Syntax highlighting and file enconding and the Windows code page (1252 or 936)
-
The syntax highlighting in the CSV Lint plugin doesn’t work correctly in all cases. There is an issue when the Windows code page is 936 = Chinese character set and the text file is UTF8.
I want to fix the issue but it’s not as easy as I thought. There are 3 different parts that need to be coordinated properly for the syntax highlighting to work correctly.
- Scintilla StartStyle / SetStyle parameters
- CSV Lint Lexer and iterating over the characters
- Windows code page and string encoding
The first point, the syntax highlighting colors in Notepad++ are set using is Scintilla
StartStylingandSetStyleFormethods.
These functions require the byte position as parameters, this is the same as when you move the cursor around the text file and look at thePosnumber at the bottom in the status bar. Notice how the test file has 36 characters but the length is 58 bytes, so some characters are 1 byte and some characters are more than 1 byte.When Windows is set to use code page 936 (Chinese), then the test files require different parameters to get the correct colors in the UTF8 file and the ANSI file.
I tested it by setting the positions hardcoded and then looking at the results, see screenshots below.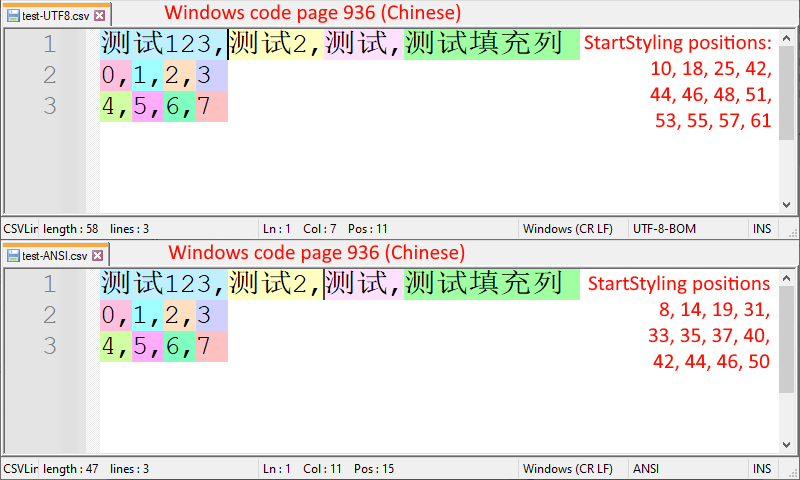
The second point is the way the Lexer iterates through the characters and searches for the separator character. The idea is to iterate through the characters, check if it is the next separator character and call the
StartStylingandSetStyleForfunctions accordingly. However as mentioned, the character count and the bytes/position count is different.
Currently the plug-in gets the text range using
GetCharRange, and thenMarshal.PtrToStringAnsiand thenByteStream.GetBytes,
see code hereIt’s probably due to the encoding when getting the bytestream in the custom function, but it’s not obvious to me what should be to change here, and wether that is the only thing that is needs to be changed.
The third thing is the Windows code page and the internal string encoding, but I think that works mostly correct now after some changes in this commit by @rdipardo
-
Without thinking too carefully about your requirements or whether this will actually help much, I came up with this function for calculating the number of UTF8 bytes in a range, adjusted slightly from something I use in JsonTools. For an entire string you’d use
Encoding.UTF8.GetByteCount(string s), but the below function could maybe be adjusted to your needs:public static int UTF8BytesBetween(string text, int start, int end) { int utf8Bytes = end - start; // start by assuming pure ASCII for (int ii = start; ii < end; ii++) { char c = text[ii]; if (c > 127) // not ASCII { if (c < 2048 || (c >= 0xd800 && c <= 0xdfff)) // one char in a surrogate pair (e.g., half of an emoji) // or just a low non-ASCII thing utf8Bytes++; // some non-surrogate big char like most Chinese chars else utf8Bytes += 2; } } return utf8Bytes; } -
Wait a minute, I just realised that it is converting a bytebuffer to a string and then back to a byte buffer. It should just convert the content buffer straight to a byte array and work with that.
I’ve tested it with the code page 936 and 1252 and it seems to work correctly in both cases.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login