ComparePlus - improve alignment of similar lines
-
Hello, @stefan-pendl, @mark-olson, @tbugreporter and All,
I’ve tried to understand what @stefan-pendl meant but, even with the help of the
Compare Plusplugin, I could not understand which kind of alignment was desired :-((@stefan-pendl, could you try to shorten your
File_1, to the approximative number of lines ofFile_2, in order to easily identify where alignments must occur, when running theCompare Plusplugin ?Best Regards,
guy038
-
@guy038
The problem is, that if I shorten the file, the issue is gone.
It only happens when the files are really different. -
@Stefan-Pendl said in ComparePlus - improve alignment of similar lines:
It only happens when the files are really different.
Well then, that’s the problem. Diff/alignment algorithms try their best, but if two files are really different, you shouldn’t be too surprised if it seems like the alignment is bad. Even Git’s diff algorithm, which is probably the best around, produces diffs/alignment that seem suboptimal when the diff is big.
-
@Stefan-Pendl said in ComparePlus - improve alignment of similar lines:
I am not completely sure I understand the right way you mean about Improve alignment but maybe these suggestions can be also useful:
replace spaces with tabs and install and activate the Elastic Tab Stop Plugin: with it is possible to get alignment like the following screenshot: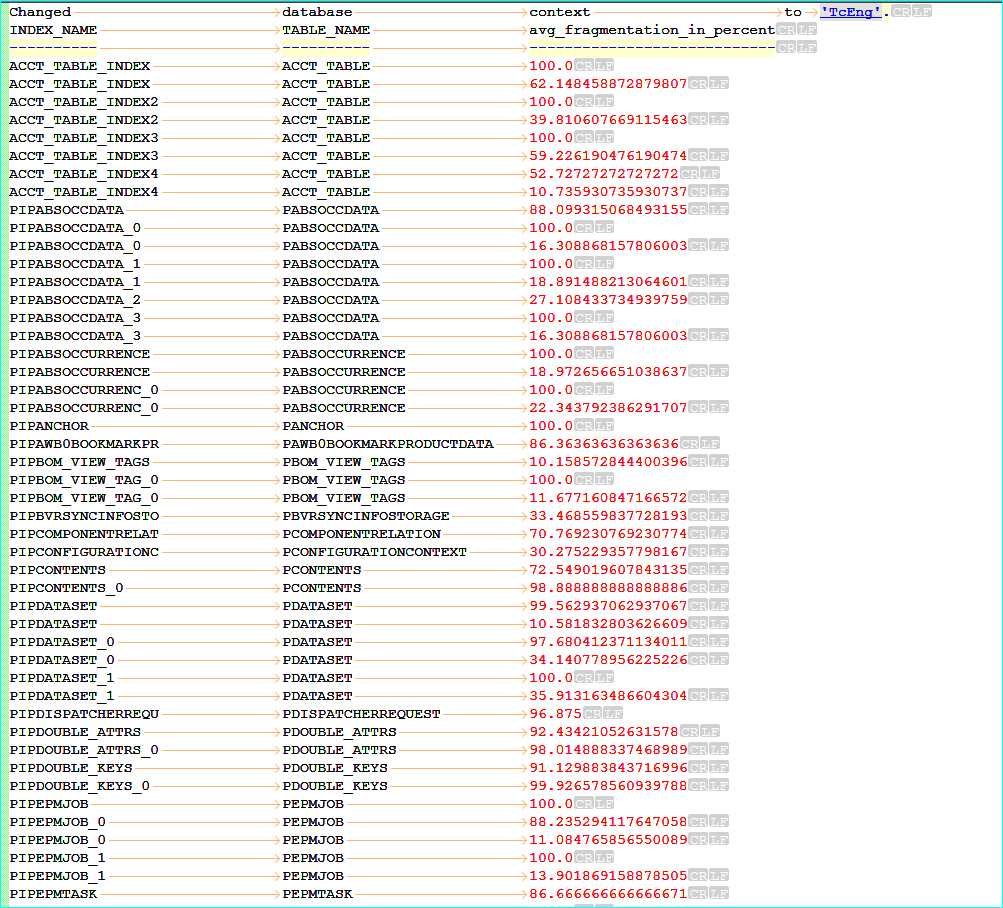
If you prefer you can use another plugin: CsvQuery to get alignment as the following screenshot:
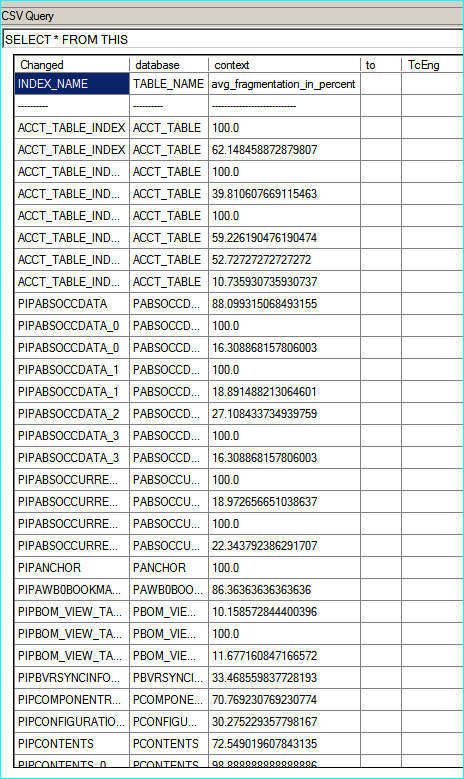
Right click on CsvQuery plugin window and show the line numbers like the following screenshot is also possible:
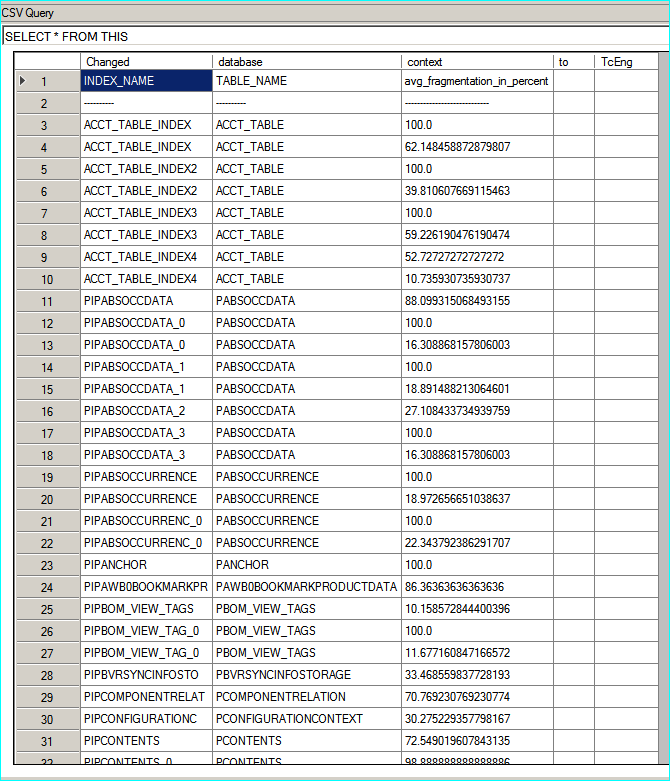
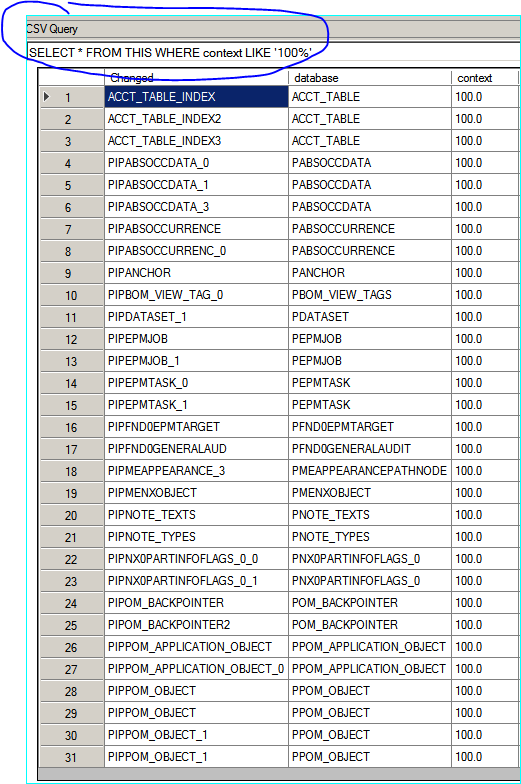
with CsvQuery You can also query the database using SQL syntax to filter the rows using criteria you need.
-
@wonkawilly
Thanks for that, but I did not mean the alignment of columns, but the alignment of the diff result => lines starting with the same word should be aligned, not lines with a similar word. -
@Stefan-Pendl IMO, not the correct plugin for the job. Try PythonScript plugin.
- Open the 2 documents in separate views (view1 (main) and view2 (extra)).
- Run the script named
DBMergeReport.pyand it will open a new tab on the focused view with the merged report.
import re def db_merge_report(): def get_dic(text): dic = {} for m in re.finditer(r'^(\w+ \w+) ([\d.]+)\r{0,1}$', text, re.M): k = m.group(1) dic[k] = m.group(2) return dic text1 = editor1.getText() text2 = editor2.getText() dic_a = get_dic(text1) dic_b = get_dic(text2) names = set(dic_a) | set(dic_b) names = sorted(names) length = max(len(item) for item in names) text1 = '' for name in names: a, b = '', '' if name in dic_a: a = dic_a[name] if name in dic_b: b = dic_b[name] text1 += ('{:<' + str(length + 1) + '} {:<20} {}\n').format(name, a, b) if text1: notepad.new() editor.addText(text1) if __name__ == '__main__': db_merge_report()New document tab with just the 1st 5 lines as an example.
ACCT_TABLE_INDEX ACCT_TABLE 62.148458872879807 89.86486486486487 ACCT_TABLE_INDEX2 ACCT_TABLE 39.810607669115463 70.634920634920633 ACCT_TABLE_INDEX3 ACCT_TABLE 59.226190476190474 100.0 ACCT_TABLE_INDEX4 ACCT_TABLE 10.735930735930737 PIPABSOCCDATA PABSOCCDATA 88.099315068493155The spacing is quite wide for the 1st column as the largest value is 58 characters. This might make comparison of the data being in 1 document alittle easier as the float numbers are next to each other.
-
Hello @Stefan-Pendl ,
I will check your case and if some improvements could be made but it might take time.
Could you please in the meantime tell me which lines should be aligned according to your expectations (except lines PIPDATASET_0 - I already got that)?
Thanks.BR
-
@pnedev said in ComparePlus - improve alignment of similar lines:
Could you please in the meantime tell me which lines should be aligned according to your expectations
Hello again @Stefan-Pendl ,
I analyzed your example data and I understand what you would expect as a result of the comparison. Please disregard my request for further clarifications.
BR
-
@pnedev
Thanks for checking this issue.
If you need more data just ask. -
Hello @Stefan-Pendl ,
I have just released ComparePlus v1.2.0 - it has a bug-fix for and overall improved changed lines detection algo - your example files compare as expected now.
It doesn’t mean that now the plugin will always consider the most intuitive lines as changed in all cases (that is simply not possible because of the different scenarios and user expectations) but it does a much better job now.I am sorry about the long time it took for releasing this update - there were also other pending issues that required attention and I didn’t had enough spare time to work on ComparePlus.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login