Python: Multiple files ANSI to utf-8 converter
-
hello, I want to use “Python Script” Plugin as to convert multiple files to UTF-8 (not UTF-8-BOM), on a particular folder.
Can be this done?
-
@Hellena-Crainicu
This script (not a PythonScript plugin script, because that’s not really the most effective solution) should do what you want:''' This should be used as a script from the terminal. Relevant documentation: * https://docs.python.org/3/howto/unicode.html * https://docs.python.org/3/library/glob.html * https://docs.python.org/3/library/os.html#module-os * https://docs.python.org/3/library/argparse.html example usage: >python -m encoding_conversion . utf-16 utf-8 *.txt changing encoding of example2.txt from utf-16 to utf-8 changing encoding of example4.txt from utf-16 to utf-8 changing encoding of example3.txt from utf-16 to utf-8 changing encoding of example1.txt from utf-16 to utf-8 changing encoding of example5.txt from utf-16 to utf-8 >python -m encoding_conversion "example directory" utf-8 utf-16 *.md changing encoding of new 2.md from utf-8 to utf-16 changing encoding of new 3.md from utf-8 to utf-16 changing encoding of new 1.md from utf-8 to utf-16 ''' import os def change_encoding(fname, from_encoding, to_encoding='utf-8') -> None: ''' Read the file at path fname with its original encoding (from_encoding) and rewrites it with to_encoding. ''' with open(fname, encoding=from_encoding) as f: text = f.read() with open(fname, 'w', encoding=to_encoding) as f: f.write(text) if __name__ == '__main__': import argparse import glob parser = argparse.ArgumentParser() parser.add_argument('dirname', help='name of directory in which you want to change file encodings') parser.add_argument('old_encoding', help='the previous encoding of files found') parser.add_argument('new_encoding', nargs='?', default='utf-8', help='the new encoding that you want to change to') parser.add_argument('include_files', nargs='*', help='filename patterns using glob syntax to choose') args = parser.parse_args() include_files = args.include_files if not include_files: include_files = ['*.*'] fnames = set() curdir = os.getcwd() try: os.chdir(args.dirname) for glb in include_files: fnames.update(glob.glob(glb)) for fname in fnames: print((f'changing encoding of {fname} from ' f'{args.old_encoding} to {args.new_encoding}')) change_encoding(fname, args.old_encoding, args.new_encoding) finally: os.chdir(curdir)Note that this doesn’t use Notepad++ for anything, because it is simpler to get the job done with pure Python.
You could probably modify this script to try to guess the encoding of files, but I’ve tried using automatic encoding detection in Python and it’s pretty hit-or-miss. If you’re really determined to try guessing encoding, try looking at codecs.
-
@Mark-Olson said in Python: Multiple files ANSI to utf-8 converter:
Ok, I change the lines. If I understand well enough:
help='d:\\2022_12_02\\word 2\\1') # name of directory in which you want to change file encodingshelp='ANSI') # the previous encoding of files foundhelp='*.txt') # filename patterns using glob syntax to chooseOk, I run the code in Python directly. Nothing happens…
import os def change_encoding(fname, from_encoding, to_encoding='utf-8') -> None: ''' Read the file at path fname with its original encoding (from_encoding) and rewrites it with to_encoding. ''' with open(fname, encoding=from_encoding) as f: text = f.read() with open(fname, 'w', encoding=to_encoding) as f: f.write(text) if __name__ == '__main__': import argparse import glob parser = argparse.ArgumentParser() parser.add_argument('dirname', help='d:\\2022_12_02\\word 2\\1') # name of directory in which you want to change file encodings parser.add_argument('old_encoding', help='ANSI') # the previous encoding of files found parser.add_argument('new_encoding', nargs='?', default='utf-8', help='UTF-8') parser.add_argument('include_files', nargs='*', help='*.txt') # filename patterns using glob syntax to choose args = parser.parse_args() include_files = args.include_files if not include_files: include_files = ['*.*'] fnames = set() curdir = os.getcwd() try: os.chdir(args.dirname) for glb in include_files: fnames.update(glob.glob(glb)) for fname in fnames: print((f'changing encoding of {fname} from ' f'{args.old_encoding} to {args.new_encoding}')) change_encoding(fname, args.old_encoding, args.new_encoding) finally: os.chdir(curdir) -
@Hellena-Crainicu
Correct, the intended use of the script (and pretty much any Python script with the lineimport argparsein it) is not to be modified directly, but rather to be used from the command line with arguments. The changes you made don’t alter the functionality at all, but rather change the help message displayed.I’ll just repeat the usage examples in my docstring at the beginning of the script.
>python -m encoding_conversion . utf-16 utf-8 *.txt >python -m encoding_conversion "example directory" utf-8 utf-16 *.mdThe former changes all utf-16 encoded text files to utf-8, the latter changes all utf-8 encoded markdown (
.md) files to utf-16. -
@Mark-Olson I still have a problem. I change everything on your code, as I post yesterday. I run again today, but I get thie error.
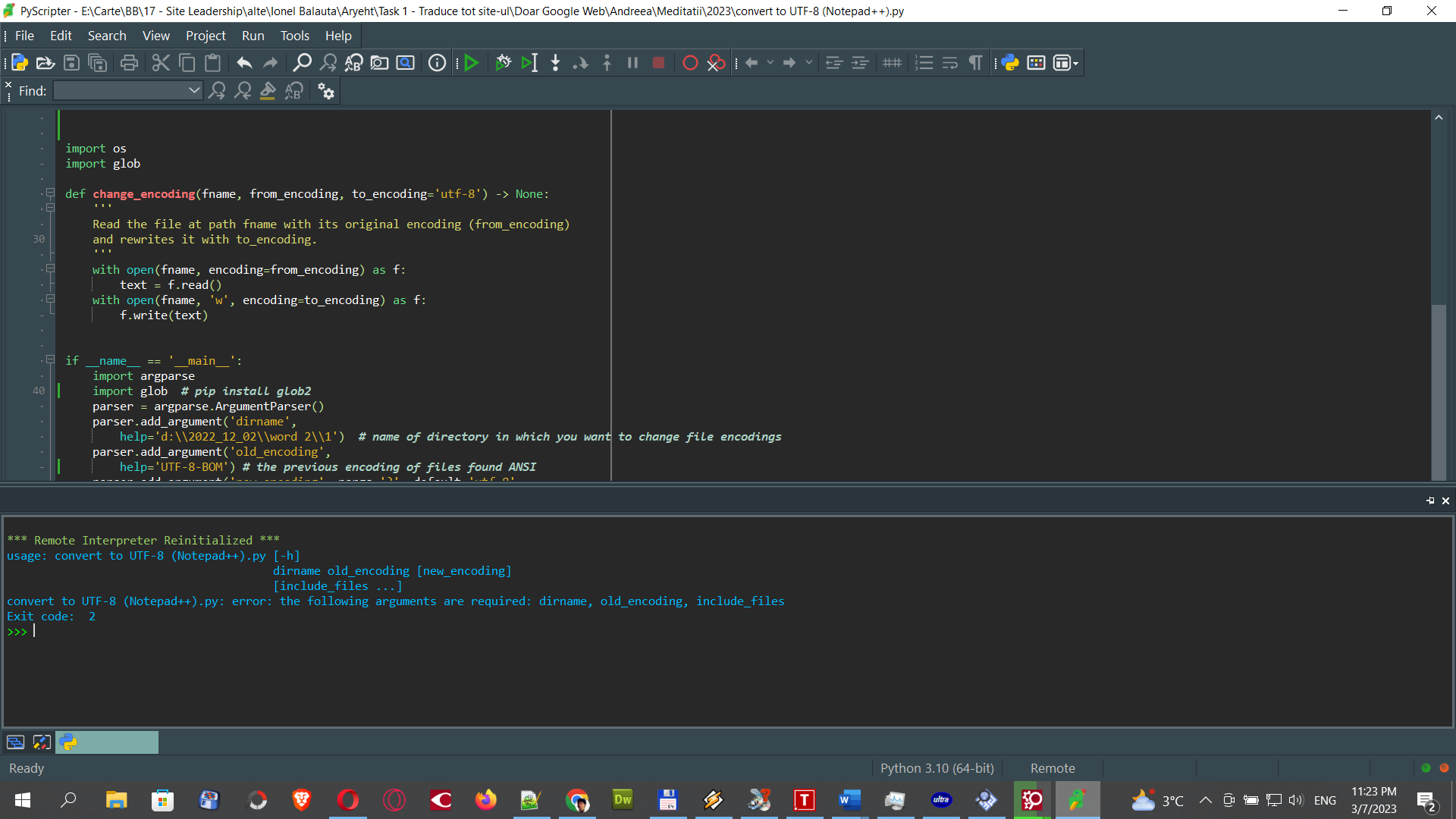
So, this is the code I run today, trying to change txt files from UTF-8-BOM to UTF-8. The error above. Doesn’t work the conversion. Why ? I put the dir name, the encoding, etc…
import os import glob def change_encoding(fname, from_encoding, to_encoding='utf-8') -> None: ''' Read the file at path fname with its original encoding (from_encoding) and rewrites it with to_encoding. ''' with open(fname, encoding=from_encoding) as f: text = f.read() with open(fname, 'w', encoding=to_encoding) as f: f.write(text) if __name__ == '__main__': import argparse import glob # pip install glob2 parser = argparse.ArgumentParser() parser.add_argument('dirname', help='d:\\2022_12_02\\word 2\\1') # name of directory in which you want to change file encodings parser.add_argument('old_encoding', help='UTF-8-BOM') # the previous encoding of files found ANSI parser.add_argument('new_encoding', nargs='?', default='utf-8', help='UTF-8') parser.add_argument('include_files', nargs='*', help='*') # filename patterns using glob syntax to choose args = parser.parse_args() include_files = args.include_files if not include_files: include_files = ['*.*'] fnames = set() curdir = os.getcwd() try: os.chdir(args.dirname) for glb in include_files: fnames.update(glob.glob(glb)) for fname in fnames: print((f'changing encoding of {fname} from ' f'{args.old_encoding} to {args.new_encoding}')) change_encoding(fname, args.old_encoding, args.new_encoding) finally: os.chdir(curdir) -
@Mark-Olson Mark Olson: please check my code, and the replacements I made, and tell me what is wrong.
-
This topic has delved into off-topic land for Notepad++ discussion. I doubt anybody wants to debug your code, but on the offhand chance that Mark does, why don’t you two take this discussion off into a private chat?
-
@Alan-Kilborn yes, sure, I will use chat. thanks
-
Note that this doesn’t use Notepad++ for anything,
I appreciate your willingness to help. However, we need to focus this Forum on Notepad++. If it’s something that can be done in PythonScript, and you are interested in providing the solution, please make it compatible with PythonScript. This forum isn’t for “generic” Python code-writing.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login