Looking for string search that includes the & mnemonic
-
So, assuming you have text like
E&xtended area &New drawing Add &Shape… and you wanted to search for
Extend areawith & being allowed in any of those positions, you would have to use something like&?E&?x&?t&?e&?n&?d&?e&?d&? &?a&?r&?e&?a&?, and it has to be in Regular Expression search mode for that to work. The&?will look for 0 or 1 instance of a literal&in your text, so putting that before/after every character will allow & to show up anywhere in the string. Unfortunately, there’s no “easy” way to simplify if you’re looking for those.If you’re going to have multiple of those, like searching for
New drawingandAdd Shapelater, I’d probably set up a dummy file which has all of the raw text, likeExtended area New drawing Add &Shape… then do a regex search/replace to generate your regex:
- FIND =
(^|[\h\w])(?!&)– look for beginning of line, or any horizontal space or alphanumeric that isn’t followed by an& - REPLACE =
$0&?– replace with that original string and then&? - Search Mode = Regular Expression
- Replace All
This will create a list of regex, like
&?E&?x&?t&?e&?n&?d&?e&?d&? &?a&?r&?e&?a&? &?N&?e&?w&? &?d&?r&?a&?w&?i&?n&?g&? &?A&?d&?d&? &S&?h&?a&?p&?e&?You can then copy each of those regex and paste into FIND WHAT, then go into your real document, and do the search.
Alternately, if you don’t care about remembering where the
&was falling in the English strings, and just want the raw English strings for easily translating to Spanish, and then you’ll later manually add in&where it makes sense for Spanish, I might suggest to just replace&with the empty string in the English source, then you’d just have raw English for translating.You might also consider looking into using my “translation bot” script for the PythonScript plugin, found in this post. You could then have the left side of the translation table be the complicated regex with all the
&?already inserted, and the right be the Spanish equivalents, putting your single & wherever it should go in the Spanish, liketranslation = { r'&?E&?x&?t&?e&?n&?d&?e&?d&? &?a&?r&?e&?a&?': r'Área e&Xtendida', r'&?N&?e&?w&? &?d&?r&?a&?w&?i&?n&?g&?': r'&Nuevo dibujo', r'&?A&?d&?d&? &S&?h&?a&?p&?e&?': r'Agregar &Forma', }(caveat: that was just my simple Google-translate for the three English phrases; I have no clue if those are the common Spanish idioms for those menu commands, and I make no guarantee or warranty as to the usefulness of those translations.)
All the regex above assume simple text requirements. If you’ve got a complicated mix where you want some of the & in your text to remain unedited and others to be found/replaced, you’re going to have to make the regex more complicated than I showed. Just keep in mind that
&?means 0-or-1-&and you need that in any position in the regex where you might find a&or might not. - FIND =
-
@Mario-Chávez said in Looking for string search that includes the & mnemonic:
I need to find a way to either include & at any position in the string to capture all instances of a command, or to ignore & so that the search returns cover both the command with & and without &.
@PeterJones I might have found a slightly better way than having to include the
&?at every possible position. It’s still a bit rough but I’m happy to put it up for public scrutiny to see if anyone may be able to fine tune it.
Find What:\b[new&]{3,4}\bSo this is to find any word that isnewand may contain a possible & in any position. For the word “extend” it would be\b[extend&]{6,7}\b.It could potentially grab a word that contains as many characters as dictated (within the class stated) but not be the word that is being looked for but I think that would be preferable to missing any potential words.
Terry
-
It seems an interesting approach…that I haven’t yet thought too much about. But I wanted to share something else, as it appears you are going to do more thinking on it:
A similar problem to the OP’s that I have is I often search
english.xmlin Notepad++ source code, and I’m always surprised when text I “know” is there doesn’t yield any hits. It is inevitably because of an embedded&string somewhere.So for example, if I’m looking for
Save a Copy AsI might search forcopy as. And there I’m disappointed because I don’t get the hit I’m seeking; I’d have to search forcop&y asto find it.So I guess what I’m saying is, as you mature your technique, please also consider embedded expressions (and perhaps even embedded regular expressions??) as well as the OP’s simple single-character-embedded situation.
-
@Terry-R ,
Interesting idea. Given that anagrams of
Extend areaare not likely to be found as other menu entries, it’s probably pretty safe. But if @Mario-Chávez chooses to go in that direction, I’d recommend making a backup copy first, and look for unexpected matches as the search is being performed, or at least after replacements are done. -
@PeterJones said in Looking for string search that includes the & mnemonic:
iven that anagrams of Extend area are not likely to be found as other menu entries, it’s probably pretty safe.
As @Alan-Kilborn pointed out, I was doing some more thinking, specifically with regards to the “anagram” possibility.
My latest regex is
(?=.?s.?h.?a.?p.?e)(?<!\w|&|\S)[shape&]{5,6}(?=\W|\s). It is now starting to look a bit complex, the only benefit is that even a novice could edit it for the word replacement.For those who are having difficulty in understanding the regex we have:
(?=.?s.?h.?a.?p.?e)- looking for the general shape of word, thus each.?caters for a single other character (in this case the &). It’s non-specific on how many of these other characters exist, just that they can exist and in only the positions designated. this removes the anagram issue.
(?<!\w|&|\S)- at the position of the caret, we want the character preceding to be none of the following, a word character, a & or a non-space.
[shape&]{5,6}tries to identify 5 (or 6) characters that are made up of the characters within this class defined by the[and the].
(?=\W|\s)- at the position of the caret we want ahead either of the following characters, a non-word character or a space.So for another word such as
extendedwe would have
(?=.?e.?x.?t.?e.?n.?d.?e.?d)(?<!\w|&|\S)[extnd&]{8,9}(?=\W|\s)
Please note that I did not type inextendedinto the[]class, on purpose. Theeanddalready exist once, there is no need to type them twice (although I could have as it would not create an error). The{8,9}takes care of the requirement to have the correct number of characters comprising the word we seek.Please note that this is still a “work in progress”. I’m still not entirely happy with the regex, although I am fairly sure it will not select any words not wanted.
Look forward to any feedback, or even if someone else wants to take up the challenge. I’m interested to see where this might go, even to solving @Alan-Kilborn requirement.
Terry
PS I should add that I’m aware that part of it does look very similar to @PeterJones version. There is a difference in that I think my version tightens the requirement as it specifies multiple methods of determining the correct word. As I say, I’m not entirely happy though that it is a much longer regex
-
@Terry-R said in Looking for string search that includes the & mnemonic:
As I say, I’m not entirely happy though that it is a much longer regex
Well I wasn’t happy, in the end I figured my last idea wasn’t going down the right track.
I remembered an old post from @PeterJones that was to count a line length excluding specified characters, #18704. The basis of the solution lies there, so I can’t claim ownership of the idea. So Find What is (for the word
extendedwith/without a&attached to the word([&]*[extnd][&]*){8,9}. Note that if there will never be a preceding&(no &extended), rather it will always be embedded or trailing, then it can change to([extnd][&]*){8,9}or([extended][&]*){8,9}could also be used for ease of typing in the word. So we are back to a short regex, but at the moment it could select another word which is of the same length and uses characters within the class range, like an anagram. A method of minimising that possibility lies with using lookaheads to find both starting character and ending character of the word to identify they match. It still does not guarantee excluding a similar word which fits but should greatly minimise the chance I think. That would look something like this,(?=&?e[^\x20]+d)([&]*[extended][&]*){8,9}or(?=&?e[^\x20]+d)((&)?[extended](&)?){8,9}. For those unsure, the \x20 is the space character which can be entered instead.Perhaps some benefit of this solution is that the “excluded” characters could be altered to be anything and any length. All that is required is to cater for the 2 different lengths of the word and type in the correct 2 numbers trailing (i.e. {8,9}). So this idea may also help @Alan-Kilborn with his need. For the word “Macro” with
&possibly attached to the word at any position we would have"((&)?[macro](&)?){5,10}". Note I have changed the excluded characters from a class range to an optional group. So if the excluded characters were to exist they must exist in their entirety and in the same order. I’ve included the quotes as I used the english.xml file for testing. Again it will need modification in regards how it is used.At this point I think I’ve used up enough spare time on this. This will only ever be an approximation, unless a vastly more complex regex was created, which then negates the ability of novices to use and alter for different words.
Terry
-
Hello, @mario-chávez, @peterjones, @terry-r and All,
Here is an other approach to the problem !
Let’s start with, for instance, this INPUT text :
Extended areaAs it contains
13characters, we’ll use this first regex S/R :SEARCH
(?-s).+REPLACE
$0$0$0$0$0$0$0$0$0$0$0$0$0(13times the string$0)and we get the temporary text :
Extended areaExtended areaExtended areaExtended areaExtended areaExtended areaExtended areaExtended areaExtended areaExtended areaExtended areaExtended areaExtended area
Now we’ll use this second regex S/R :
SEARCH
(?-s)(^(?=.)|.{14})\K(14= String characters count +1)REPLACE
&And the temporary text becomes :
&Extended areaE&xtended areaEx&tended areaExt&ended areaExte&nded areaExten&ded areaExtend&ed areaExtende&d areaExtended& areaExtended &areaExtended a&reaExtended ar&eaExtended are&a
Finally, with this third regex S/R :
SEARCH
(?-i)^(&)|(a)(?=E)( The lettersaandEare, respectively, the last and the first characters of the initial string )REPLACE
(?1\(?-i\)&)?2\2|We get the following OUTPUT text which can be used to search for any syntax of the
Extended areastring containing a single&character :(?-i)&Extended area|E&xtended area|Ex&tended area|Ext&ended area|Exte&nded area|Exten&ded area|Extend&ed area|Extende&d area|Extended& area|Extended &area|Extended a&rea|Extended ar&ea|Extended are&aIndeed, the following search regex :
SEARCH
(?-i)&Extended area|E&xtended area|Ex&tended area|Ext&ended area|Exte&nded area|Exten&ded area|Extend&ed area|Extende&d area|Extended& area|Extended &area|Extended a&rea|Extended ar&ea|Extended are&amatches one only of the strings below :
&Extended area E&xtended area Ex&tended area Ext&ended area Exte&nded area Exten&ded area Extend&ed area Extende&d area Extended& area Extended &area Extended a&rea Extended ar&ea Extended are&aBest Regards,
guy038
P.S. :
I personally verified that putting an
&character, right before aspacechar gives a functional access keyAlt, ... , ..., Space bar, in Notepad++ ! -
@guy038 said in Looking for string search that includes the & mnemonic:
verified that putting an & character, right before a space char gives a functional access key Alt, … , …, Space bar, in Notepad++ !
I didn’t try it myself, but what’s the
... , ...part of that? -
Hi, @alan-kilborn and All,
EDIT : I modified the second line
<Item id="42037" ...
I first verified with an old portable N++ version
v7.2! Here is an updated example with the recentv8.5release !So, for a portable version :
-
Start Notepad++
-
In
Settings > Preferences... > Localization, choose theEnglish (customizable)option -
Click on the
Closebutton
=> N++ automatically creates the
nativeLang.xmlfile, along with all other files-
Open this
nativeLang.xmlfile in Notepad++ -
Change, for instance, the line :
<Item id="42037" name="Column Mode..."/>with :
<Item id="42037" name="Column& Mode..."/>-
Save the modifications of the
nativeLang.xmlfile -
Exit Notepad++
-
Restart Notepad++
-
Whatever the current tab seen, hitting, successively the keys
Alt,EandSpace barshould show theColumn Mode Tippanel !
BR
guy038
-
-
This discussion thread has reminded me of ANOTHER. In that other thread, I don’t think we truly achieved satisfaction.
But I think in this current thread, we might be able to get satisfaction, with a script, I’ll call it
SearchWhileIgnoringEmbeddedExpression.py:# -*- coding: utf-8 -*- from __future__ import print_function # see https://community.notepad-plus-plus.org/topic/24280/looking-for-string-search-that-includes-the-mnemonic from Npp import * import inspect import os class SWIEE(object): def __init__(self): self.this_script_name = inspect.getframeinfo(inspect.currentframe()).filename.split(os.sep)[-1].rsplit('.', 1)[0] user_input = '' didnt_just_wrap = True while True: if didnt_just_wrap: user_input = self.prompt('Enter possible embedded expression then Ctrl+Enter\r\nthen search text then press OK to find next', user_input) if user_input == None: return # user cancel line_list = user_input.splitlines() if len(line_list) != 2: continue possible_embedded_expr = line_list[0] char_list = list(line_list[1]) embedded_portion_regex = '(?:' + possible_embedded_expr + ')?' search_regex = '(?i)' + embedded_portion_regex + embedded_portion_regex.join(char_list) match_list = [] start_pos_for_search = editor.getCurrentPos() if didnt_just_wrap else 0 didnt_just_wrap = True editor.research(search_regex, lambda m: match_list.append(m.span(0)), 0, start_pos_for_search, editor.getLength(), 1) if len(match_list) == 0: if self.yes_no('No (more) matches -- wrap around and keep searching?'): didnt_just_wrap = False continue return else: (match_start, match_end) = match_list[0] editor.scrollRange(match_end, match_start) editor.setSelection(match_end, match_start) def yes_no(self, question_text): # returns True(Yes), False(No) answer = self.mb(question_text, MESSAGEBOXFLAGS.YESNO, self.this_script_name) return True if answer == MESSAGEBOXFLAGS.RESULTYES else False def prompt(self, prompt_text, default_text=''): if '\n' not in prompt_text: prompt_text = '\r\n' + prompt_text prompt_text += ':' return notepad.prompt(prompt_text, self.this_script_name, default_text) def mb(self, msg, flags=0, title=''): # a message-box function return notepad.messageBox(msg, title if title else self.this_script_name, flags) if __name__ == '__main__': SWIEE()If we take some data:
&Extended area E&xtended area Ex&tended area Ext&ended areaAnd run the script on it, we get prompted with:
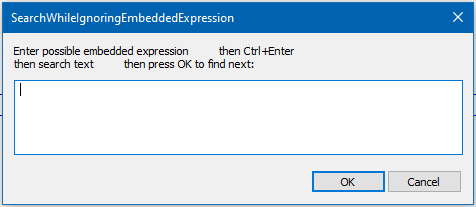
We enter:
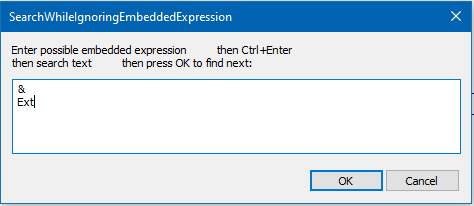
And click OK and we are jumped to the first match:
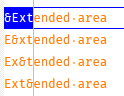
We are reprompted to continue the search, doing so results in a match where
&is embedded inside the other data:
Continuing to press OK to the scripts prompting, we continue the search until we are out of matches. When this occurs, we get prompted to “wrap”:
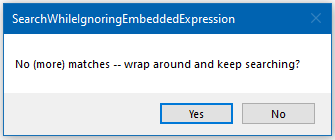
That’s all, folks.
-
 A Alan Kilborn referenced this topic on
A Alan Kilborn referenced this topic on
-
Hello, @alan-kilborn and All,
I just tried your
Pythonscript and it works nice !I noticed that the search is a non-sensitive search, which is correct as, for example, the Microsoft access keys
&eand&Eproduces similar resultsThe nice thing is that your
embedded expressionmay contain more than1character ;-))BR
guy038
-
@guy038 said in Looking for string search that includes the & mnemonic:
The nice thing is that your embedded expression may contain more than 1 character
Yes.
So that my earlier example:
cop&ywhere I want to logically search for
copyand not worry about an “embedded”&, is handled by the script. -
@guy038 said in Looking for string search that includes the & mnemonic:
I noticed that the search is a non-sensitive search
If you wanted a “sensitive” search you could add
(?-i)to the start(s) of the expressions you input at the prompt.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login