UDL for DXL (C LIke) Number processing issues.
-
@swegmike As for PowerEditor, the following npp manual weblink halfway down the page shows it. NPP doesn’t install it, so how can one follow these steps for a directory that doesn’t exist nor the executable for the editor type. So no unit testing can be done.
-
@swegmike said in UDL for DXL (C LIke) Number processing issues.:
As for PowerEditor, the following npp manual weblink halfway down the page shows it. NPP doesn’t install it, so how can one follow these steps for a directory that doesn’t exist nor the executable for the editor type. So no unit testing can be done.
I forgot about that section. That section is entitled “Contribute your new or enhanced parser rule”. That means, it’s a section if you are going to try to convince the Notepad++ developers to include your function-list parser in the Notepad++ codebase. They will only accept function-list parsers for builtin lexers. You, @swegmike, are not creating a function-list parser for a builtin lexer. So that section doesn’t apply to you. (If it did apply to you, then you would have to fork the Notepad++ source code repository, and create your unit tests in that fork. And when you have that fork, then you would easily see the PowerEditor folder in your fork.) I will update that section of the manual to make it more clear in what situations that applies.
-
The new introductory paragraphs for that section will now say,
You’re welcome to contribute your new or enhanced parser by creating PR on Notepad++ GitHub page.
The following sections describe how to prepare your PR according the different situations, but these instructions assume you already know how to fork a GitHub repository, and how to run unit tests on the source code from your fork.Please note that it is only worthwhile to submit your parser to the Notepad++ codebase if the parser is for one of the builtin lexers. If you have created a parser that is for a UDL, you do not need to follow these instructions for Unit Tests, as they do not get distributed with Notepad++.
-
@PeterJones said in UDL for DXL (C LIke) Number processing issues.:
Please note that it is only worthwhile to submit your parser to the Notepad++ codebase if the parser is for one of the builtin lexers.
I think the sentence is misleading since a parser one is writing and being requested to be added is not “for one of the builtin lexers.” since the requester doesn’t know how many or which builtin lexer to be added to. My understanding is the parser will be added to the list of all the other language parsers/lexers already in npp. So instead of “for” , maybe it should say “added to the list” of builtin lexers.
What are your thoughts about npp being able to handle different language UDL xml files for the same language as a different version for development purpose, but distinguished by separate ids but under the same userdefinedlanguagename? Can npp separate them for the functionlist and autocompletion without hanging in infinite loops?
-
It is not misleading. Not all of the 80+ builtin lexers have an accompanying function list parser, so one could try to fill in the gaps. Secondly, as the documentation specifically mentions, one might also be providing an update or improvement to an existing function list parser.
different language UDL xml files for the same language as a different version for development purpose, but distinguished by separate ids but under the same userdefinedlanguagename?
If it were feasible to do, the developers would have given the Dark Mode and Original Markdown UDLs the same name. And they didn’t. That aside, the Language menu list shows that name, so how would the user know which of the N “Markdown” UDLs to select.
No. I firmly believe that UDL names need to remain unique.
-
@PeterJones said in UDL for DXL (C LIke) Number processing issues.:
It is not misleading
I still do not believe it was misleading. But after sleeping on it, I decided it could be clarified more:
Contribute your new or enhanced parser rule to the Notepad++ codebase
You are welcome to contribute your new or enhanced parser definition file to the Notepad++ codebase by creating PR on the Notepad++ GitHub page. This can be an update for a language that already has a function list definition, or can be a new definition file for one of the builtin lexer languages that does not yet have a function list definition. (This is not necessary if you are creating a function list definition for a UDL: since UDLs do not get distributed with Notepad++, neither do function list definitions for the UDLs. As such, you will not submit your UDL’s function list definition to the Notepad++ GitHub page through a PR, and you do not need to go through the “unit test” procedure described below for your UDL’s function list definition.)
-
@PeterJones I will think more on this.
I have been able to get multiple DXL UDL files that are configured differently for my dev purposes till I get one that works the way I want it to work. I can select each one to see what color changes happen for a given test file. The same on selecting the function list parser although all of these are the same based on a copy of the “C” lang parser but with different Ids and userDefinedLanngName differences.
There is a an inconsistency (although it works) between the user/my udl xml file and the overridMap.xml usage of “userDefinedLangName” such that the user UDL specifies this as “UserLang name” . NPP will determine how to match them, I wonder why they need to be different and couldn’t be the same.
I’m still wondering what displayName with the accompanying id does? I’ve changed this with missing or bogus data but it doesn’t affect anything.
Moreover, the autoCompletion files for my two user UDLs along with a shared lang of “DXL” doesn’t do anything even if they are deleted. Since if I go to a function definition and start typing “void” or “Int” before the function name a popup will appear although I don’t know where this is coming from since the scrowllable list contains things that my DXL language doesn’t have. So where is it getting this list and how can I modify this list for my DXL language. I thought it was controlled by autocompletion.However, I’ve been working another issue with NPP.
Since my DXL language is “C” like, I’ve been having problems such that when the functionlist parser is activated, npp will hang forever and the task manager shows “npp not responding” until I kill the task. I’ve narrowed the problem down to the “C” parser although I didn’t change anything. Moreover, when I select the “C” language to use and apply coloring instead of my udl, and then select functionlist it will also hang. It doesn’t do this with C#, C++, objective C or any other language ie. fortran, java, jscript, rust, etc.
My test file that I have is very simple for test purposes. It contains 1500 lines of plain text strings up to 20 characters max. These represent the copy and past of the UDL keyword 1-8 contents. Each keyword is a list of the following: builtin attributes, constants, properties, functions, statements, operators, then some arbitrary if logic, andnumber formats, The purpose isn’t to get a working program. It’'s to test that npp will be able to correctly apply the UDL coloring set for the keyword, delimiters, numerics, comments, operators etc. It does colorize as expected. Moreover, this test file doesn’t contain any function name declaration. So I expect when I turn on the “C” parser I borrowed for DXL or check the language as “C” so it uses its copy that the functionlist will be empty but only display the filename that this test sequence is in.
When I only have about 150 strings, after a few seconds it does display only the filename the test code is in. However, anything more than this causes the C parser to run forever i.e. with the 1500 strings that represent all the entries in keywords etc copied to the test file it is still trying to find a function after 15 plus minutes. So I have to kill npp in the task manager.In the case of a working DXL program that is 825 lines of code, it can find my one function and display it in the functionlist without problem.
Thus, I think there is a problem with the “C” lexer although other “C” language types such as C#, Cpp and objective-C don’t have this issue. So, what is the upper limit for the number of characters per line that the regular expression routine that npp uses have? In unix input streams have an upper limit of around 8k characters. However, in my case it is about 25 chars per line. I haven’t dug into the C parser to see why this issue is occurring. Maybe it has to do with the regular expression memory usage. My laptop has 8 gigs of memory and it never gets close to this when running into the above problem.
-
@swegmike After editing my post two times, on the third edit, it gives a popup that thinks I’m spamming.
-
@swegmike
I’ve been working on my DXL autocomplete xml file and have been able to get it to pass the XML pluggin validation. However, when I try to save it, I get a popup as shown below regardless if I run the “Convert to UTF-8” or “convert to ANSI” even though the first line in the xml file specifies UTF-8.Am I really missing a DTD although I have NPP 8.4.7 now?
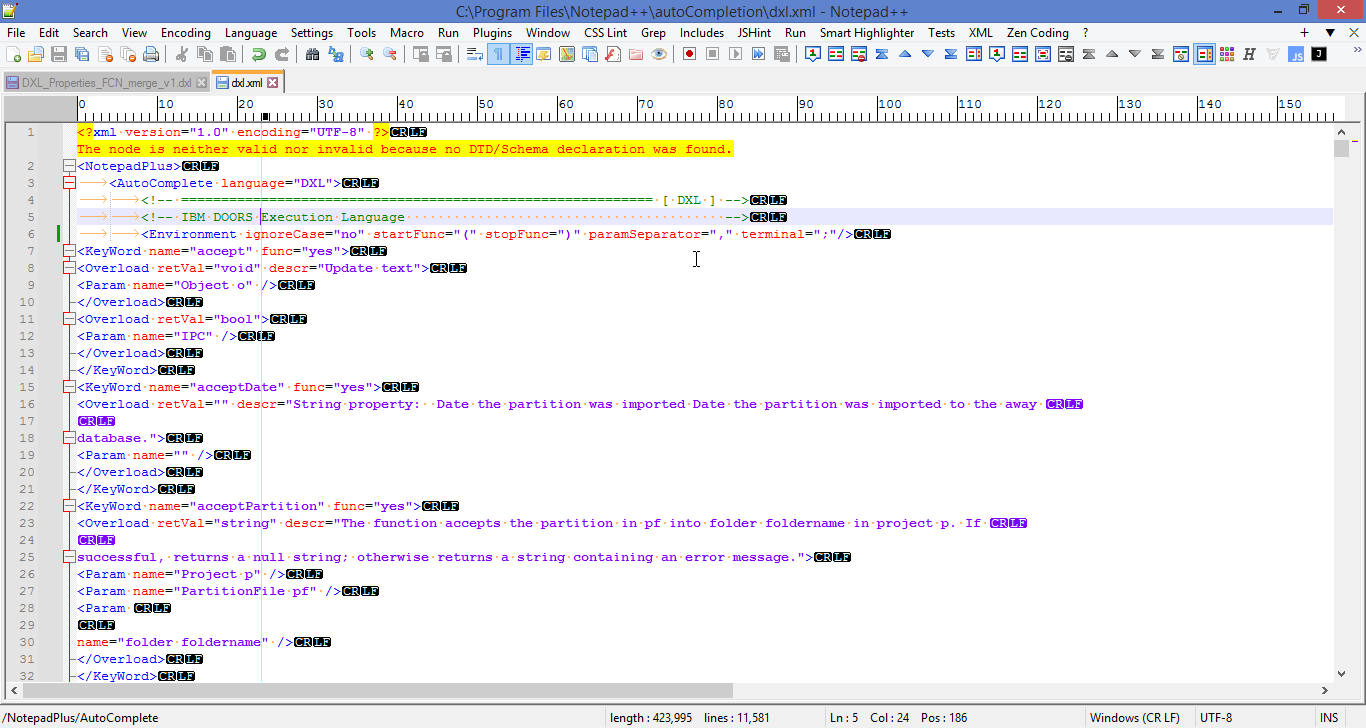
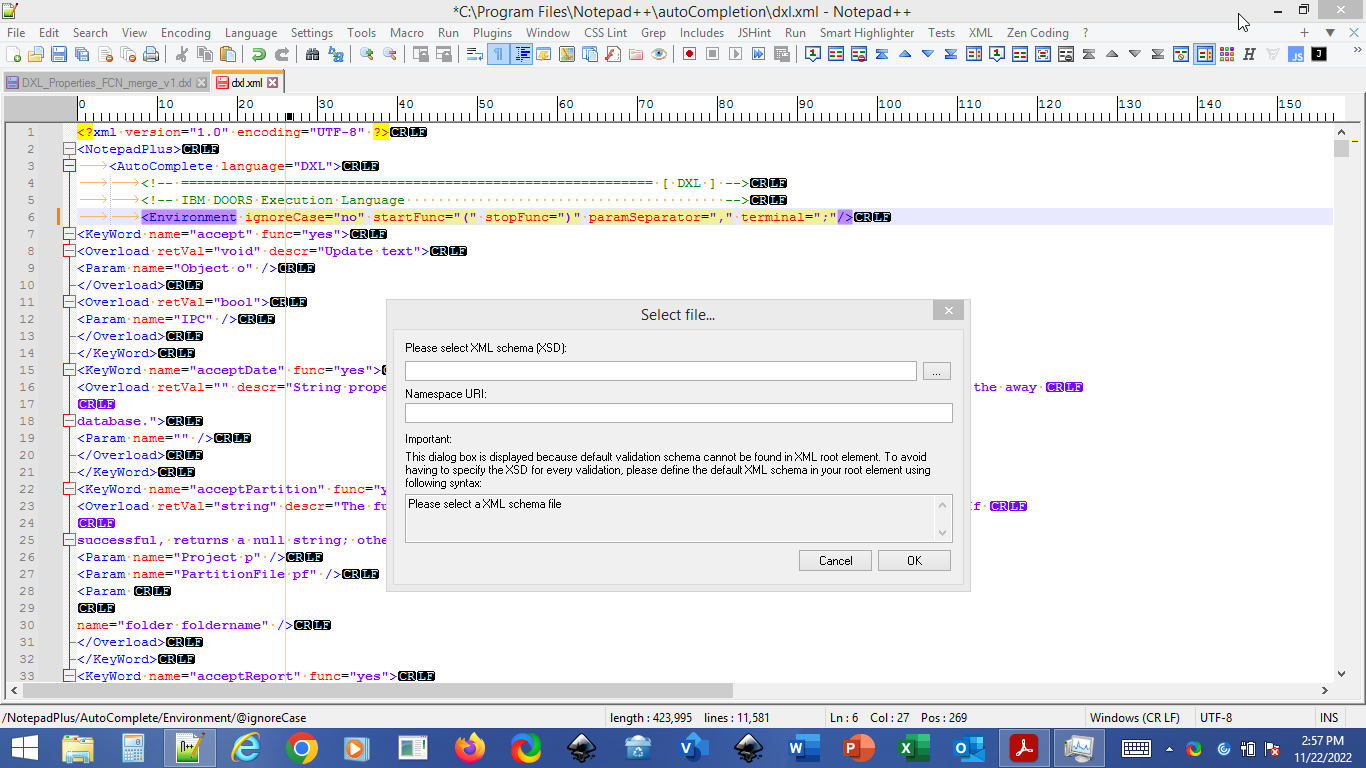
-
@swegmike ,
Good question. It looks legitimate, however, my Autocompletion file is encoding 1252 for the Windows standard, unless that’s changed by NPP. If I had to guess, perhaps the XML tools are what’s flagging it and doesn’t recognize it?It could also be a typo or other syntax violation later that doesn’t have a closing match or some such that is misplacing the error for you. Mind you, I’m not an expert, but if the tool is making the warning, it’s not NPP I don’t suspect. In my functionList.xml file, even though my file works, it gives an error ‘suspicion’ in my regex for the comment characters…so I don’t put a lot of stock in errors always showing where they are being where they really are. :) Sometimes, it’s elsewhere, but it’s easier for it to flag it somewhere else. ::shrug::.
-
The select file dialog is from the xml validation process.
I assume theenable auto validationfrom the xml menu has been checked. -
@Ekopalypse Thanks. that was the cause of the problem.
I think its strange that it would do this when trying to save the xml to a file since one may save a file based on partial editing or if it has bugs or is good for a later time. Moreover, one should use the xml pluggin to run the xml check manually to verify semantics/syntax at the time one wants the xml file being saved to be good- like I was doing. I’m wondering why the dtd/xsd error doesn’t occur when the manul xml verification in the pluggin is done vs. the auto validation checkbox functionality?
Although the xml pluggin finds alot of errors for a given xml start/end tag block i.e. <KeyWord… ,</KeyWord> it doesn’t always find the real cause of the error between them. i.e. Param misspelling etc. as Parm.
A big issue I had was after fixing all bugs in the xml, it was still flagging </AutoComplete> with an error inferring something between the start of it and this end tag had an issue. In the end when this happens, the cause was bad syntax for </KeyWord> such as no < or / before KeyWord or this being spelled as “Keyword”. A pain to find since I have 1500 KeyWord statements and it doesn’t colorize nor find the error other than stating </AutoComplete> as the error. To speed up the process of finding the issue, I had to do conquer and divide. That is take the first half and delete the rest and see if it passes, then continue this in halves to narrow down the region of my tags to locate which KeyWord was the cause…:(
-
@swegmike
Of the 1500 keywords I have this amounts to about 9100 lines of xml to scan thru for just one or more misspelled tags. In this case </KeyWord>I tried to see if online xmlvalidators are better at pointing to the exact line. However, they aren’t and just give me the </AutoComplete> error too.
Since there is no NPP autocomplete DTD/XSD defined, NPP can’t find the mispelled keyword mismatched tag structure directly from what I understand but only the syntax. I think a DTD is needed for NPP for this purpose.My xml data is in an Excel worksheet with other start/end autocomplete info. Thus worksheet macros concatenating the autocomplete header, with my xml data that is in the Overload/Param data tags and then with the autocomplete/NotepadPlus end tags to an xml merged worksheet that is then put in NPP after a little editing to remove the double quotes that MSoft adds upon copy/paste to MSofts notepad before placing in NPP. Then the double \r\n are removed for cleanup.
But I can narrow down the problem faster in Excel by filtering the xml column data for “doesn’t contain” </KeyWord> and it immediately pops out where the error(s) is at. Then I just scroll to keyword name that is in this cell that has the misspelled keyword tag. To reduce having to do this step after finding out within NPP; I’ll need to get in the habit to do this before copying everything via MSoft notepad to NPP to do the xml check there. -
I’m trying to format my autocomplete content so that when displayed as a hint, it shows various formatting such as bold, italic, underline, different font styles/sizes, hyperlinks etc.
However, entering <b>,</b> , <i>,</i>, <u>,</u> <h>,</h> into the xml strings for the return value, parameters or descriptions don’t work since it thinks its an xml error. Hyperlinks to external websites within the description or to the local harddrive for return values, function name/parameters and descriptions would also be useful since a user could pull up more detail or example programs that are extracted for the language reference manual since I can’t get everything into the function keywords string attributes in the autocomplete file.
I haven’t tried the CDATA string stuff to see if this works based on google for fonts etc. It appears that the “hint” first parameter may have a slight color change for only the first parameter as builtin to NPP, which I can’t control.Eventually, I’d like to add text colors too.
I have been experimenting with other xml markup besides the default ampersand, gt/lt , apos, quote names i.e. & . However, there are other names such as • that aren’t understood. However, if I enter the unicode value for other symbols such as this as • or newline the hint will show the symbol. Testing out other common symbols used for bulleted lists such as circles, diamonds, boxes both filled/unfilled seem to work. Even the copyright symbol as © or section § etc. However, picking a symbol for use based on the wikipedias unicode table listing is a mixed bag. It appears that NPP is more HTML 4.0 or earlier compliant but not HTML 5.0 although some symbols such as the checkmark ✓ will be displayed even though wikipedia says its HTML 5.0. -maybe a typo in wikipedia…
One of the things with the autocomplete xml file is that the description field may need to be a big paragraph. Using the newline unicode value helps to format it vs relying on the carriage return that was in the original text. I think in both cases this can be a big maintenance issue to keep the big paragraph text formatted so that it utilizes the display area efficiently and also based on a users screen resolution setting. There is no way to have NPP’s autocomplete automatically format a paragraph to fit the screen size/resolution to minimize the formatting like a regular text editor such as Word would do.
Eventually, one could take the completed autocomplete xml file and maybe have some tool use it to create a pdf or webpage user manual via xlst or something similar. More investigation is needed to see if this is possible…
Thus, is NPP only HTML 4.0 compliant and not v5.0? What about xHMTL or compatible with math symbols? How to get formatting such as bold/italic, fonts and hyperlinks to work in the autocomplete files?
-
is NPP only HTML 4.0 compliant and not v5.0? What about xHMTL or compatible with math symbols?
Config files like the autocompletion definitions are XML, not HTML, so of course they won’t be HTML5 compatible. XML recognizes numeric/hex entities and the 5 or so standard named entities – I believe the Wikipedia article on XML lists that small list (
on my phone, so I’m not going to look it up for you: edit: confirmed = there are 5 pre-defined entities in XML). So other than that handful, use the numeric/hex entities in the XML definition files.How to get formatting such as bold/italic, fonts and hyperlinks to work in the autocomplete files?
As far as the autocompletion hints, they aren’t designed for fancy rendering so adding bold or other such formatting to the hints that show up is not an intended feature for those hint boxes
There is no way to have NPP’s autocomplete automatically format a paragraph to fit the screen size/resolution to minimize the formatting like a regular text editor such as Word would do.
And please disabuse yourself of the comparison between MS Word and Notepad++. Word is a word processor, not a text editor, despite your assertion. They are two different types of applications.
-
@PeterJones said in UDL for DXL (C LIke) Number processing issues.:
XML recognizes numeric/hex entities
Actually, if you look at the discussion here, it appears that Notepad++'s parsing of the XML might have difficulty with the decimal numeric entities, so it seems more reliable to just use the hex entities (the ones that start with
&#xthen have 1 or more hexadecimal nibbles, followed by the;)