functionList not ignoring comments
-
@dinkumoil ,
Here’s the code that is being used for the UDL and the functionList parser. The following sample code is modified from the above with the addition of a function outside of the class, to show the mixed parser functionality working.Sample:
class ccs_Object(vInstanceId) of Timer() custom /* class newClass(vInstanceId) of ccs_Object(vInstanceId) ... class construct ... ... class methods ... endclass */ /* ============================================================================= Class constructor ============================================================================= */ function IamLoaded() return endclass function outsideClassTest junk = nothing returntestd.xml - UDL
<NotepadPlus> <UserLang name="testd" ext="wfm cfm cdm rep crp prg cc mnu sfm dmd lab" udlVersion="2.1"> <Settings> <Global caseIgnored="yes" allowFoldOfComments="no" foldCompact="no" forcePureLC="2" decimalSeparator="0" /> <Prefix Keywords1="no" Keywords2="no" Keywords3="no" Keywords4="no" Keywords5="no" Keywords6="no" Keywords7="no" Keywords8="no" /> </Settings> <KeywordLists> <Keywords name="Comments">00* 01 02 03/* 04*/</Keywords> <Keywords name="Numbers, prefix1"></Keywords> <Keywords name="Numbers, prefix2">0x</Keywords> <Keywords name="Numbers, extras1">A B C D E F a b c d e f</Keywords> <Keywords name="Numbers, extras2"></Keywords> <Keywords name="Numbers, suffix1">B b O o</Keywords> <Keywords name="Numbers, suffix2"></Keywords> <Keywords name="Numbers, range"></Keywords> <Keywords name="Operators1">= ; | := += -= *= /= %= == <> # > < >= <= ** ++ -- -> & + - * $ % ^ / ,</Keywords> <Keywords name="Operators2"></Keywords> <Keywords name="Folders in code1, open"></Keywords> <Keywords name="Folders in code1, middle"></Keywords> <Keywords name="Folders in code1, close"></Keywords> <Keywords name="Folders in code2, open">"do case" "do while" #if class do do do if if for for function try printjob with</Keywords> <Keywords name="Folders in code2, middle">#elseif else elseif</Keywords> <Keywords name="Folders in code2, close">endcase until #endif endclass enddo while with endif next endfor return endtry endprintjob endwith</Keywords> <Keywords name="Folders in comment, open"></Keywords> <Keywords name="Folders in comment, middle"></Keywords> <Keywords name="Folders in comment, close"></Keywords> <Keywords name="Keywords1">'close procedure' 'set procedure to' additive form local parameter parameters persistent procedure</Keywords> <Keywords name="Keywords2">case catch exit finally loop otherwise throw</Keywords> <Keywords name="Keywords3">AND NEW NOT OR of</Keywords> <Keywords name="Keywords4">'.and.' '.f.' '.not.' '.or.' '.t.'</Keywords> <Keywords name="Keywords5"></Keywords> <Keywords name="Keywords6">false true</Keywords> <Keywords name="Keywords7"></Keywords> <Keywords name="Keywords8"></Keywords> <Keywords name="Delimiters">00[ 01 02] 03( 04 05) 06{ 07 08} 09// 09&& 10 11((EOL)) 11((EOL)) 12" 13 14" 15 16 17 18 19 20 21 22 23</Keywords> </KeywordLists> <Styles> <WordsStyle name="DEFAULT" fgColor="FFFF00" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="0" fontSize="11" nesting="0" /> <WordsStyle name="COMMENTS" fgColor="00FF00" bgColor="FFFFFF" colorStyle="1" fontName="Source Code Pro" fontStyle="3" fontSize="11" nesting="0" /> <WordsStyle name="LINE COMMENTS" fgColor="00FF00" bgColor="808080" colorStyle="1" fontName="Source Code Pro" fontStyle="3" fontSize="11" nesting="0" /> <WordsStyle name="NUMBERS" fgColor="00FFFF" bgColor="FFFFFF" colorStyle="1" fontName="Source Code Pro" fontStyle="0" fontSize="11" nesting="0" /> <WordsStyle name="KEYWORDS1" fgColor="FFFFFF" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="1" fontSize="11" nesting="0" /> <WordsStyle name="KEYWORDS2" fgColor="FFFFFF" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="1" fontSize="11" nesting="0" /> <WordsStyle name="KEYWORDS3" fgColor="FFFFFF" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="1" fontSize="11" nesting="0" /> <WordsStyle name="KEYWORDS4" fgColor="FFFFFF" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="1" fontSize="11" nesting="0" /> <WordsStyle name="KEYWORDS5" fgColor="FFFFFF" bgColor="000000" fontStyle="0" nesting="0" /> <WordsStyle name="KEYWORDS6" fgColor="00FFFF" bgColor="FFFFFF" colorStyle="1" fontName="Source Code Pro" fontStyle="0" fontSize="11" nesting="0" /> <WordsStyle name="KEYWORDS7" fgColor="000000" bgColor="FFFFFF" fontStyle="0" nesting="0" /> <WordsStyle name="KEYWORDS8" fgColor="000000" bgColor="FFFFFF" fontStyle="0" nesting="0" /> <WordsStyle name="OPERATORS" fgColor="FFFFFF" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="0" fontSize="11" nesting="0" /> <WordsStyle name="FOLDER IN CODE1" fgColor="000000" bgColor="FFFFFF" fontName="Source Code Pro" fontStyle="1" fontSize="11" nesting="0" /> <WordsStyle name="FOLDER IN CODE2" fgColor="FFFFFF" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="1" fontSize="11" nesting="0" /> <WordsStyle name="FOLDER IN COMMENT" fgColor="FFFFFF" bgColor="000000" fontName="Source Code Pro" fontStyle="0" fontSize="11" nesting="0" /> <WordsStyle name="DELIMITERS1" fgColor="00FFFF" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="0" fontSize="11" nesting="33554432" /> <WordsStyle name="DELIMITERS2" fgColor="FFFFFF" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="0" fontSize="11" nesting="83931154" /> <WordsStyle name="DELIMITERS3" fgColor="FFFFFF" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="0" fontSize="11" nesting="83886087" /> <WordsStyle name="DELIMITERS4" fgColor="00FF00" bgColor="FFFFFF" colorStyle="1" fontName="Source Code Pro" fontStyle="3" fontSize="11" nesting="0" /> <WordsStyle name="DELIMITERS5" fgColor="00FFFF" bgColor="000000" colorStyle="1" fontName="Source Code Pro" fontStyle="0" fontSize="11" nesting="0" /> <WordsStyle name="DELIMITERS6" fgColor="000000" bgColor="FFFFFF" fontStyle="0" nesting="0" /> <WordsStyle name="DELIMITERS7" fgColor="000000" bgColor="FFFFFF" fontStyle="0" nesting="0" /> <WordsStyle name="DELIMITERS8" fgColor="000000" bgColor="FFFFFF" fontStyle="0" nesting="0" /> </Styles> </UserLang> </NotepadPlus>testd.xml - functionList
<?xml version="1.0" encoding="UTF-8" ?> <!-- ==========================================================================\ | | To learn how to make your own language parser, please check the following | link: | https://npp-user-manual.org/docs/function-list/ | \=========================================================================== --> <!--Much of this regex is courtesy of Peter Jones of the Notepad++ Community, with some changes made for customization by Lee Grant--> <NotepadPlus> <functionList> <!-- ========================================================= [ testd ] --> <parser displayName="testd" id ="testd" commentExpr="(?x) (?s:/\*.*?\*/) |(?m-s://.*?$) |(?m-s:&&.*?$) " > <classRange mainExpr="(?xi) # Free-spacing mode and inline comments + search sensitive to case ^\h* # Optional leading whitespace chars class # 'class' keyword \h? # Optional whitepace char \w+ # Class name \h? # Following the class name there is the option of parameters, and if so the first entry inside the parens is required, whether there is other # parameters or not, once the parens go up, the first is required. ie: class FrameCtrl(frameObj) (?: # Beginning of the optional parameter(s) part ( Group 1 ) \( # Opening parenthesis (\h*\w+\h*)? # First and required parameter ( ,? \h* \w+\h*)* # Following optional/additional parameters \) # Closing parenthesis )? # End of the optional parameter(s) part # For the rest of the class declaration, after the class name, all other options are part of one big optional set, that follows 'of' \h? # and can be populated by one of several options. (?: # Beginning of the main optional part, in a non-capturing group # The first and most prevalent is the Superclass name that the class is being subclassed from, and it's options of parameters and again, # if it has parameters, at least the first one is required ie.: class ToolButtonFx(oParent) of Toolbutton(oParent). of # Optional 'of' keyword, surrounded by 1 horizontal whitespace char \h? \w+ # Superclass name \h? (?: # Beginning of the optional parameter(s) part ( Group 2 ) \( # Opening parenthesis (\h?\w+?\h?)? # First and required parameter ( ,? \h* \w+\h*)* # Following optional/additional parameters \) # Closing parenthesis )? # End of the optional parameter(s) part # The next possible option is that it is a custom object and needs to be in this line so if the object or form is opened up in the dBASE IDE, # the designers in it won't mess up the object by streaming out missing parts or overriding properties or objects and functions. #\h* #( custom )? # Optional 'custom' keyword # The next possible option is that the class is being subclassed from another object that is contained elsewhere and the compiler needs to know # this reference. There are two options for pointing to the file. The first is an Alias path in the IDE that can be accessed by the compiler # in the environment, or second, it is in the current directory and only the name is needed...or it has a path that can be listed here, # but this is bad practice, and an Alias is recommended if the file is in a place other than the current directory. If it is, the name can be # used in quotes as a string that gets passed to the compiler. Both follow the word 'From'. The Alias directory is a name that is enclosed # in two colons, one immediately before the Alias name and one immediately after, no spaces. \h* (?: # Beginning of the optional part, in a non-capturing group from # Optional 'from' keyword, surrounded by 1 horizontal whitespace char \h* (?: # Beginning of a non-capturing group : \w+ : \w+ \. \w+ # First pointing file case | # OR \x22 \w+ \. \w+ \x22 # Second pointing file case ) # End of a non-capturing group )? # End of the optional part \h* (?: custom )? # Optional 'custom' keyword )? # End of the main optional part $ # End of current line and end of the class declaration (?si:.*?^\h*endclass) # must match all the way to 'endclass' " > <className> <nameExpr expr="(?xi) # Free-spacing mode and inline comments and search sensible to case \h* # Optional leading whitespace chars class # 'class' keyword \h? # Optional whitepace char \K\w+ # Pure class name " /> </className> <function mainExpr="(?xi-s) ^ \h* (?: function \h+ \w+ | procedure \h+ \w+ | with \h+ \(.*?\) ) \h* " > <functionName> <funcNameExpr expr="(?xi-s) # multiline/comments ^ # trying to keep following keywords from being included in comments \h* # allow leading spaces (?: function # must have word 'function' as first word \h+ # must have at least one horizontal space after function # \K don't keep 'function' in the name of the function in the panel \w+ # the name of the function is the first whole word after 'function' | procedure # must have word 'procedure' as first word \h+ # must have at least one horizontal space after procedure # \K don't keep 'procedure' in the name of the function in the panel (?!to\b)\w+ # the name of the function is the first whole word after 'procedure' - 'to' # so as to exclude any 'set procedure to' statements, needs work though. | with \h+ \K \( \Kthis\.\K(.+)(?=\)) # all but 'this' and the closing parens. | with \h+ \K \( \K(.*?)(?=\)) ) " /> </functionName> </function> </classRange> <function mainExpr="(?xi-s) ^ \h* (?: function \h+ \w+ | procedure \h+ \w+ ) \h* " > <functionName> <nameExpr expr="(?xi-s) # multiline/comments \h* # allow leading spaces (?: function # must have word 'function' as first word \h+ # must have at least one horizontal space after function #\K # don't keep 'function' in the name of the function in the panel \w+ # the name of the function is the first whole word after 'function' | procedure \h+ #\K (?!to\b)\w+ ) " /> </functionName> </function> </parser> </functionList> </NotepadPlus>As noted above, I have re-OR’d the commentExpr regex in the above functionList parser testd.xml file.
Remove the OR’s in it to re-produce the class
constructor, instead of classccs_Object, showing that the endclass in comments is being read by the parser and used to close off the classccs_Objectwith no function inside it.Alternatively, use single line comments
//instead of the block comments/* */to show the proper classccs_Objectnamed. -
@Lycan-Thrope
And here’s the overrideMap.xml that the other message wouldn’t let me put in since the previous post is so long.<?xml version="1.0" encoding="UTF-8" ?> <!-- ==========================================================================\ | | To learn how to make your own language parser, please check the following | link: | https://npp-user-manual.org/docs/function-list/ | \=========================================================================== --> <NotepadPlus> <functionList> <associationMap> <!-- This file is optional (can be removed). Each functionlist parse rule links to a language ID ("langID"). The "id" is the parse rule's default file name, but users can override it. Here are the default value they are using: <association id= "php.xml" langID= "1" /> <association id= "c.xml" langID= "2" /> <association id= "cpp.xml" langID= "3" /> (C++) <association id= "cs.xml" langID= "4" /> (C#) <association id= "objc.xml" langID= "5" /> (Obective-C) <association id= "java.xml" langID= "6" /> <association id= "rc.xml" langID= "7" /> (Windows Resource file) <association id= "html.xml" langID= "8" /> <association id= "xml.xml" langID= "9" /> <association id= "makefile.xml" langID= "10"/> <association id= "pascal.xml" langID= "11"/> <association id= "batch.xml" langID= "12"/> <association id= "ini.xml" langID= "13"/> <association id= "asp.xml" langID= "16"/> <association id= "sql.xml" langID= "17"/> <association id= "vb.xml" langID= "18"/> <association id= "css.xml" langID= "20"/> <association id= "perl.xml" langID= "21"/> <association id= "python.xml" langID= "22"/> <association id= "lua.xml" langID= "23"/> <association id= "tex.xml" langID= "24"/> (TeX) <association id= "fortran.xml" langID= "25"/> <association id= "bash.xml" langID= "26"/> <association id= "actionscript.xml" langID= "27"/> <association id= "nsis.xml" langID= "28"/> <association id= "tcl.xml" langID= "29"/> <association id= "lisp.xml" langID= "30"/> <association id= "scheme.xml" langID= "31"/> <association id= "asm.xml" langID= "32"/> (Assembly) <association id= "diff.xml" langID= "33"/> <association id= "props.xml" langID= "34"/> <association id= "postscript.xml" langID= "35"/> <association id= "ruby.xml" langID= "36"/> <association id= "smalltalk.xml" langID= "37"/> <association id= "vhdl.xml" langID= "38"/> <association id= "kix.xml" langID= "39"/> (KiXtart) <association id= "autoit.xml" langID= "40"/> <association id= "caml.xml" langID= "41"/> <association id= "ada.xml" langID= "42"/> <association id= "verilog.xml" langID= "43"/> <association id= "matlab.xml" langID= "44"/> <association id= "haskell.xml" langID= "45"/> <association id= "inno.xml" langID= "46"/> (Inno Setup) <association id= "cmake.xml" langID= "48"/> <association id= "yaml.xml" langID= "49"/> <association id= "cobol.xml" langID= "50"/> <association id= "gui4cli.xml" langID= "51"/> <association id= "d.xml" langID= "52"/> <association id= "powershell.xml" langID= "53"/> <association id= "r.xml" langID= "54"/> <association id= "jsp.xml" langID= "55"/> <association id= "coffeescript.xml" langID= "56"/> <association id= "json.xml" langID= "57"/> <association id= "javascript.js.xml" langID= "58"/> <association id= "fortran77.xml" langID= "59"/> <association id= "baanc.xml" langID= "60"/> (BaanC) <association id= "srec.xml" langID= "61"/> (Motorola S-Record binary data) <association id= "ihex.xml" langID= "62"/> (Intel HEX binary data) <association id= "tehex.xml" langID= "63"/> (Tektronix extended HEX binary data) <association id= "swift.xml" langID= "64"/> <association id= "asn1.xml" langID= "65"/> (Abstract Syntax Notation One) <association id= "avs.xml" langID= "66"/> (AviSynth) <association id= "blitzbasic.xml" langID= "67"/> (BlitzBasic) <association id= "purebasic.xml" langID= "68"/> <association id= "freebasic.xml" langID= "69"/> <association id= "csound.xml" langID= "70"/> <association id= "erlang.xml" langID= "71"/> <association id= "escript.xml" langID= "72"/> <association id= "forth.xml" langID= "73"/> <association id= "latex.xml" langID= "74"/> <association id= "mmixal.xml" langID= "75"/> <association id= "nimrod.xml" langID= "76"/> <association id= "nncrontab.xml" langID= "77"/> (extended crontab) <association id= "oscript.xml" langID= "78"/> <association id= "rebol.xml" langID= "79"/> <association id= "registry.xml" langID= "80"/> <association id= "rust.xml" langID= "81"/> <association id= "spice.xml" langID= "82"/> <association id= "txt2tags.xml" langID= "83"/> <association id= "visualprolog.xml" langID= "84"/> <association id= "typescript.xml" langID= "85"/> If you create your own parse rule of supported languages (above) for your specific need, you can copy it without modifying the original one, and make it point to your rule. For example, you have created your php parse rule, named "myphp2.xml". You add the rule file into the functionlist directory and add the following line in this file: <association id= "myphp2.xml" langID= "1" /> and that's it. --> <!-- As there is currently only one langID for COBOL: uncomment the following line to change to cobol-free.xml (cobol section free) if this is your favourite format --> <!-- <association id= "cobol-free.xml" langID= "50"/> --> <!-- For User Defined Languages (UDL's) use: <association id="my_parser.xml" userDefinedLangName="My UDL Name" /> If "My UDL Name" doesn't exist yet, you can create it via UDL dialog. --> <!-- ==================== User Defined Languages ============================ --> <association id= "testd.xml" userDefinedLangName="testd"/> <association id= "krl.xml" userDefinedLangName="KRL"/> <association id= "sinumerik.xml" userDefinedLangName="Sinumerik"/> <association id= "universe_basic.xml" userDefinedLangName="UniVerse BASIC"/> <!-- ======================================================================== --> </associationMap> </functionList> </NotepadPlus> -
@Lycan-Thrope ,
The result of these files, again, can be viewed with this version of the test file above. One with block comments, one with single line comments and the one with single line comments with the class expanded to view the internal function/method.Block Comments:
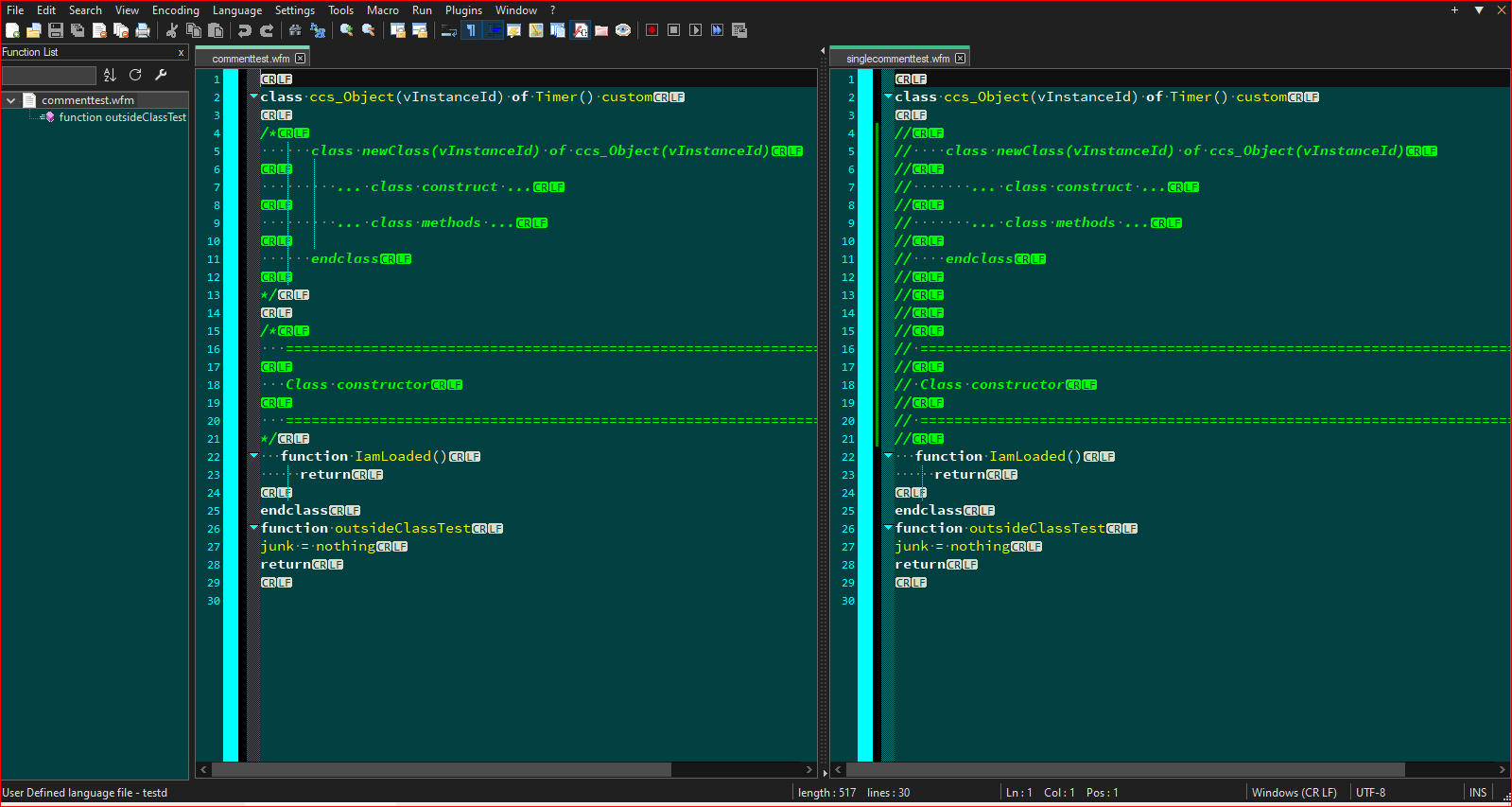
Single Line Comments:
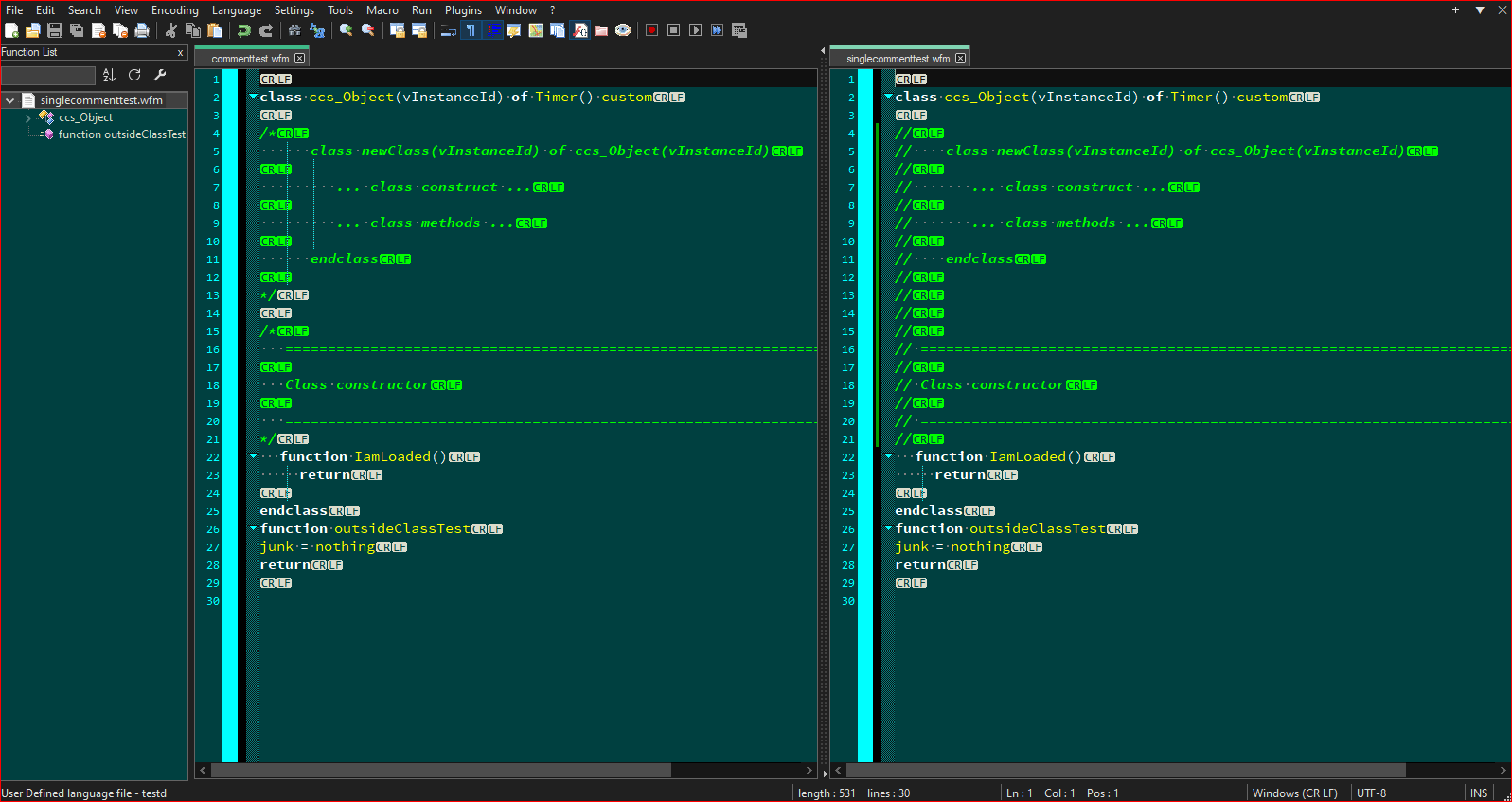
And this one shows the class opened up to see the internal function/method:
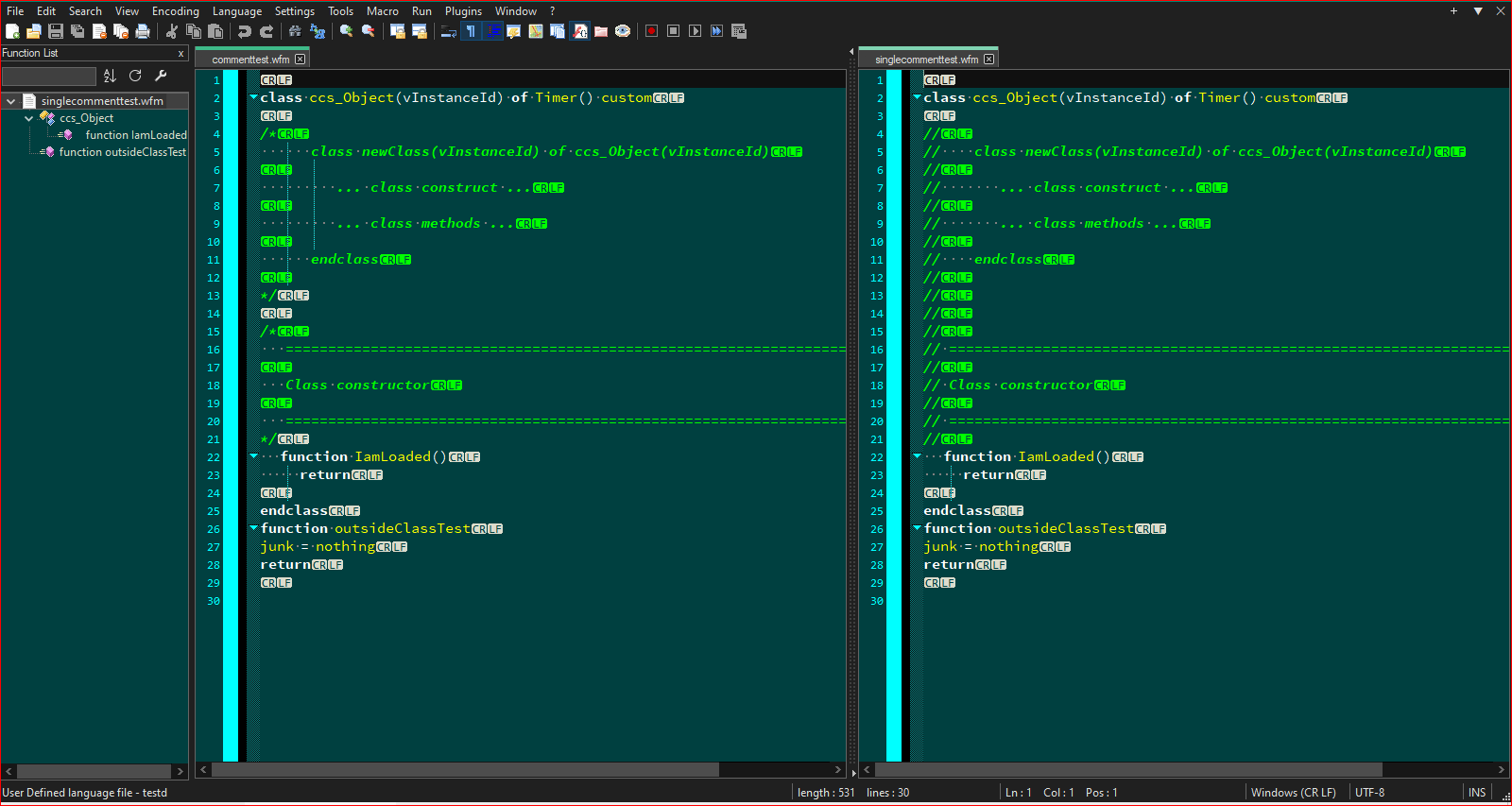
Waiting to hear your feedback.
-
@mpheath ,
Incidentally, you’ll see I did put the original code back in with regards your points of?in the block comment search. Like I said, I did have them that way originally, but was trying different things, and one of them is the one that exposed that comments weren’t ignoring theendclassin comments. It may be the keyword pair that closes the class definition, but as it is behind comments, it should not be paid any attention. That’s not happening for some reason. In addition, if I take that?out, we get the next comment that hasClass constructorin the comment section chosen to be a functionList entry. -
Thanks for the files. This is the output of the zones…
commentZone: 51, 209 commentZone: 213, 409 classZone: 0, 203 classZone: 301, 460 funcZone: 462, 487This is the visual (Disregard green at end as it is missing a closing span tag). The Class match is from the start of the document (pos
0) and ends atendclass(pos203) inside the comment zone. Code within comments are invalid as a match. This class match is not within a comment zone so is a valid match as far as the parser is concerned. Making it invalid because it is partly into a comment zone would IMO lose the Class from being displayed in the functionlist panel and would be a worse result.Looking at the
pascal.xmlfunction list file, I do not see patterns trying to locate theendkeyword of a Class, Function or Procedure. So intestd.xml, is it necessary to match toendclassto acknowledge a Class definition?Class definition:
class ccs_Object(vInstanceId) of Timer() customI do not know the fine details of recognizing class functions from ordinary functions with the functionlist patterns so @dinkumoil may be able to help with that.
Greediness in the patterns seems to be a problem with the functionlist parsing so suggest to avoid using greedy patterns. The larger the match, the more vunerable it is to run into an issue like this one. Try to aim for the smallest match to achieve a successful result. I consider that @dinkumoil has achieved that with
pascal.xml. -
@mpheath ,
What am I looking at there? Is that the character/caret positions?To answer your question, yes, we needed to have the endclass found to close the class. That regex was giving me trouble, as you point out, trying to find only the least amount. @PeterJones , @guy038 , and a few other users here helped formulate the needed regex in that functionList parser file. We needed that to make the regex run the entire length down to the endclass so we could find and close the Class definition.
The dBASE Plus OOP isn’t like C++, where typically, one file = one class. We can have multiple classes defined per file, and thanks to @PeterJones , we also were able to have our objects display like functions inside a Class definition, because they are basically UI objects inside a Class…they technically are other class objects being defined inside a class. So yes, it needs to find the endclass to close one class, and find another.
We can’t use the OpenSymbole/CloseSymbole delimiters like C++ can. We tried putting the terms class/endclass inside those, but I suspect they are only meant for single characters as we never were able to get them to be used for identifying the open/close it needed to frame the Class definitions.
But, again…the endclass should be ignored, inside comments. Period. :)
Edit: Yes, they are character/caret positions, so I see and you see what I’m saying. :) The numbers are off, I suspect for some kind of whitespace offset or newline offset. I finally realized you had a link for me to follow to see that graphic. Yes…how did you produce that?
-
Edit: Yes, they are character/caret positions, so I see and you see what I’m saying. :) The numbers are off, I suspect for some kind of whitespace offset or newline offset. I finally realized you had a link for me to follow to see that graphic. Yes…how did you produce that?
They are positions of start and end pairs of a match. I consider the start pos as off by 1. Produced by stdout with some debugging code that the Python script captures and processes it into html. It gives a reasonable visual of the matches, though not perfect as the missing unclosed span tag probably due to overlapping zones.
But, again…the endclass should be ignored, inside comments. Period. :)
You can state that, though the reality is that you may need to work with the parser as it is. I could state it is the pattern that needs fixing as it trys to handle everything from
classtoendclass. Demands have no relevence without reason.To answer your question, yes, we needed to have the endclass found to close the class.
Not sure why. The pattern searches to the
endclassand yet the pattern does not properly handle code in comments. Seems like an issue with the pattern as it wants to do this rather large match. To blame the parser for the greedy pattern seems unreasonable.The subject is not about the C++ functionlist so is opening a new argument. I mentioned the
pascal.xmlwhich Pascal usesbeginandend, though as I mentioned, the Pascal patterns do not look for theendkeyword.The way I see it is that the patterns need to work with the parser. The parser will probably not be changed to make up for patterns that fail to work due to being large. The maintainer IMO will not risk all the functionlist patterns in use to make you or your developer happy even if it were possible. There is a bash functionlist file issue at least 2 years old and risking the other functionlist files could be a bad option. Suggest you fix the pattern.
-
@mpheath said in functionList not ignoring comments:
You can state that, though the reality is that you may need to work with the parser as it is. I could state it is the pattern that needs fixing as it trys to handle everything from class to endclass. Demands have no relevence without reason.
I will have to respectfully, disagree.
The pattern works. It has been working. It continues to work.The problem is the parser, and in particular, the commentZones code, in this instance.
If developers don’t comment their code, the parser is safe, but that’s not realistic, either. The simple fact is, the parser doesn’t recognize comments inside a class. It recognizes it before, or after, but not inside…particularly when those comments have actual keywords. Perhaps, you could say, it’s the Zone that is the problem, as it doesn’t recognize when something (a class in this instance) has not ended, but has comments started inside it. Multi-line comments, in this case, and it is the parsers weakness that it doesn’t realize it’s still inside a class. That’s why the classrange element has these:
openSymbole ="\{" closeSymbole="\}"And the parser makes calls like this:
bool FunctionParsersManager::getZonePaserParameters(TiXmlNode *classRangeParser, generic_string &mainExprStr, generic_string &openSymboleStr, generic_string &closeSymboleStr, std::vector<generic_string> &classNameExprArray, generic_string &functionExprStr, std::vector<generic_string> &functionNameExprArray)It can’t possibly parse a zone, if it doesn’t know the beginning and end of it.
It’s because the parser doesn’t allow keywords to be used in the open and close
Symbole, that having to findendclassbecame necessary.Another way to work around this is not to put block comments inside a class, because the parser doesn’t work like a real parser. It’s a quasi-parser. That kind of encourages not commenting code, which seems like it is encouraging a bad habit that is already rampant. Either way, you can’t reasonably expect the parser to work properly if it doesn’t allow the parserLanguage.xml to define it’s open and close pattern, and that’s what this parser is doing, and so this pattern was improvised to make the parser function.
So please, don’t disparage the pattern. I’d like to think some really talented people created it, sans myself, right @PeterJones ? :)
-
@Lycan-Thrope Try changing line 91 in testd.xml
(?si:.*?^\h*endclass) # must match all the way to 'endclass'to
(?si:.*?^\h*(?!//\h*)endclass(?!\s*\*/)) # must match all the way to 'endclass'if
endclassis preceded by//or followed by*/then it is probably commented.commentZone: 51, 209 commentZone: 213, 409 funcZone: 411, 432 classZone: 0, 460 funcZone: 462, 487Instead of 2 classZones as before, now there is only 1 classZone.
-
@Lycan-Thrope said in functionList not ignoring comments:
So please, don’t disparage the pattern. I’d like to think some really talented people created it, sans myself, right @PeterJones ? :)
But those talented people aren’t infallible (at least, I know I’m not), and might not have considered all edge cases.
You seem to be expecting the parser to be running two regex simultaneously – the comment regex and the class regex. Because you seem to expect that it can see the beginning of a class, then, while parsing the single class regex to grab the whole class from
classtoendclass, that it simultaneously sees a comment using another regex while the class-regex is still active, and can recognize that theendclassis commented out, to prevent the class-parsing regex from seeing it. Running two regex simultaneously would be a pretty awesome design if you could make it work… but I doubt that’s what was implemented.Alternately, one could develop a system where the entire source file is parsed using the comment regex, and the comments are all deleted from the in-memory version of the file. Then that shrunken/de-commented in-memory file is run through the class parser, which then couldn’t see anything that used to be in the comments. If I were to have all the experience I have now with Notepad++'s Function List parser, and were to be writing a Function List-like parser from scratch, I think this is the direction I would go (if I could remember to do so). But based on my previous experience with FunctionList, and your descriptions above, that’s obviously not how Notepad++'s parser is written.
Thus, we’re left with the situation as implemented, where it seems (without my having studied N++'s FunctionList source code) that the comment regex is used to avoid starting a new class (or, I believe, standalone function), but that once it starts the class’s (or function’s) regex, it is up to the regex expression to make sure that comments inside that block are ignored while trying to determine the end of the block. (I think it’s not as much of a big deal for functions, because usually the expressions for those are looking for just the function name, not the whole function block). Hence, @mpheath has encouraged you to edit the regex in such a way as to ignore comments when looking for
endclass, and even shown an example of how to do that. -
@mpheath said in functionList not ignoring comments:
(?si:.?^\h(?!//\h*)endclass(?!\s**/))
1.) Thank you. It works.
2.) I humbly, thank you and now, see what you were referring to with regard handling the comments inside the regex…I was again trying last night/this morning before I retired, to try different things like you did, but obviously don’t have the chops that I thought I had. :)
@PeterJones , in his follow-up message almost points out how I thought the parser worked.
My impression, was that when it was inside the class zone, it would would read until the
endclassand if a commmentZone was encountered, it would ignore reading anything inside, regardless what was in it until it found the end of the commentZone, and then would continue on with it’s previous Zone since it did not find it’s end. In that regard, it would be like a switch, with it’s recursion, like how a function in code works (It seemed like the logical explanation) where it would stop basic operation there until it finished the commentZone, and then return to it’s previous task. Maybe, that is the way it works, but the weak point was, we’re not able to use a keyword, only a character symbol, so I can see, now, why you meant it needed to deal with comments in the regex pattern itself. My thoughts were that was why we defind the comment regex prior to the pattern searching.So I accept that this was, again, user error. Mine. :)
Thank you again.
-
Never expected you to be perfect, Peter, but you’re pretty close. :)
As in my reply to @mpheath , you’re mostly right about how I thought the parser worked. The exception was that I didn’t necessarily think it was running two regex simultaneously, but that it would know where the commentZone was, perhaps based on the commentZone character positions it uses, and turn off the reading/consumption mode of the class regex while inside a marked commentZone, basically ignore it until it came to the
*/mark, and then continue reading the class.I guess I was just confused about how I was supposed to alter the regex to deal with comments, as I wasn’t sure what he meant, since he seemed to be saying I needed to stop the pattern from seeking the
endclass, which we couldn’t, because otherwise the class pattern would never be recognized. I know, I tried it last night, as that’s what I thought he was referring to, and all the functions inside and out showed up, but not the classes, so I knew that endclass keyword had to stay. I’ll have to chalk this misunderstanding to my lack of experience, which, thanks to his above solution, I can be a little wiser…not much…but a little. :) -
@mpheath ,
Just a futher follow up. After the initial fix worked for the example file presented, we have again found the issue rearing it’s head elsewhere, so while it temporarily fixed the issue, I feel the only real fix for this issue, will need to be the code allowing for keywords like class/endclass for the open and close demarcations that the classrange element expects for locating those zones.I’m trying to get myself up to speed somewhat in C++ so I can at least read the code with a little more knowledge and see if I can’t figure out how to find and change what I think needs to be changed and I guess do a pull request and muck it up. :)
Thanks anyway, and I think this subject here will at least let people know if they find this issue in their functionList implementation of their language, if it has a mixed parser, this is a possible explanation for the problem.
-
@mpheath ,
After going over a lot of stuff, including reexamining the FunctionList FAQ, I have to agree with you, that at present, I may need to work with the parser, as is. I must have missed that ‘embedded comments’ section, or glossed over it, or didn’t relate it to the kind of comments we do as the example seemed to be an example of excessive use of inline ‘block’ comment style for an inline comment. That may be what threw me as regards that example in the FAQ.
Moving the opening class declaration line after any block comments immediately following it, fixes the problem completely, with my recent testing. It appears, however, that as I discovered before, line comments inside a class taking up a whole line, or after code, inside a class/endclass block does indeed work as it should.
So I guess until I get up to speed with C++ and take a crack at a fix for the
block commentsgiving problems inside aclass/endclasscode block, block comments will have to be avoided.I do, however, feel that the simple fix for this, should be just allowing a longer string other than
\{and\}symbol characters would be a proper fix, since being able to useclassandendclassin the open/close symbole elements, it would be part of the actual parser demarcation ability to know where a class starts and ends, rather than having to use regex to find all the way to the end like this regex had to do to be able to outline the structure of the class. For now, the crisis is averted until I can revisit this issue, hopefully with some C++ skills at a later date. :)