Selecting (phisically, not bookmarking) all the lines contianing a specific parameter or a specific word
-
@Maverick-F-16C said in Selecting (phisically, not bookmarking) all the lines contianing a specific parameter or a specific word:
I cannot make bookmarked lines also become selected, NOT just highlighted, so I can paste/delete/etc. anything over that selection.
I would think Search > Bookmark > Paste to (Replace) Bookmarked Lines (also available by right-clicking in the bookmark margin) would allow you to paste text overtop the bookmarked lines, Cut Bookmarked Lines or Remove Bookmarked Lines to delete the bookmarked lines, etc.
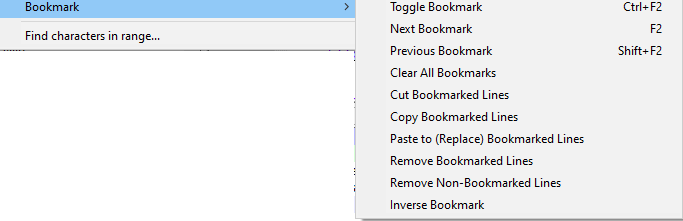
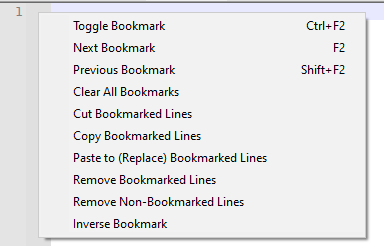
Does that not meet your needs?
-
Hello there Peter,
I have forgot to say that this didn’t work either. Sorry I forgot to tell that I’ve seen that function, tried it and instead of putting each line where it belongs, it actually puts all of the pasted data one after another making a mess. What you say is exactly how it should work, but it doesn’t…, it’s either a bug or maybe this is the most that this function can do, as it doesn’t paste each line in one file with it’s corresponding line in the other, but it actually pastes all the copied bookmarked lines at once inbetween say line 1000 and line 1001. It just puts it all inbetween those two lines.
So, if this would work properly or at least have a function to independently select lines (or bookmarked lines), it would do the job!
Kind regards,
Andrei!-–
moderator edited formatting; please do not indent paragraphs with spaces: it puts it into a text box which makes long paragraphs very difficult to read
-
@Maverick-F-16C said in Selecting (phisically, not bookmarking) all the lines contianing a specific parameter or a specific word:
, as it doesn’t paste each line in one file with it’s corresponding line in the other, but it actually pastes all the copied bookmarked lines at once inbetween say line 1000 and line 1001. It just puts it all inbetween those two lines.
Sorry, I was responding specifically about the inaccuracy of the statement that I quoted in my reply.
I hadn’t actually understood your full desire, which I now believe is really a conditional “interleave” (what others call a “merge”) of two files. So no, with that as your desired outcome, the bookmark feature is not going to work – nor is any other multi-selection feature (so your idea of converting bookmarks to selections of those lines would not have helped you, because you still could not have lined up the two files correctly)
What you are asking for is not possible in Notepad++ alone, and is really best suited to writing a script in your favorite programming language.
This recent discussion includes a script for the PythonScript plugin in Notepad++ that will perform one variant of an interleave-style merge (it’s looking to overlap so that if there’s no text on a specific line, then it will be overwritten with the text from that line) – but you might be able to change the logic in that script to customize it to your needs (only copying over the lines from the backup into the current that match certain criteria – whether the criteria is on the backup or current is up to you).
-
@Maverick-F-16C said in Selecting (phisically, not bookmarking) all the lines contianing a specific parameter or a specific word:
I tried using CTRL+LMB to select specific text lines but Notepad++ doesn’t know such a function
It does, but you must enable it at Settings | Preferences… | Editing by checking Enable Multi-Editing (Ctrl+Mouse click/selection).
However, as @PeterJones notes, that won’t help with what it seems like you’re trying to do. Copying a multiple selection just produces a single copied item with all the text run together, and pasting into a multiple selection pastes the same copied text into each individual selection. That’s the behavior of the Scintilla edit control which Notepad++ uses.
-
Thank you Peter,
Didn’t know the “interleave” term means but now I’ve searched and found out that it only adds lines from file 2 into file 1 while also leaving the original lines in file 1. I want to have those lines in file 1 overwritten, but I want the program to be able to identify that it only overwrites apples to apples (this is what I’m looking for) and not apples to grapes, and especially do that if the “apples” in file 2 are at a different line than “apples” in file 1.
I’ll give an example here of what I would really need to obtain:
File 1: File 2: line 1: A = 10 Line 1: A = 27 line 2: X = 20 Line 2: B = 30 line 3: B = 15 Line 3: C = 6 Line 4: C = 1 Line 4: D = 12 Line 5: D = 7 Line 5: X = 5 Line 6: X = 7 Line 6: E = 10 Line 7: E = 9 Line: 7: F = 25I need to have only the numbers found after the “=” of: A, B, C, D, E (regardless of F which is an additional line and don’t need it) parameters found on different lines from file 2, no matter in which order they may be found in that file copied and pasted to overwrite the numbers found after the “=” of each A, B, C, D, E parameters from file 1.
I want the value “X” of A = “X” from file 2 to replace the value of “X” of A = “X” from file 1 and the “ComparePlus” plugin is quite smart in being able to detect what is similar to what is different and is able to highlight (but only up to a point it seems, cause it also has it’s limits) the similar expressions/sentences (I guess) from each file. But, I tried something else and I still get wrong results. I tried copying the differentiated lines from file 2 into file 1 and found out that it doesn’t overwrite only those specific lines as I needed but also overwrote other lines too by deleting them and creating another mess. I only hope to find a solution of extracting only the wanted data from file 2 and overwrite that specific data in file 1. I have patience to repeat the same step for each wanted parameter, but I want the software to identify the lines containing A, B, C and E from each file and only copy those lines from file 2 and overwrite only those corresponding lines in file 2 and respect the order in which they are found in file 2 (if possible).
Sorry for detailing so much as the thing that I’m looking for could be overall easy, but I wanted to give a detailed example to make sure I’m understood what I’m looking for and to see if is anything out there to make it possible!
Kind regards,
Andrei.-–
moderator edited formatting; please do not indent paragraphs with spaces: it puts it into a text box which makes long paragraphs very difficult to read
moderator added code markdown around text; please don’t forget to use the</>button to mark example text as “code” so that characters don’t get changed by the forum -
Thank you very much as well Coises,
I’ll try to look for that option that you’ve told about and see if I can help myself with that and be at least a step forward in reworking all of the hundreds of thousands of data lines with patience.
Kind regards,
Andrei.--
moderator edited formatting; please do not indent paragraphs with spaces: it puts it into a text box which makes long paragraphs very difficult to read -
@Maverick-F-16C said in Selecting (phisically, not bookmarking) all the lines contianing a specific parameter or a specific word:
I need to have only the numbers found after the “=” of: A, B, C, D, E (regardless of F which is an additional line and don’t need it) parameters found on different lines from file 2, no matter in which order they may be found in that file copied and pasted to overwrite the numbers found after the “=” of each A, B, C, D, E parameters from file 1.
You have requirements that no general-purpose tool (like a text editor like Notepad++) is going to be able to handle – so complicated, in fact, that I still cannot make heads or tails of what you really want, despite your example.
Instead of being handed a solution, you will have to code something that meets your specific needs. I pointed you to the “merge” script in that other discussion because it’s closer to what you want than anything else that Notepad++ can do, and it makes use of a plugin for Notepad++ to do it, and so would make a good starting point for you. But you would have to customize the script to make it follow your rules.
-—
Please note: This Community Forum is not a data transformation or free-code-writing service; you should not expect to be able to always say “I have data like X and want it to look like Y” and have us do all the work for you. If you are new to the Forum, and the problem can be easily solved with a regular expression, we’ll likely give you a start on that. And if it requires scripting (more complex logic than can easily be done in a regular expression), we will let you know. If your problem catches the interest of one of the regulars, that person may even provide an example script that may be helpful; often times, we might even ask you to search the forum for a particular term, because that term will likely help you find a script that already implements something similar. Whether it’s a previously-written script, or whether one of us hacks something up for you specifically, it won’t always exactly match your problem, but it’s at least a starting point for you to work from. At that point, you are expected to take the lead, and make any changes to the example that are necessary to convert it from what was provided to something that meets you exact needs. This forum is focused on Notepad++; while you may want to use Notepad++ for the implementation, text editors aren’t always the right tool for complex text transformation tasks: since you are seeing this boilerplate in my reply, it means that I believe that it’s essentially a generic programming challenge, which is off topic for a Notepad++-specific forum.
-
And, please, if someone for some reason feels compelled to write a non-Notepad++ program to do whatever it is that the OP wants, this forum has a nice private chat function, and you can convey it that way.
-
@Maverick-F-16C said in Selecting (phisically, not bookmarking) all the lines contianing a specific parameter or a specific word:
I’ll give an example here of what I would really need to obtain
Like @PeterJones I am also having difficulty in understanding exactly what you want. My suggestion is to show about 20 lines of both files, make sure they show very good examples of what it is you want. Then show the same 20 lines of file 1 (since it seems you want to update file 1) once your data transformation is completed.
From what I understand at the moment I think it would be possible to create a number of steps using some of Notepad++'s functions, however as Peter said, it may be that nothing actually exists anywhere and it may require custom code to achieve it, or as I think, multiple steps (some of which can be achieved through macro’s).
Question is would you be satisfied with multiple steps within Notepad++, or ideally just want a “miracle” bit of code to do it all at the snap of your fingers.
Terry
-
@Maverick-F-16C said in Selecting (phisically, not bookmarking) all the lines contianing a specific parameter or a specific word:
I need to have only the numbers found after the “=” of: A, B, C, D, E (regardless of F which is an additional line and don’t need it) parameters found on different lines from file 2, no matter in which order they may be found in that file copied and pasted to overwrite the numbers found after the “=” of each A, B, C, D, E parameters from file 1.
I want the value “X” of A = “X” from file 2 to replace the value of “X” of A = “X” from file 1
Depending on the details, there is a way to do this sort of thing in Notepad++. The basic idea is:
-
Make a copy of file 2 (we’ll call it 2a) and remove all the lines except the ones you want to use to update file 1.
-
Insert line numbers at the beginning of file 1; call that file 1a. Insert an equivalent amount of space at the beginning of the lines in file 2a.
-
Copy file 2a to the clipboard and paste it at the end of file 1a. (Make sure there is a line ending in between.)
-
Sort file 1a (which now includes 2a) by the names (A, B, C, D, etc.) that you want to update.
-
Use regular expression find and replace to find sequences of two lines where the first line is a numbered line (from file 1) and the second line is an unnumbered line (from file 2) with the same name, and replace with a single line containing the number from the first line and the data from the second.
-
Sort file 1a by the line numbers to restore its proper order, then remove the line numbers. If any unnumbered lines (lines from file 2 that didn’t match) remain, remove them.
Complexities arise if there can be more than one occurrence of A, B, C, etc. in a file, or if the values don’t appear in consistent places (so that a column-based sort will work to put the A from one file and the A from the other together).
-
-
Thank you very much for your effort to tell me what I must do and for your help. I’ll try that “merge” script that I didn’t yet go for and see if hopefully this would work! What I must do I consider all in all simple, which is to just copy X data from specific lines in file 2 and overwrite that data in the specific lines of file 1 and so far the ComparePlus plugin from Notepad++ is a bit helpful in identifying similar lines and I can check an option called “show only diffs (hide matches)” which brings me ever closer to what I want, but the difficult thing is that ComparePlus won’t help me flawlessly just copy the lines that are generally identical yet have some differences in them (which are usually the numbers I want to copy from file 2 and overwrite in file 1) by just selecting them all from file 1, copying them all, then selecting those from file 2 and overwriting them cause it overwrites them with errors and my only solution is to copy only the lines that are not interleaved from file 2 and overwrite those same ones (not interleaved) in file 1. I’m not necessarily hoping for a miracle code which “at the snap of a finger”=) would identify the similar data from one file and let me overwrite it in a compared file. Again…, I work on a file which is now and then being overwritten by an update and this ruins all of the changes I have done in that file, so I take it step by step to compare this new file with the one that I’ve worked on for about 1 year so far. It’s quite frustrating to try draining a pool with a spoon while it’s not getting filled up from anywhere, just to see that when you’re just about to finish, a 10 million liters are instantly poured back (the update) into it and you feel like eating that spoon…, you want a bigger container to get that water out in fewer steps before the unavoidable repeats. =))
Cheers and regards,
Andrei. -
Recent versions of JsonTools can probably help you if your file happens to be JSON or something very similar to JSON.
Beyond that, I have no more idea how to help you than any of the numerous other people who’ve already posted here.
-
Hello, @maverick-f-16c, @peterjones, @coises, @terry-r, @mark-olson and All,
@maverick-f-16c, I think about a native N++ solution using a regex S/R :
So, let’s suppose you have two files :
File_1.txt
A = 10 CKQ = 20 BYZ = 15 C = 1 D = 7 X = 7 E = 9File_2.txt
A = 00277789 BYZ = 30 C = 6 d = 12 X = 5 E = 10 F = 25-
First, copy the contents of
File_1.txtinFile_3.txt -
Add a new line containing only some
@characters at the very end ofFile_3.txt -
Append the contents of
File_2.txt, inFile_3.txtright after the line of@chars
Thus, the contents of
File_3.txtshould be :A = 10 CKQ = 20 BYZ = 15 C = 1 D = 7 X = 7 E = 9 @@@@@@@@@@@ A = 00277789 BYZ = 30 C = 6 d = 12 X = 5 E = 10 F = 25-
Now, open the Replace dialog (
Ctrl + H) -
Un-tick all box options
-
SEARCH
(?i-s)^(([A-Z]+)[\x20\t].+?)\d+$(?=(?s).+^@+.+^\2[\x20\t].+?(\d+)$)|(?s)^@+.+ -
REPLACE
\1\3 -
Select the
Regular expressionsearch mode -
Click once on the
Replace Allbutton ( or several times on theReplacebutton to understand the logic ! )
After the
Replace Allaction, you should get this text :A = 00277789 CKQ = 20 BYZ = 30 C = 6 D = 12 X = 5 E = 10Is this output OK for you ?
Notes :
-
My regex first searches for any range of letters, whatever its case, followed with a space or a tabulation char and with some digits at the end of curent line
-
Then, it tries to find, AFTER the line of
@@@@@@@, the same list of letters, whatever its case, beginning the line -
In this case, it replaces, in the corresponding line, BEFORE the
@@@@@@@chars, the present digits with the digits found in the last part !
Best Regards,
guy038
-
Thank for your support as well “guy038”!
How would that code that I must write in the “find what” section in the replace menu work for 300k+ lines? Because with this method I would reach a 600k+ lines file and notepad++ already waits a few seconds before opening this one so far. I really thank you for the option you gave me and hopefully it will work, I didn’t try it yet, but right now I want to see how to make the “merge” plugin would do the job!
Many thanks!
Regards! -
Mark-Olson
Thanks for this clue as well. It’s an “.ndf” file and it opens like a text one, so dunno if JSON will also open it but I’ll try when I can.
Regards!
-
Thank you very much as well Coises for this variant. I’ll try to look into this option as well!
Regards!
-
Thank you again PeterJones, but can you please let me know how to make the “merge” plugin work?
Sorry for being so dumb, but iIt asks for the second file, it’s already opened and even though I try to click on each opened file I can’t make it see the second file. Hope to first see what this plugin can do.Regards!
-
Hello, @maverick-f-16c, @peterjones, @coises, @terry-r, @mark-olson and All,
Ah… OK. If your two files have approximately
300Klines, my previous regex S/R won’t probably find nothing as it’s over the usual capacities of theBoostregex engine of Notepad++ !So, I would choose the @coises’s way, using the N++ sort to get the right results. I did not fully read the @coises’s method and I prefer start from scratch !
So, let’s suppose we start with two files :
File_1.txt:
FFF = 79 K = 6 C = 4 A = 8 XXX = 7 H = 51 BB = 6 E = 0 GA = 339 J = 4 DZ = 9 II = 6File_2.txt:
E = 5 J = 0 FFF = 4 ZYX = 1 A = 0 II = 18 DZ = 2 K = 6 C = 17 H = 27Note that the records, in these two files, are randomly sorted, on purpose !
- As in my previous post, create a new
File_3.txtwith the contents ofFile_1.txt, a separation line of some@chars then the contents ofFile_2.txt:
FFF = 79 K = 6 C = 4 A = 8 XXX = 7 H = 51 BB = 6 E = 0 GA = 339 J = 4 DZ = 9 II = 6 @@@@@@@@@@@@@@@ E = 5 J = 0 FFF = 4 ZYX = 1 A = 0 II = 18 DZ = 2 K = 6 C = 17 H = 27Now, execute , successively, the two regex S/R, below :
• SEARCH \x3D • REPLACE ( )\x3DThen :
-
SEARCH
(?-s)^.{40}\K\x20+ -
REPLACE
Leave it EMPTY -
Click only on the
Replace Allbutton
You should get this OUTPUT :
FFF = 79 K = 6 C = 4 A = 8 XXX = 7 H = 51 BB = 6 E = 0 GA = 339 J = 4 DZ = 9 II = 6 @@@@@@@@@@@@@@@ E = 5 J = 0 FFF = 4 ZYX = 1 A = 0 II = 18 DZ = 2 K = 6 C = 17 H = 27-
Then, move the caret on the first line, at column
25 -
Select a
12×0rectangular selection of all the records BEFORE the@@@@@@@@@@@@@@@line -
Type in the
Aletter -
Select the column editor (
Alt + C) -
Select
Number to Insertwith all zones =1, fill in with the0char and click on theOKbutton -
Then move to the first line, at column
25, AFTER the@@@@@@@@@@@@@@@line -
Again do a
10×0**rectangular selection of all the records AFTER the@@@@@@@@@@@@@@@line -
Type in the
Bletter -
Select the column editor (
Alt + C) -
Select
Number to Insertwith all zones =1, fill in with the0char and click on theOKbutton
You should get this OUTPUT :
FFF A01 = 79 K A02 = 6 C A03 = 4 A A04 = 8 XXX A05 = 7 H A06 = 51 BB A07 = 6 E A08 = 0 GA A09 = 339 J A10 = 4 DZ A11 = 9 II A12 = 6 @@@@@@@@@@@@@@@ E B01 = 5 J B02 = 0 FFF B03 = 4 ZYX B04 = 1 A B05 = 0 II B06 = 18 DZ B07 = 2 K B08 = 6 C B09 = 17 H B10 = 27- Now, perform a classical sort, using the
Edit > Line Operations > Sort Lines Lexicographically Ascendingoption
We get :
@@@@@@@@@@@@@@@ A A04 = 8 A B05 = 0 BB A07 = 6 C A03 = 4 C B09 = 17 DZ A11 = 9 DZ B07 = 2 E A08 = 0 E B01 = 5 FFF A01 = 79 FFF B03 = 4 GA A09 = 339 H A06 = 51 H B10 = 27 II A12 = 6 II B06 = 18 J A10 = 4 J B02 = 0 K A02 = 6 K B08 = 6 XXX A05 = 7 ZYX B04 = 1- Delete the
@@@@@@@@@@@@@@@line
Then, run the following regex S/R :
SEARCH
(?-s)^((\w+)\x20+A.+?)\d+(?=\R\2\x20+B.+=\x20+(\d+))REPLACE
\1\3The OUTPUT is now changed as :
A A04 = 0 A B05 = 0 BB A07 = 6 C A03 = 17 C B09 = 17 DZ A11 = 2 DZ B07 = 2 E A08 = 5 E B01 = 5 FFF A01 = 4 FFF B03 = 4 GA A09 = 339 H A06 = 27 H B10 = 27 II A12 = 18 II B06 = 18 J A10 = 0 J B02 = 0 K A02 = 6 K B08 = 6 XXX A05 = 7 ZYX B04 = 1Note : As you can see, due to the previous sort, the search regex just need to find, each time, two consecutive lines of the form :
ABCD A#1 = xxx ABCD B#2 = yyyWhich begin with the same value
ABCDand replace thexxxvalue by theyyyvalue. This explains why this solution should work with huge files, without any problem !-
Now, move again the cursor on the first line, at column
25 -
Perform a
22×0( or22×3) rectangular selection of all the records -
Once more, use the
Edit > Line Operations > Sort Lines Lexicographically Ascendingoption
We get :
FFF A01 = 4 K A02 = 6 C A03 = 17 A A04 = 0 XXX A05 = 7 H A06 = 27 BB A07 = 6 E A08 = 5 GA A09 = 339 J A10 = 0 DZ A11 = 2 II A12 = 18 E B01 = 5 J B02 = 0 FFF B03 = 4 ZYX B04 = 1 A B05 = 0 II B06 = 18 DZ B07 = 2 K B08 = 6 C B09 = 17 H B10 = 27Finally, use this regex S/R, to get, in
File_3.txt, the updated values ofFile_1.txt( fromFile_2.txt)SEARCH
(?-is)\x20+(A)\d+\x20+|^.+\x20B(?s).+REPLACE
?1\x20FFF = 4 K = 6 C = 17 A = 0 XXX = 7 H = 27 BB = 6 E = 5 GA = 339 J = 0 DZ = 2 II = 18Notes :
-
As you can verify, the order of the lines, in
File_3.txt, is identical to the initial order of these lines inFile_1.txt -
The records, present in
File_1.txtand not inFile_2.txt, are not changed -
The records, present in
File_2.txtand not inFile_1.txt, are not added, either
Again, this solution should work in all cases, even with files with million of lines !
Best Regards,
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login