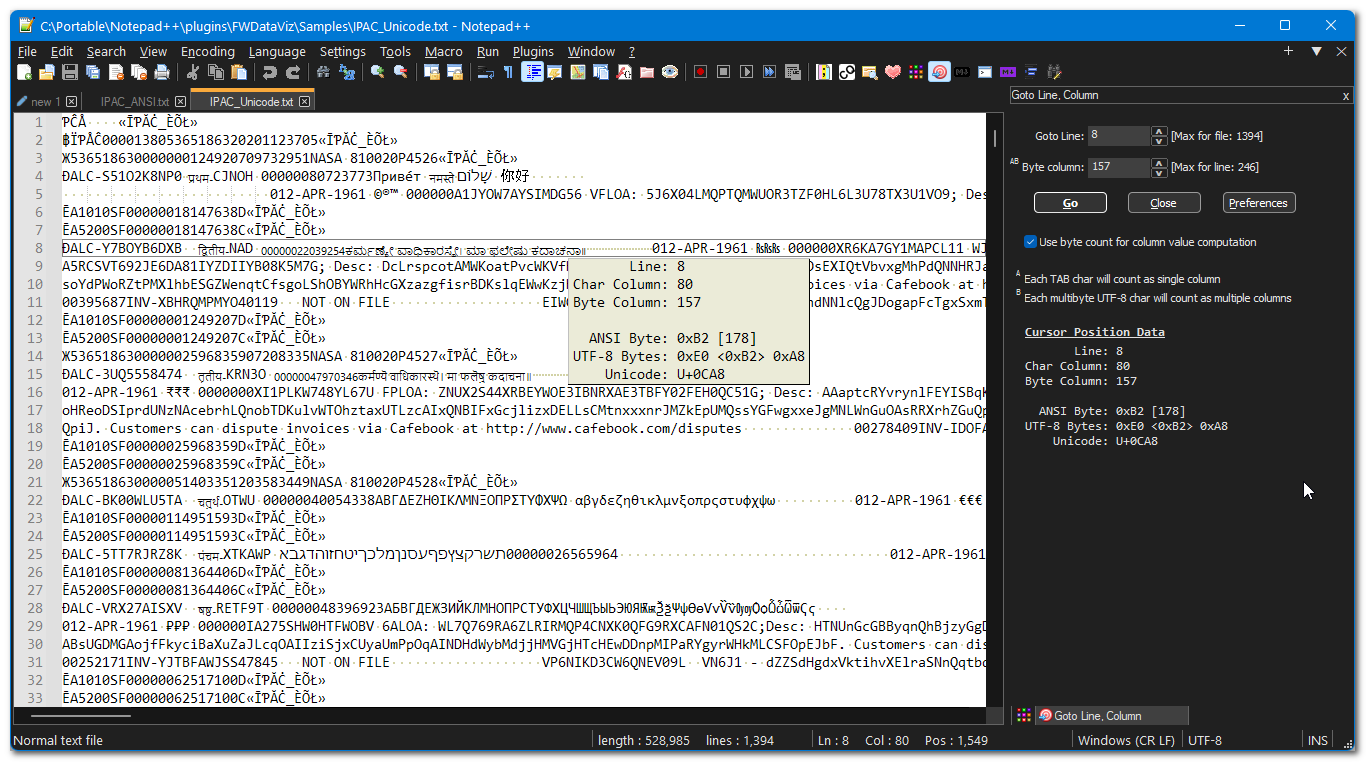
[DISCLAIMER: I am the author of this plugin.]
-
Hello @peterjones and All,
Peter, regarding your
WhatUniChar.pyscript, could you do a quick text ?-
Open any text file
-
With the
Edit > Character Panelmenu option, insert aNULcharacter, roughly, near the middle of current file -
Move the cursor right before this NULL char
-
Run your
WhatUniChar.pyscript
Did you ever notice this case ? Of course, it quite easy to recognize that the next char, in reverse video, is
\x{0000}!Bu, to be rigorous, I changed the end of line
20of your script into :if c != 0 else 'END-OF-FILE / NUL')Best Regards,
guy038
-
-
@guy038 said in How to show ascii value of one selected character or a double byte character?:
Did you ever notice this case ?
Nope.
I decided to figure out how to tell the difference between EOF and NUL, so it is now changed to:
is_eof = (editor.getCurrentPos()==editor.getLength()) info = "'{1}' = HEX:0x{0:04X} = DEC:{0} ".format(c, s.encode('utf-8') if c not in [13, 10, 0] else 'LINE-ENDING' if c != 0 else 'END-OF_FILE' if is_eof else 'NUL') -
As fine as the script is, I like @Shridhar-Kumar 's plugin for this, as more convenient. Now if it could only convert the text at the caret into hex/dec/bin equivalents (something I seem to have to do endlessly these days), I’d be truly excited.
-
@alan-kilborn, I will be happy to implement your suggested enhancement. I will keep you posted. It might take a while since I am totally occupied with a couple of other projects.
-
@shridhar-kumar said in How to show ascii value of one selected character or a double byte character?:
I will be happy to implement your suggested enhancement.
That’s great. I will create an issue on your github page describing what I’m looking for. If you choose to implement it, great! :-)
-
@alan-kilborn said in How to show ascii value of one selected character or a double byte character?:
I will create an issue on your github page
I did this HERE.
(Sorry for getting off-topic.)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login