Find and Display *All* Duplicate Lines
-
Hi, @yaron, @coises, @mkupper, @alan-kilborn and All,
I thought about an other method but this one would need to add an enhanced regex search mode ! Let me explain : once the search process finds the first occurrence, the search process would consider that the next search should start ONE char AFTER the beginning of the present searched range ( and NOT right AFTER the end of the present searched range ) !
PRESENT INSTALLED search process : SEARCH : •---------------------------#################################------------------#####################################------ ^ FIRST occurrence found | FIRST search start | •---------------------------#################################|-----------------#####################################------ ^ SECOND occurrence found SECOND search start POSSIBLE ADDED search process : SEARCH : •---------------------------#################################------------------#####################################------ ^ | FIRST occurrence found FIRST search start | •----------------------------|----------------------#####################------------------------------------------------- ^ SECOND occurrence found SECOND search start
Let’s experiment this new feature :
-
Open the
Dup.txtfile -
Use, first, the
Search > Bookmark > Clear All Bookmarksoption -
Open the Find dialog
-
SEARCH
(?-is)^\tLine \d+: (.+)\R(?s:.*?)^\tLine \d+: \1(?:\R|\z)
IMPORTANT : This search regex is different from the ones above !
- Click on the
Find Nextbutton
=> The first occurrence found is a stream multi-lines selection, from line
3to line22-
Close the
Finddialog (ESC) -
Manually bookmark the first and last line of that first selection, if not already the case
-
Now, using this new enhanced regex mode, the next search would start ONE character ONLY AFTER the present search
-
To simulate this unsupported feature, simply move the caret one more char ( so right between the
TABchar and theLine 3:string -
Hit the
F3key
=> The second occurrence found is a stream multi-lines selection, from line
4to line42-
Again, manually bookmark the first and last line of this second selection, if not already the case
-
Again, move the caret just one char after the beginning of line, so right between the
TABchar and theLine 4:string -
Hit the
F3key
=> The third occurrence found is a stream multi-lines selection, from line
10to line29-
Again, manually bookmark the first and last line of this third selection, if not already the case
-
Again, move the caret just one char after the beginning of line, so right between the
TABchar and theLine 10:string -
Hit the
F3key
=> The fourth occurrence found is a stream multi-lines selection, from line
15to line46-
Again, manually bookmark the first and last line of this fourth selection, if not already the case
-
Again, move the caret just one char after the beginning of line, so right between the
TABchar and theLine 15:string -
Hit the
F3key
=> The fifth occurrence found is a stream multi-lines selection, from line
22to line33-
Again, manually bookmark the first and last line of this fifth selection, if not already the case
-
Again, move the caret just one char after the beginning of line, so right between the
TABchar and theLine 22:string -
Hit the
F3key
=> The sixth occurrence found is a stream multi-lines selection, from line
26to line36-
Again, manually bookmark the first and last line of this sixth selection, if not already the case
-
Again, move the caret just one char after the beginning of line, so right between the
TABchar and theLine 26:string -
Hit the
F3key
=> The seventh occurrence found is a stream multi-lines selection, from line
29to line40-
Again, let’s bookmark the first and last line of this seventh selection, if not already the case
-
Again, move the caret just one char after the beginning of line, so right between the
TABchar and theLine 29:string -
Hit the
F3key
=> This time, no more occurrence is found
-
We would get a file containing
10bookmarked lines -
Finally, with the
Search > Bookmark > Copy Bookmarked Linesoption and a paste action in a new tab, we xould end up with :
Line 3: Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue. Line 4: Improve URL parser: fix apostrophe in an URL issue. Line 10: Fix find in files failure issue due to directory path with leading/trailing spaces. Line 15: Fix dockable panels display issue in RTL direction. Line 22: Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue. Line 26: Prevent corruption possibility when using -p command line parameter in a UTF file. Line 29: Fix find in files failure issue due to directory path with leading/trailing spaces. Line 33: Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue. Line 36: Prevent corruption possibility when using -p command line parameter in a UTF file. Line 40: Fix find in files failure issue due to directory path with leading/trailing spaces. Line 42: Improve URL parser: fix apostrophe in an URL issue. Line 46: Fix dockable panels display issue in RTL direction.
BTW, the @alan-kilborn solution, using the
ComparePlusplugin, seems interesting. After following his instructions, with my own set of data, I got this screen :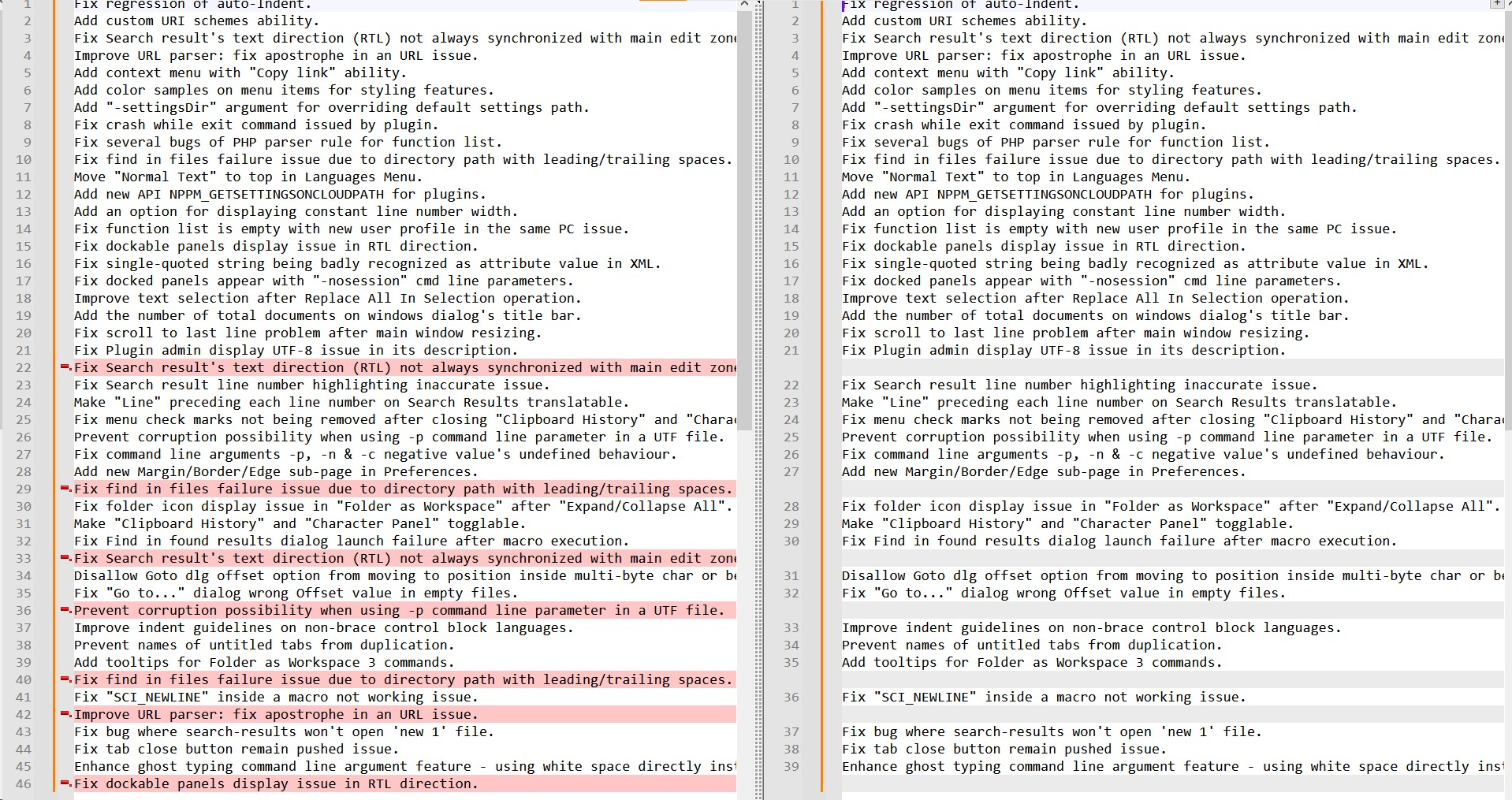
And, unfortunately, it does not tell us anything about the
5lines3,4,10,15and26, of the original file, which have duplicates !
In summary, a script could probably find all lines with their duplicate ones, of current file but it would not use the search results` panel at all !
However, if we consider the current file in the main view and the list of the duplicate lines, found by the script, like the above one, in the secondary view, I suppose that an automatic jump to a specific duplicate line could still be possible !
A lot of work, anyway, beyond my own skills !!
Best Regards
guy038
-
-
@Alan-Kilborn said in Find and Display *All* Duplicate Lines:
An alternative almost-solution to the original need of
How can I find duplicate lines and display all occurrences of those lines?
could be to:
- save the file (
FILE1) - use the Remove Duplicate Lines command
- do File > Save a Copy As… to obtain
FILE2 - undo the Remove Duplicate Lines command
- use a file-compare utility/plugin on
FILE1andFILE2, which will create an effective “display” of the duplicated lines
That would fail to show the first of each set of duplicate lines.
- save the file (
-
@Yaron said in Find and Display *All* Duplicate Lines:
That is: if I have 2 identical lines, I’d like the 2 occurrences to be displayed in the Search Results window.
Something to note is that after you do a Find All, as soon as you add or remove characters, everything in the search results window following the point of the modification no longer addresses the correct position. So though you might be able to see all the duplicates if this function existed, you still wouldn’t be able to easily do things like browse through and decide which ones from of a set of duplicates should be removed, or add a suffix to an identifier in some duplicates that should not be removed, without things becoming confusing very rapidly.
-
@Alan-Kilborn said in Find and Display *All* Duplicate Lines:
If a line differs from another line only in its line-ending character(s), is it still a duplicate line? If not, can the final line, when it doesn’t have a line-ending, ever be a duplicate of another line?
The current
Remove Duplicate Linesmenu option also looks at the line ending character(s).I constructed a test using:
a<crlf> b<crlf> c<crlf> <crlf> a<cr> b<cr> c<cr> <cr> a<lf> b<lf> c<lf> <lf>Nothing was removed from that set of lines. I also removed the two final
<lf>, tried Remove Duplicate Lines, and nothing was removed.I was thinking that a “Show Duplicate Lines” tool would use a regexp pattern of
(?-si)^.+as I suspect most people are not interested in duplicate empty lines and likely don’t care about the line ending.The existing Remove Duplicate Lines seems to use
(?-si)^.*\Rmeaning it’s a case-sensitive compare that also looks at the line ending.I thought about making the pattern user configurable but that could lead to confusion about if the tool would inspect just the matched patterns for duplicates or the entire lines containing those patterns.
-
Something to note is that after you do a Find All, as soon as you add or remove characters, everything in the search results window following the point of the modification no longer addresses the correct position.
The long-ago discussed workaround is to start at the bottom of the Search results list, and work your way towards the top.
An alternative almost-solution
That would fail to show the first of each set of duplicate lines.
And, unfortunately, it does not tell us anything about the 5 lines 3, 4, 10, 15 and 26, of the original file, which have duplicates !
Which is why I dubbed it (file compare) an almost solution.
The current Remove Duplicate Lines menu option also looks at the line ending character(s)
Well, since we’re in “fantasy land”, scoping out a proposed new feature, we can take some liberty and define its best way of working.
-
For the truly stubborn (and I duck my head when I say that), there is a solution of sorts:
Throughout, beware of the match case setting, if it matters for your purpose. Also, the following will not work if your text contains the sequence \E anywhere. Edit: @Alan-Kilborn has pointed out a character count limitation which will also cause failure.
First, open Search | Mark…; enter:
Find what :^([^\r\n]++)(?=[\s\S]*?^\1$)
and then click Mark All, Copy Marked Text and Clear all marks. Close the dialog.Open a new tab and paste, then use Edit | Line Operations | Remove Duplicate Lines.
Type
^(\Qat the beginning of the first line. Go to the end of the document, backspace to delete the empty line, and type\E)$at the end of the last, non-empty line. Do not type Enter after this sequence.Open Search | Replace…; enter:
Find what :\R
Replace with:\\E\|\\Q
and click Replace All.Close the dialog, then Select All and Copy.
Return to the original document and open Search | Find…. Paste into the Find what box and click Find All in Current Document.
-
@Coises said in Find and Display *All* Duplicate Lines:
Paste into the Find what box
I haven’t tried the duck-my-head solution :-) but at the paste step I quoted I’d also add “hope that what you’re pasting is 2046 characters or less”.
-
Hi @guy038 and all,
Thank you for the creative suggestions. I appreciate it.
With ComparePlus:
Save the file (if not already saved).
Remove Duplicate Lines.
ComparePlus -> Diff since last Save. -
Hi, @yaron, @coises, @mkupper, @alan-kilborn and All,
First of all, a regex point that I’d never thought of before ! Even, if no character class, contaiing letters, exists in your entire search regex, the use of the
-iorimodifier does modify its behaviour about a case match !For example, using the simple INPUT text, in a new tab :
Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue. Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue.The regex
(?-is)^(.+)(?=\R(?s).*?^\1$)does match the first lineBut with that INPUT text, where I changed the case of the part between parentheses of the second line :
Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue. Fix Search result's text direction (rtl) not always synchronized with main edit zone's one issue.The regex would not match anything, despite the fact that no letter seems fully involved in this search regex !
So, @coises, you may add the leading modifier
(?-i)or(?i)in front of your regex^([^\r\n]++)(?=[\s\S]*?^\1$):-)
@coises, I’m rather stubborn too and I I’ve found out an almost easy way to get the same results as you
So, if I take back my previous INPUT text, containing some duplicate lines
Fix regression of auto-Indent. Add custom URI schemes ability. Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue. Improve URL parser: fix apostrophe in an URL issue. Add context menu with "Copy link" ability. Add color samples on menu items for styling features. Add "-settingsDir" argument for overriding default settings path. Fix crash while exit command issued by plugin. Fix several bugs of PHP parser rule for function list. Fix find in files failure issue due to directory path with leading/trailing spaces. Move "Normal Text" to top in Languages Menu. Add new API NPPM_GETSETTINGSONCLOUDPATH for plugins. Add an option for displaying constant line number width. Fix function list is empty with new user profile in the same PC issue. Fix dockable panels display issue in RTL direction. Fix single-quoted string being badly recognized as attribute value in XML. Fix docked panels appear with "-nosession" cmd line parameters. Improve text selection after Replace All In Selection operation. Add the number of total documents on windows dialog's title bar. Fix scroll to last line problem after main window resizing. Fix Plugin admin display UTF-8 issue in its description. Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue. Fix Search result line number highlighting inaccurate issue. Make "Line" preceding each line number on Search Results translatable. Fix menu check marks not being removed after closing "Clipboard History" and "Character Panel" panels. Prevent corruption possibility when using -p command line parameter in a UTF file. Fix command line arguments -p, -n & -c negative value's undefined behaviour. Add new Margin/Border/Edge sub-page in Preferences. Fix find in files failure issue due to directory path with leading/trailing spaces. Fix folder icon display issue in "Folder as Workspace" after "Expand/Collapse All". Make "Clipboard History" and "Character Panel" togglable. Fix Find in found results dialog launch failure after macro execution. Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue. Disallow Goto dlg offset option from moving to position inside multi-byte char or between CR and LF. Fix "Go to..." dialog wrong Offset value in empty files. Prevent corruption possibility when using -p command line parameter in a UTF file. Improve indent guidelines on non-brace control block languages. Prevent names of untitled tabs from duplication. Add tooltips for Folder as Workspace 3 commands. Fix find in files failure issue due to directory path with leading/trailing spaces. Fix "SCI_NEWLINE" inside a macro not working issue. Improve URL parser: fix apostrophe in an URL issue. Fix bug where search-results won't open 'new 1' file. Fix tab close button remain pushed issue. Enhance ghost typing command line argument feature - using white space directly instead of %20. Fix dockable panels display issue in RTL direction.I used the following regex S/R, which adds a
¤character at the end of any line which have duplicate(s) in current fileOf course, you may use any other char, which is totally absent in your present file
So :
-
Move the caret at the very beginning of current file
-
Open the Replace dialog (
Ctrl + H) -
Untick all box options
-SEARCH
(?-is)^(.+)¤?\R((?:.*\R)*?)\1(?<!¤)(?=\R|\z)-REPLACE
\1¤\r\n\2\1¤-
Tick the
Wrap aroundoption -
Select the
Regular expressionsearch mode -
Click on the
Replace Allbutton, repeatedly, till you get the messageReplace All: 0 occurrences were replaced from carat to end-of-file -
As you can see, this regex is run repeatedly, till there is no duplicate line, anymore and, each time, there is :
-
A search for a complete block of lines between two identical lines
-
A replacement of all the contained block, with a
¤character added at the very end of the two identical lines which surround that block
-
-
Now, just switch to the find dialog
-
Move back the caret at the very beginning of current file, if necessary
-
SEARCH
¤$ -
Click on the
Find All in Current Documentbutton
=> You should get this expected text in the
Search resultspanel :Search "¤$" (12 hits in 1 files of 1 searched) D:\@@\792\Test_AP.txt (12 hits) Line 3: Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue.¤ Line 4: Improve URL parser: fix apostrophe in an URL issue.¤ Line 10: Fix find in files failure issue due to directory path with leading/trailing spaces.¤ Line 15: Fix dockable panels display issue in RTL direction.¤ Line 22: Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue.¤ Line 26: Prevent corruption possibility when using -p command line parameter in a UTF file.¤ Line 29: Fix find in files failure issue due to directory path with leading/trailing spaces.¤ Line 33: Fix Search result's text direction (RTL) not always synchronized with main edit zone's one issue.¤ Line 36: Prevent corruption possibility when using -p command line parameter in a UTF file.¤ Line 40: Fix find in files failure issue due to directory path with leading/trailing spaces.¤ Line 42: Improve URL parser: fix apostrophe in an URL issue.¤ Line 46: Fix dockable panels display issue in RTL direction.¤Voila !
REMARKS :
-
The number of lines and characters of each block, between two identitcal lines, does matter !
-
For a text containing only
1 char/linethe regex can handle a block of26,500lines, about -
For a text containing only
70 char/linethe regex can handle a block of3,000lines, about -
For a text containing only
140 char/linethe regex can handle a block of2,800lines, about
-
-
If you exceed these values, you’ll probably get a catastropkic breakdown event which invalids the whole method
So, one advice :
- Fisrt, get successive matches of the regex instead of doing the different replacements and :
If, at some step of the search, the number of selected lines is equal to number
Ln - 1, in the status bar, then something went wrong and you cannot rely on this method, given your INPUT file ;-((If, for all steps, the number of selected lines is inferior to number
Ln - 1, in the status bar, then you can be confident regarding this method !Best Regards
guy038
-
-
@guy038 When you use a
\1backreference in a search expression then the state of the ignore-case flag matters if the capture group contains letters. I take advantage of this all the time.For example,
(?-i)(...)\1only matches on line 1:1 abcabc 2 abcaBc -
Even though OP had no interest in a PythonScript solution, perhaps others will, so here I present my solution which I call
FindAndDisplayAllDuplicateLines.py:# -*- coding: utf-8 -*- from __future__ import print_function ######################################### # # FindAndDisplayAllDuplicateLines (FADADL) # ######################################### # references: # https://community.notepad-plus-plus.org/topic/25145/find-and-display-all-duplicate-lines # for newbie info on PythonScripts, see https://community.notepad-plus-plus.org/topic/23039/faq-desk-how-to-install-and-run-a-script-in-pythonscript #------------------------------------------------------------------------------- from Npp import * import os import re from collections import OrderedDict #------------------------------------------------------------------------------- class FADADL(object): def __init__(self): editor.callback(self.doubleclick_callback, [SCINTILLANOTIFICATION.DOUBLECLICK]) def run(self): source_pathname = notepad.getCurrentFilename() line_list_by_contents_odict = OrderedDict() # create data structure of unique line content and list of line numbers that same content appears on def fel_func(contents, line_number, total_lines): contents = contents.rstrip('\n\r') if len(contents) > 0: # avoid recording empty lines (rarely want those considered as duplicates) if contents in line_list_by_contents_odict: line_list_by_contents_odict[contents].append(line_number) else: line_list_by_contents_odict[contents] = [ line_number ] editor.forEachLine(fel_func) # generate output text and hold in memory for now num_sets_of_duplicates = 0 output_line_list = [] for line_contents in line_list_by_contents_odict: if len(line_list_by_contents_odict[line_contents]) > 1: num_sets_of_duplicates += 1 output_line_list.append(' Set-{i} text: {c}'.format(c=line_contents.lstrip(), i=num_sets_of_duplicates)) for line_number in line_list_by_contents_odict[line_contents]: user_line_number = line_number + 1 output_line_list.append('\tLine {n}'.format(n=user_line_number)) # create and open a results file (extension .sr means "search results") output_file_path = os.path.expandvars(r'%TEMP%\DupeLineResults.sr') if not os.path.exists(output_file_path): open(output_file_path, 'w').close() # so notepad.open() won't prompt or fail on non-existent file notepad.open(output_file_path) eol = ['\r\n', '\r', '\n'][editor.getEOLMode()] editor.setText('Search DUPLICATE LINES ({n} set{s}) in "{p}"'.format( n=num_sets_of_duplicates, p=source_pathname, s='s' if num_sets_of_duplicates != 1 else '' ) + eol) editor.appendText(eol.join(output_line_list) + eol) notepad.save() def doubleclick_callback(self, args): # when user double-clicks a "Line xxx" line, jump to that line in the source file, # just like Notepad++'s Search-results panel works first_line_content = editor.getLine(0) m = re.match(r'Search DUPLICATE LINES \(\d+ sets?\) in "(?P<src_path>.+)"', first_line_content) if m: source_pathname = m.group('src_path') double_clicked_line_number = args['line'] double_clicked_line_content = editor.getLine(double_clicked_line_number) m = re.match(r'\tLine (?P<src_user_line>\d+)', double_clicked_line_content) line_in_source_file = int(m.group('src_user_line')) - 1 if m: for (pathname, buffer_id, index, view) in notepad.getFiles(): if pathname == source_pathname: notepad.activateIndex(view, index) editor.gotoLine(line_in_source_file) break #------------------------------------------------------------------------------- if __name__ == '__main__': try: fadadl except NameError: fadadl = FADADL() fadadl.run()Let’s demo the script:
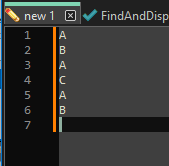
Take some text and put it in a new tab (that you can hard-name save, or not):
A B A C A Bto get:
With the tab active, run the script; a new tab will be created, with content:
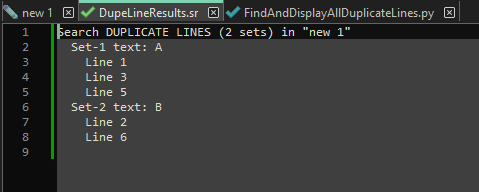
If you double-click a
Line _line in the output file, you’ll be taken to the original input file at the indicated line number (much like how Notepad++'s Search results panel double-click works).--
Moderator EDIT (2024-Jan-14): The author of the script has found a fairly serious bug with the code published here for those that use Mac-style or Linux-style line-endings in their files. The logic for Mac and Linux was reversed, and thus if the script was used on one type of file, the line-endings for the opposite type of file could end up in the file after the script is run. This is insidious, because unless one works with visible line-endings turned on, this is likely not noticed. Some detail on the problem is HERE. The script above has been corrected per that instruction. -
 A Alan Kilborn referenced this topic on
A Alan Kilborn referenced this topic on
-
Thank you for the beautiful script.
I don’t get Email notifications on new replies to threads I’m watching.
Any idea?Thank you.

- Logged in via GitHub.
-
@Alan-Kilborn The script is pretty cool.
I saw in the code that you support double-clicking and so played with that. One puzzle is that it intermittently creates random selections when I double click. For example, for one match I see:
Line 19360 Line 19364I double click on
Line 19360and am taken to that line in my text file. I do Ctrl+PageDown to flip to theDupeLineResults.srfile/tab and double click onLine 19364expecting to be dropped down four lines. Instead the page starts with line 19360 and there is a selection running down to the middle of line 19398. Using the mouse and scroll bar I see that the selection starts started in the middle of line 991.At first I thought the cause was this particular file has a number of non-printable characters, extended Unicode characters, and illegal byte sequences. I created a copy of this file that is restricted to plain ASCII and tested again. The line numbers I noted above are from a plain ASCII file though it’s still classified as UTF-8 in the status line. A regexp search for
[ -~\t\r\n]+gets one hit which runs from the first line to the end which verifies it’s plain ASCII.The random selections are intermittent. Sometimes they happen, and sometimes not.
This is on Notepad++ v8.6 (32-bit)
Build time : Nov 18 2023 - 00:41:46
Path : C:\Program Files (x86)\Notepad++\notepad++.exe
Command Line : “c:\tmp\tmp”
Admin mode : OFF
Local Conf mode : OFF
Cloud Config : OFF
OS Name : Windows 11 Home (64-bit)
OS Version : 22H2
OS Build : 22621.2715
Current ANSI codepage : 1252
Plugins :
DSpellCheck (1.5)
mimeTools (2.9)
NppConverter (4.5)
NppExport (0.4)
NppTextFX (0.2.6)
PythonScript (2) -
@Yaron said in Find and Display *All* Duplicate Lines:
I don’t get Email notifications on new replies to threads I’m watching.
Any idea?The email server stopped letting the forum connect and send messages some time ago. I haven’t felt that email notifications are worth pestering Don over
-
It’s a basic functionality IMO. :)
Thank you. -
@Yaron said in Find and Display *All* Duplicate Lines:
It’s a basic functionality IMO. :)
Mail servers have harsh anti-spam for sending, and forum outgoing emails looks like spam to most servers. Without paying for an outgoing mail server that allows emails from forums, the chances are low that anything that we can do will counteract that. And Don isn’t going to pay for such a server.
And as I pointed out in the FAQ back in the days when it didn’t work at all: the regulars (some, like you and I, who have been here for 8+ years, during which this feature worked for fewer than 8 months, so less than 1/12 of the time we’ve been involved in the forum), have survived the vast majority if the forum’s existence (in this format) without the email notifications – it’s nice to have, but IMO not a critical feature.
I will contact him, but there is no guarantee we can get it to work, or that he’s interested in spending any more time on that feature of the forum.
-
@mkupper said in Find and Display *All* Duplicate Lines:
One puzzle is that it intermittently creates random selections when I double click
Hmm, I have not been able to duplicate this. I set up a test file of 25000 lines of random sentences (one per line), then I duplicated 10 of these lines, then random-sorted the file. Then I ran the script and tried to recreate what you are seeing from double-clicking in the results file, and could not. :-(
-
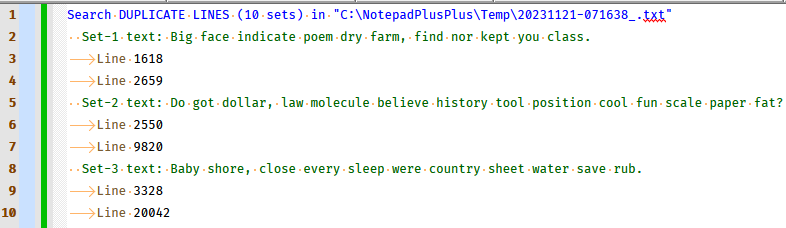
Side note:
Someone asked me via chat why the output file has a
.srextension. Thesrstands for “search results”; I tried to emulate Notepad++'s Search results format in the output I created.Another reason is that I have a UDL that I made for .sr files which colorizes the output somewhat like N++'s Search results, sample of that:
-
Hello, @yaron, @coises, @mkupper, @alan-kilborn and All,
@alan-kilborn, just a minor bug ( or a possible decision on your part ! ) :
Let’s write this text in a new tab :
This is a test This is a test This is a second test This is a second test This is a third test This is a third test This is a third test This is a fouth test This is a fouth test This is a fouth test This is a fouth test This is the last test This is the last test This is the last test This is the last test This is the last testThen, running your valuable script, we get this
DupeLineResults.sr:Search DUPLICATE LINES (5 sets) in "new 1" Set-1 text: This is a test Line 1 Line 2 Set-2 text: This is a second test Line 4 Line 5 Set-3 text: This is a third test Line 7 Line 8 Line 9 Set-4 text: This is a fourth test Line 11 Line 12 Line 13 Line 14 Set-5 text: This is the last test Line 16 Line 17 Line 18 Line 19 Line 20I personally was expecting :
Search DUPLICATE LINES (5 sets) in "new 1" Set-1 text: This is a test Line 1 Line 2 Set-2 text: This is a second test Line 4 Line 5 Set-3 text: This is a third test Line 7 Line 8 Line 9 Set-4 text: This is a fourth test Line 11 Line 12 Line 13 Line 14 Set-5 text: This is the last test Line 16 Line 17 Line 18 Line 19 Line 20Where the text, located after the regex string
Set-\d+ text:\x20, should be identical to the text in current file
@mkupper, I think that :
-
When you click on a line of the
DupeLineResults.srfile in order to jump to curent file, it’s best to cancel any previous selection before doing the double-clic ! -
Do NOT click on any line
Set-### text: ......... Else, you get errors on thePython Console!
Best Regards,
guy038
-
-
@guy038 said in Find and Display *All* Duplicate Lines:
Do NOT click on any line Set-### text: … Else, you get errors on the Python Console !
Yea. Bug. The
line_in_source_file =line should be placed after the followingif m:line.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login