Filter using columns?
-
Good morning. I marked in red in the image the columns that interest me in this document. This is the list of all chess players registered with FIDE, which is freely available to the public at this address (I can’t post the link because human beings love to complicate simple things!.) I would like to know if notepad++ can filter only what interests me using the columns? For example: I would like it to show me only players with standard ratings from 2100 to 2900, the column responsible for ratings is (SRtng) marked in red, this would be my first player filter, then I would like to filter only players titled, the column responsible for this is (Tit) marked in red in the document. fide provides the lists in xml and txt, I downloaded the txt, I downloaded the full version which is over 200mb. I don’t know if xml would be better for what I want to do, I don’t understand any of these things. Trying to filter by arm would be unfeasible, the list has almost a million names. Thank you for your attention. PS: I want to inform you that I don’t work with this, the list will be for my personal use, later I will create a database to study the matches of the players that interest me. I don’t understand anything about regular expressions, so any help, if it’s possible to do what I want, will have to be for someone who is completely new to the subject.
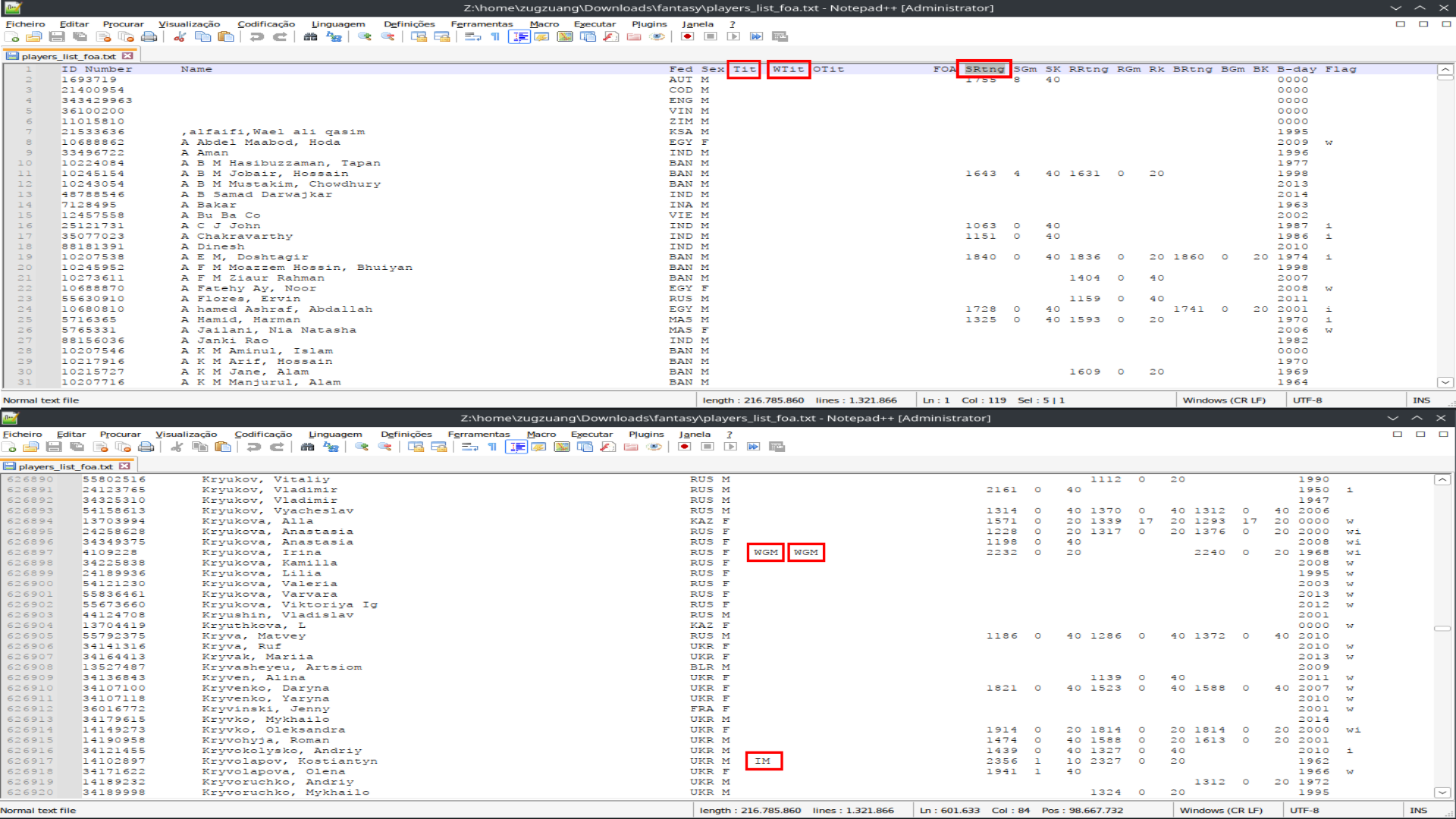
-
@ZNC-Gatilho said in Filter using columns?:
I can’t post the link because human beings love to complicate simple things!
No, you can’t post the link because human beings do DUMB things. The fact that you can’t post a link is a countermeasure to these dumb things.
-
What you’re asking for is a rather ambitious ask for Notepad++ and/or the people here. What you have is a “searching” question, and thus you should read and follow the instructions HERE to give people interested in helping you a better starting point.
-
@ZNC-Gatilho said in Filter using columns?:
This is the list of all chess players registered with FIDE, which is freely available to the public at this address (I can’t post the link because human beings love to complicate simple things!.)
And the “human beings” who complicate things are the spammers who have inflicted non-stop AI/bot-based posts on our small community. Preventing accounts with 0 reputation from posting links has dramatically reduced the amount of spam we have to deal with. The best way to overcome that is to post one well-asked question, with textual data that’s easy to copy/paste, following the FAQ that @Alan-Kilborn linked you to before I finished writing this post: one such good post is usually enough to garner the single upvote necessary.
And since the link is irrelevant to the question (unless someone wanted to download a 200mb file, just to help you), it’s not overly important to the discussion.
However, you could have pasted about about a screen’s worth of text from the textfile – ie, the one screenshot worth of data from your image, but as text that we could copy/paste – using the
</>button found in the create-a-post toolbar, as described in our formatting posts FAQ
… which would have made it much easier for people to help you, without having to download a 200mb file.I would like to know if notepad++ can filter only what interests me using the columns?
Any filter done in Notepad++ would be destructive – ie, removing data from the file. Make sure you have a backup before you try anything suggested in response to your query.
For example: I would like it to show me only players with standard ratings from 2100 to 2900,
Yeah, well, text editors aren’t great at numerical comparisons. That’s not what they’re designed for. The file you have is a text report from some database application, which isn’t the best for filtering after being generated.
What would be best for you (though it wouldn’t involve Notepad++) is for FIDE to give you access to an API for the database itself, rather than just letting you look at reports. Second best (again, not using Notepad++) would be to parse the text file with some tool that would turn it back into a database on your end, and then use the tools with that database to do your extraction to create a new report with the filtered data that you want. Third best would be to import it into a spreadsheet – I know that Excel can take a textfile input, and then prompt you to manually insert the column divisions (and probably LibreOffice’s Calc can as well); once it’s in the spreadsheet, you can use the spreadsheet “filter” tool to do your filtering quite easily.
Destructive search-and-replace in Notepad++ would be fourth in line (at best… there might be other better options between spreadsheet and Notepad++ search-and-replace that I cannot think of)… but it’s the only one that we can help you with here.
I don’t know if xml would be better for what I want to do,
In pure Notepad++, I’m doubtful that it would make it any easier – definitely not if you end up having to use regex, because parsing XML with regex is no easier than parsing fixed-width text table with regex. With the XML Tools plugin or other XML processing plugin, it might be better, if you knew the XPath syntax for searching (assuming XML Tools has an XPath searcher… I don’t honestly remember right now).
I would think that a JSON file might be easier to search/replace than an XML file, but I cannot guarantee that. And one of the JSON plugins (JSON Viewer or JSON Tools) has a builtin filter/searching, which probably would be helpful. So if FIDE has a JSON version of the data, I might suggest that
PS: … I don’t understand anything about regular expressions, so any help, if it’s possible to do what I want, will have to be for someone who is completely new to the subject
If you are unwilling to learn, you are unlikely to find help here. If you are willing to learn, someone might be able to come up with a regex that will help. The way you’ve phrased this PS, I cannot tell if you are willing to learn or not.
In Notepad++ proper, the only way to come close to your goal would be to use regular expressions. Though since one of your filters is mathematical in nature, I will direct you to our Math replacement FAQ for an explanation of why that won’t be simple,
I’m betting that @Coises’s Columns++ plugin will be able to help you – unfortunately, it’s still in beta, so you’ll have to manually install it, since you cannot use Notepad++'s Plugins Admin to install the plugin. But that plugin has its own regex engine which might handle your columnar data better than a vanilla Notepad++ regex; and it has an added feature of mathematical notation (though I’m not sure if that only works in the replacement, or if it can also work for comparing a range of numbers in the search… @Coises will likely be around and will hopefully chime in).
Since I’m not a Columns++ expert, if I were interested in doing this, I’d pull out the PythonScript plugin (if I was forced to do it in Notepad++) or my favorite scripting language (if I were doing it solely for my own use, not for this Forum) and I would write the script in Notepad++, but wouldn’t have to have the 200mb file open in Notepad++, since that’s pretty slow for N++.
-—
Useful References
- Please Read Before Posting
- Template for Search/Replace Questions
- Formatting Forum Posts
- Notepad++ Online User Manual: Searching/Regex
- FAQ: Where to find other regular expressions (regex) documentation
-—
Please note: This Community Forum is not a data transformation service; you should not expect to be able to always say “I have data like X and want it to look like Y” and have us do all the work for you. If you are new to the Forum, and new to regular expressions, we will often give help on the first one or two data-transformation questions, especially if they are well-asked and you show a willingness to learn; and we will point you to the documentation where you can learn how to do the data transformations for yourself in the future. But if you repeatedly ask us to do your work for you, you will find that the patience of usually-helpful Community members wears thin. The best way to learn regular expressions is by experimenting with them yourself, and getting a feel for how they work; having us spoon-feed you the answers without you putting in the effort doesn’t help you in the long term and is uninteresting and annoying for us.
-
I could talk about ways you could use various plugins (including plugins I’ve made) to approach this problem, but IMO Notepad++ is not a good tool for this. Sometimes I’ve tried using NPP plugins to analyze or manipulate really huge tabular datasets like this, and in the end I found it easier to use the most popular and well-known tools.
I personally would use Python and Jupyter Notebooks for this, and if you want any more details it has to be in chat because the details of a non-NPP solution are not pertinent to this forum.
-
I thank Peter and the others who responded. I was going to detail a few more things, but I give up! There’s so much blocking that it’s impossible, congratulations to Akismet. The internet has become a paradise where the good pay for the bad. Since I lack computer knowledge, but I don’t lack money, I will resolve it in other ways.
-
@PeterJones said in Filter using columns?:
Coises will likely be around and will hopefully chime in
Perhaps I’m missing something… but from the screenshots @ZNC-Gatilho included, this isn’t very hard. The text file appears to be in fixed-width columns. No need for any plugin; just make a rectangular selection around the column of interest, sort, and then delete everything except the range of interest. A numeric sort will work on the SRtng column and a lexicographic sort on the others.
Obviously, make a copy of the file first.
-
Hello, @znc-gatilho, @alan-kilborn, @peterjones, @mark-olson, @coises and All,
@znc-gatilho, could you confirm me that your three important zones are, by priority order :
Zone 'SRtng' : Between columns 114 and 118 ( 5 chars ) Zone 'Tit' : Between columns 77 and 79 ( 3 chars ) Zone 'WTit' : Between columns 82 and 85 ( 4 chars )If so, let’s start with this INPUT text, containing the headers line
1and3random records ( lines626897,626912and626917)ID Number Name Fed Sex Tit WTit OTit FOA SRtng SGm SK RRtng RGm Rk BRtng BGM BK B-day Flag 4109228 Kryukova, Irina RUS F WGN WNM 2232 0 20 2240 0 20 1968 wi 36016672 Kryvinski, Jenny FRA F 2001 w 14102897 Kryvolapov, Kostiantyn UJR M IM 2356 1 10 2327 0 20 1962-
Open these four lines text in a new tab
-
Move to the very beginning of your file (
Ctrl + Home) -
Open the Replace dialog (
Ctrl + H) -
Un-tick all box options
-
Type in
(?-s)^.{76}(...)..(....).{28}(.....).+in the Find what : zone -
Type in
\3 \1 \2 $0in the Replace with : zone -
Select the
Regular expressionsearch mode -
Click on the
Replace Allbutton
=> At once, you should get this temporary text :
SRtng Tit WTit ID Number Name Fed Sex Tit WTit OTit FOA SRtng SGm SK RRtng RGm Rk BRtng BGM BK B-day Flag 2232 WGN WNM 4109228 Kryukova, Irina RUS F WGN WNM 2232 0 20 2240 0 20 1968 wi 36016672 Kryvinski, Jenny FRA F 2001 w 2356 IM 14102897 Kryvolapov, Kostiantyn UJR M IM 2356 1 10 2327 0 20 1962-
Now, select the three lines, after the headers line
-
Run the
Edit > Line Operations > Sort Lines Lexicographically Ascendingoption
=> You should get your expected OUTPUT text :
SRtng Tit WTit ID Number Name Fed Sex Tit WTit OTit FOA SRtng SGm SK RRtng RGm Rk BRtng BGM BK B-day Flag 36016672 Kryvinski, Jenny FRA F 2001 w 2232 WGN WNM 4109228 Kryukova, Irina RUS F WGN WNM 2232 0 20 2240 0 20 1968 wi 2356 IM 14102897 Kryvolapov, Kostiantyn UJR M IM 2356 1 10 2327 0 20 1962As you can see your file is, automatically sorted by the three zones
SRtngthen byTitthen byWTitascendingBTW, @Peterjones, I suppose that the
SRtngzone is theELOrating of chess players, which is ALWAYS a4number string for experienced players and grand masters ! . So, no trouble for the sort
Now, just repeat the steps above, with your
players_list_FOA.txtfileOf course, do a backup of your
players_list_FOA.txt, before any actionBeware that your file is really an huge file (
216,785,860bytes for1,321,866lines !! )Thus, I cannot tell you how longer the search/replacement and the save operations will take till completion, when applied to THIS file !
However, you can give it a try !
Of course, in case that the zones do not belong to the mentioned ranges, just tell me the exact values in order to modify the
searchregex, accordingly :-)Best Regards,
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login