New ILexer interface from PythonScript
-
A while back, @Ekopalypse showed me how to use PythonScript to access the Scintilla Markdown lexer. Since then, Scintilla lexers have separated into Lexilla and we need to use the ILexer5 interface.
PythonScript doesn’t seem to have the
NPPM_CREATELEXERinterface, but it should be easy to code around that withctypes. This is what I have - and it WORKS!!:import os import ctypes from ctypes.wintypes import HWND, WPARAM, LPARAM, UINT, LPCWSTR SendMessage = ctypes.windll.user32.SendMessageW LRESULT = LPARAM SendMessage.argtypes = [HWND, UINT, WPARAM, LPCWSTR] SendMessage.restype = LRESULT from Npp import editor, notepad, NOTIFICATION from NppPyS.StdMod import StdMod, int2rgb NPPM_CREATELEXER = 2134 class MarkdownLexer(StdMod): def __init__(self): super().__init__() self.my_exts = ['.md', '.mkd', '.mkdn'] self._nppCallbacks = { self._on_buffer_activated: [NOTIFICATION.BUFFERACTIVATED, NOTIFICATION.LANGCHANGED] } self.MARKDOWN_SYTLES = { 0: 'E0E2E4', # SCE_MARKDOWN_DEFAULT 1: 'FFFFFF', # SCE_MARKDOWN_LINE_BEGIN 2: 'E3CEAB', # SCE_MARKDOWN_STRONG1 3: 'E3CEAB', # SCE_MARKDOWN_STRONG2 4: 'E3CEAB', # SCE_MARKDOWN_EM1 5: 'E3CEAB', # SCE_MARKDOWN_EM2 6: 'FF8000', # SCE_MARKDOWN_HEADER1 7: 'FF8000', # SCE_MARKDOWN_HEADER2 8: 'FF8000', # SCE_MARKDOWN_HEADER3 9: 'FF8000', # SCE_MARKDOWN_HEADER4 10: 'FF8000', # SCE_MARKDOWN_HEADER5 11: 'FF8000', # SCE_MARKDOWN_HEADER6 12: 'FFFFFF', # SCE_MARKDOWN_PRECHAR 13: 'FFCD22', # SCE_MARKDOWN_ULIST_ITEM 14: 'FFCD22', # SCE_MARKDOWN_OLIST_ITEM 15: 'FFFFFF', # SCE_MARKDOWN_BLOCKQUOTE 16: 'FFFFFF', # SCE_MARKDOWN_STRIKEOUT 17: 'FF8040', # SCE_MARKDOWN_HRULE 18: '0080FF', # SCE_MARKDOWN_LINK 19: '93C763', # SCE_MARKDOWN_CODE 20: '93C763', # SCE_MARKDOWN_CODE2 21: '93C763', # SCE_MARKDOWN_CODEBK } def _on_buffer_activated(self, args): ext = os.path.splitext(notepad.getCurrentFilename())[1] if ext in self.my_exts: self._style_markdown() def _style_markdown(self): lexerPtr = SendMessage(notepad.hwnd, NPPM_CREATELEXER, 0, "markdown") editor.setILexer(lexerPtr) for id, color in self.MARKDOWN_SYTLES.items(): editor.styleSetFore(id, int2rgb(color)) editor.colourise(0, -1) if __name__ == '__main__': markdownLexer = MarkdownLexer() markdownLexer.start() mdLex = markdownLexerNOTE: The above code relies on a way to source the Notepad++ handle and assign that to
notepad.hwndfor theSendMessage()call.The only issue I see is that I need to define the:
SendMessage.argtypes = [HWND, UINT, WPARAM, LPCWSTR]instead of using
LPARAMas I should for the last argument. Doing that causes an error:ctypes.ArgumentError: argument 4: TypeError: wrong typeIs there a way to “
cast()” the “markdown” string to anLPARAMtype in theSendMessage()call?If I can figure this out, I think I can make this more “generic” so any Lexilla lexers can be used regardless of direct Notepad++ support and I’d even like to have this parse proper XML files defining the types and colors for the non-supported lexers as is done for the supported ones in “stylers.model.xml”.
Cheers.
-
My HiddenLexers script, https://github.com/pryrt/nppStuff/blob/main/pythonScripts/HiddenLexers.py , developed in the Stata / SAS conversations, show how I enable the hidden lexers, based on what I had cobbled together from the forum. I think it shows the string casting.
(On phone, so not looking at details right now, just pasting link)
-
@PeterJones said in New ILexer interface from PythonScript:
My HiddenLexers script, https://github.com/pryrt/nppStuff/blob/main/pythonScripts/HiddenLexers.py , developed in the Stata / SAS conversations, show how I enable the hidden lexers, based on what I had cobbled together from the forum. I think it shows the string casting.
Exactly what I was looking for. Worked perfectly. I adapted to my PythonScript environment (adding my helper modules to import) and was able to get it to read “langs.hidden.xml” in the style of “langs.model.xml” for my hidden language keywords and also “themes\VinsWorldcom-Dark.hidden.xml” in the form of a “themes*.xml” file to get the colors. Didn’t go so far as to enable background colors (uses default) and font styles. Maybe that comes later.
Cheers.
-
Next question:
Tagging:
@Ekopalypse
@Bas-de-Reuver
due to their knowledge of the subject I’m now asking about below.The CSVLint plugin does 2 really cool “general” things with regards to lexing:
- Adds a Notepad++ “Language” menu item called “CSVLint” which is selected for “.csv” files.
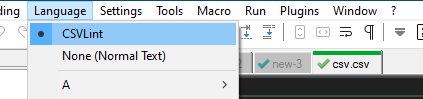
I think by adding the next available language ID . Inspecting
notepad.getCurrentLang()for a “CSVLint” file returns86and anotepad.getLanguageName(86)returns “CSVLint”:>>> notepad.getCurrentLang() Npp.LANGTYPE(86) >>> notepad.getLanguageName(86) 'CSVLint'- Adds it’s entries to the “Style Configurator…”:
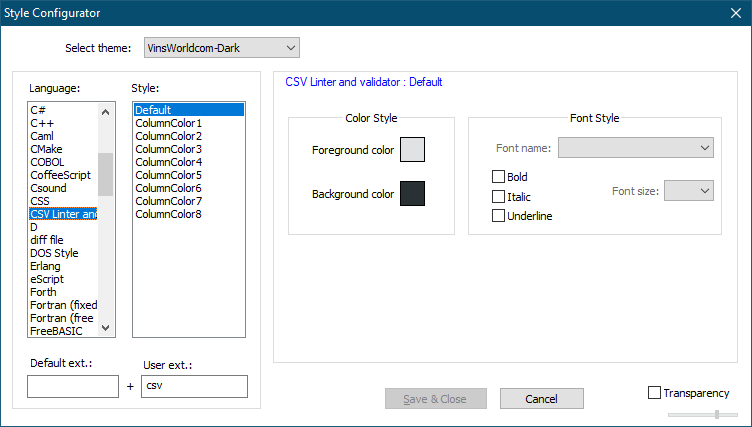
HOW???
I’m not very good at C# but it seems it may be in the ‘CSVLintNppPlugin/PluginInfrastructure/UnmanagedExports.cs’ file:
Is there anyway we can port these 2 cool features into our little Python hidden-lexer-enabler?
Cheers.
-
@Michael-Vincent said in New ILexer interface from PythonScript:
I’m not very good at C#
Unfortunately, neither am I.
I haven’t thought it through yet, but I don’t think it will work considering how the whole thing actually works.
When Npp loads a plugin, it checks to see if it is a lexer. If it is, Npp asks for the name via GetLexerName, etc.
Once it knows the name, it can load the correct xml file and assign it to its internal list of known lexers to populate in the style configurator for later use.Since to my knowledge there is no interface to interact with this internal data structure from a plugin, I don’t think this is possible, but as I said, I haven’t really checked.
If I find time over the holidays I’ll look into it, but I’d be really surprised if this is actually easily possible.Probably it would be easier to write a plugin that provides all scintilla lexers that are not activated as multi-lexers.
-
@Ekopalypse said in New ILexer interface from PythonScript:
but I don’t think it will work considering how the whole thing actually works.
That’s what I suspected after reading the Lexilla API and poking through CSVLint and Notepad++ for the better part of a few hours last night.
Of course, there are smarter people here than I so felt I should get some feedback.
If I find time over the holidays I’ll look into it, but I’d be really surprised if this is actually easily possible.
Please don’t unless this truly interests you. I don’t need it for anything. Enjoy the Holidays!
I’m actually pretty pleased with this solution. A PythonScript
setStatusBar()message is used to update the language and even the Scintilla callsSCI_GETLEXERLANGUAGEandSCI_PROPERTYNAMES, etc. work: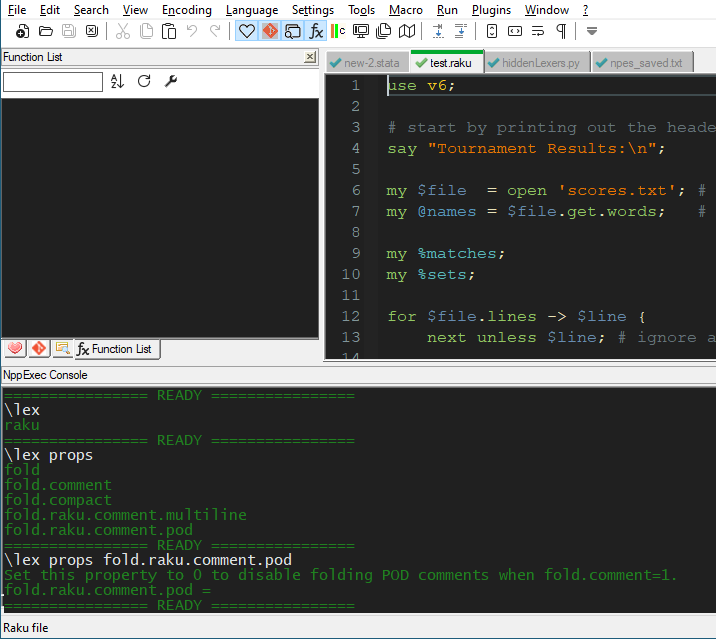
Probably it would be easier to write a plugin that provides all scintilla lexers that are not activated as multi-lexers.
Maybe so, but this PythonScript is just so easy / convenient to add lexers by just adding their keywords and styles to the appropriate files - in true Notepad++ fashion and then just calling
.add_lexer("language_name")Cheers.
-
When Npp loads a plugin, it checks to see if it is a lexer. If it is, Npp asks for the name via GetLexerName, etc.
To be more precise, it’s the address of
GetLexerCountthat must be non-NULLbefore the external lexer’s XML descriptor can be loaded. In descending order of importance, the mandatory exports are:LEXILLA_GETLEXERCOUNTLEXILLA_GETLEXERNAMELEXILLA_CREATELEXER
Lexilla’s 5 other API functions appear to be optional, since the plugin loader either ignores them or comments out the code that looks up their address.
// PowerEditor/src/MISC/PluginsManager/PluginsManager.cpp, 182 Lexilla::GetLexerCountFn GetLexerCount = (Lexilla::GetLexerCountFn)::GetProcAddress(pi->_hLib, LEXILLA_GETLEXERCOUNT); // it's a lexer plugin if (GetLexerCount) { Lexilla::GetLexerNameFn GetLexerName = (Lexilla::GetLexerNameFn)::GetProcAddress(pi->_hLib, LEXILLA_GETLEXERNAME); if (!GetLexerName) throw generic_string(TEXT("Loading GetLexerName function failed.")); //Lexilla::GetLexerFactoryFn GetLexerFactory = (Lexilla::GetLexerFactoryFn)::GetProcAddress(pi->_hLib, LEXILLA_GETLEXERFACTORY); //if (!GetLexerFactory) //throw generic_string(TEXT("Loading GetLexerFactory function failed.")); Lexilla::CreateLexerFn CreateLexer = (Lexilla::CreateLexerFn)::GetProcAddress(pi->_hLib, LEXILLA_CREATELEXER); if (!CreateLexer) throw generic_string(TEXT("Loading CreateLexer function failed.")); // ... }Probably it would be easier to write a plugin that provides all scintilla lexers that are not activated as multi-lexers.
How much easier depends on how many of Lexilla’s features your plugin wants to tap into. You will get lexing and folding for free, but you have to set all the lexical styles and properties programatically, the way my fork of NPPFSIPlugin does — by reading INI files! There’s also no way I know of to set a native lexer’s comment tokens. That may be a candidate for a new plugin API . . .
A plugin that exports
GetLexer<Count|Name>andCreateLexercan use XML-defined styles, but then you have to implementLex,Fold, and about a dozen other functions, the way CSVLint does. -
Like someone already pointed out, the C#/dll plugins work a bit differently compared to the PythonScript plug-ins. I don’t know if it’s possible or how to register the Language name and syntax highlighting colors for PythonScript plugins.
I’ll just tag @Shridhar-Kumar in this thread, because I think he knows more about PythonScript, seeing as he posted this issue.
fyi for more info about creating a plugin using VS and C# there is also a github repository with a template project, see Lexer example C# - Notepad++ plugin
-
I don’t know if it’s possible or how to register the Language name and syntax highlighting colors for PythonScript plugins.
The shortest answer is No, you cannot. The plugin has to present valid addresses to actual C-like functions when
::GetProcAddressis called, and do so when N++ first starts up, i.e., before the Python host is even ready to execute scripts.External lexers (i.e., the “registered” kind) are by nature compiled libraries — in C#, C++ or any language with a well-defined C-like FFI, like Rust, V, Object Pascal, etc.
-
@rdipardo said in New ILexer interface from PythonScript:
before the Python host is even ready to execute scripts.
Both are correct. However, PythonScript offers enough in the form of API and callbacks that we can access the compiled lexers and by reading in a config file (langs.hidden.xml) and stylers file (stylers.hidden.xml) based on their “.model.xml” versions, we can get pretty decent lexing for “non-standard” languages, including (ones I’ve tried):
- Stata
- Julia
- X12
- Edifact
- BibTeX
- F#
- Raku
Thanks to @PeterJones for his code pointer above in this thread which I highly modified to get to this solution.
PS: If you include the
GlobalStylestag in the “hidden” stylers file, you can actually select it in the Style Configurator and make changes. The changes are not effective immediately, you need to save and then use PythonScript to.reload_lexer(), but the slight inconvenience of 2-step process for the few times I’ll do this … no big deal.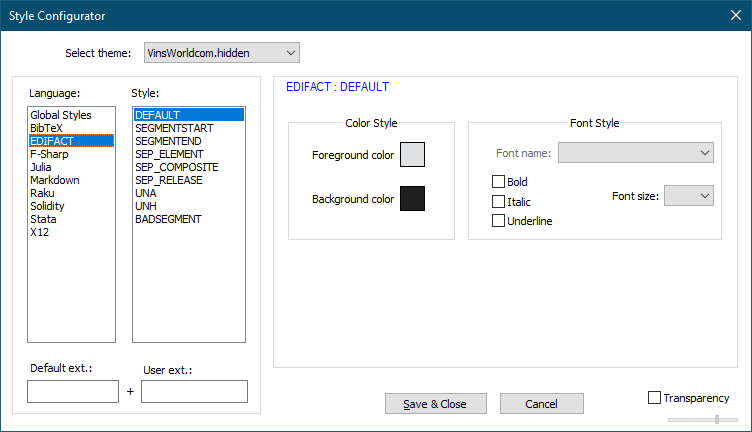
Thank you all!
Cheers.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login