How to remove ALL the duplicates WITHOUT deleting the empty lines?
-
I’ve tried several formulas to remove duplicates and they either change the total number of lines in the file or don’t remove all the duplicates.
Does anyone know a formula that removes ALL the duplicates WITHOUT deleting the empty lines?
THANK YOU.
-
@Marcos-Miguel
Can you provide an example of what your file structure looks like and how it should look at the end? This will make it easier to understand. -
I’d guess that OP wants to not remove duplicate lines, but rather erase their contents, e.g. make them have nothing but a line-ending on them?
But really, yea, OP needs to provide more detail on the needed task.
-
let’s say I have the following sequence
1
1
1
2
2
3If I run the following formula to remove the duplicates
(.+)$\R+\K\1
then this is what I get
1
1
23
1What I need is a formula that keeps just the first number 1 and delete all others.
-
This post is deleted! -
PLEASE just try to ask a decent question.
Supposing your BEORE data is:
1 1 1 2 2 3and your AFTER data that you want looks like this:
1 2 3???
-
@Alan-Kilborn Yes and thank you for your kind words. Very polite of you.
-
@Marcos-Miguel said in How to remove ALL the duplicates WITHOUT deleting the empty lines?:
Very polite of you.
I was polite in my first response.
I probably should have redirected you to the FAQ section (which you should have read anyway before posting on any site new to you) where there is detailed instructions on how to ask such a question as yours.And someone else was polite to you, but you ignored their request (“Can you provide an example of what your file structure looks like and how it should look at the end?”)
-
@Marcos-Miguel said in How to remove ALL the duplicates WITHOUT deleting the empty lines?:
What I need is a formula that keeps just the first number 1 and delete all others.
Hi Miguel, i don’t have a regex solution which works this flexibel to delete all the following duplicates. But maybe other Regex experts can.
But if you have the possibility to install Plugins you can simply do it with MultiReplace Plugin
-
Activate Checkbox “
Use Variables” -
Add into the list ->
Find what:
1
Replace with:cond(CNT > 1, '')Find what:
2
Replace with:cond(CNT > 1, '')Find what:
3
Replace with:cond(CNT > 1, '')- start
Replace Allwith activated "Use List"Checkbox
PS: The next MultiReplace version 2.2.0.9 is in development, which will offer more flexibility in “Use Variables”, even for automatic duplicate detection. This solution can then be described within a single-line expression, apart from the expected duplicate values.
-
-
Hello, @marcos-miguel, @thomas-knoefel, @alan-kilborn, @coises and All,
Let’s use a real example ! So, we start with this INPUT text, containing a list of English/American first-names :
Ted Mary Alice John Mary Alice Peter Alice John Andrew Ted Mary John Ted Elisabeth Andrew Peter Peter SusanAnd, @marcos-miguel, you would like this expected OUTPUT text, wouldn’t you ?
Ted Mary Alice John Peter Andrew Elisabeth Susan
If so, here are the steps for a regex solution, which does NOT even need any plugin and does NOT need previous sorted data, too !
-
Open your file within N++
-
Open the Replace dialog (
Ctrl + H) -
First, untick all box options
-
SEARCH
(?-is)^((.+)\R(?s:.+?))^\2 -
REPLACE
\1 -
Check the
Wrap aroundoption ( IMPORTANT ) -
Select the
Regular expressionsearch mode -
Click, repeatedly, on the
Replace Allbutton OR on theReplacebutton, until you get :
The message
Replace: no occurrence was foundOR the messageReplace All: 0 occurrences were replaced in entire file
A second and equivalent solution would be :
-
Open your file within N++
-
Open the Replace dialog (
Ctrl + H) -
First, untick all box options
-
SEARCH
(?-is)^(.+)\R(?s:.+?)\K^\1 -
REPLACE
Leave EMPTY -
Check the
Wrap aroundoption ( IMPORTANT ) -
Select the
Regular expressionsearch mode -
Click repeatedly on the
Replace Allbutton ( Do NOT use theReplacebutton ), until you get the messageReplace All: 0 occurrences were replaced in entire file
Notes :
-
If you use the first solution, on a file containing a huge number of lines and where two duplicate lines are possibly separated by a great amount of other lines, the search regex may not work properly. In this case, I advice you to prefer the last solution which should work nicely in most of the cases !
-
When using the second solution, remember to NEVER use the
Replacebutton but ONLY theReplace Allone, because of the\Ksyntax in the search regex !
Best Regards
guy038
-
-
@guy038 proposed a very simple solution to this, but I have a multi-step solution using no plugins, without having to perform the same find-replace multiple times in a row:
Make sure
Regular expressionsare ON in the find/replace form before starting this.The document starts looking like this:
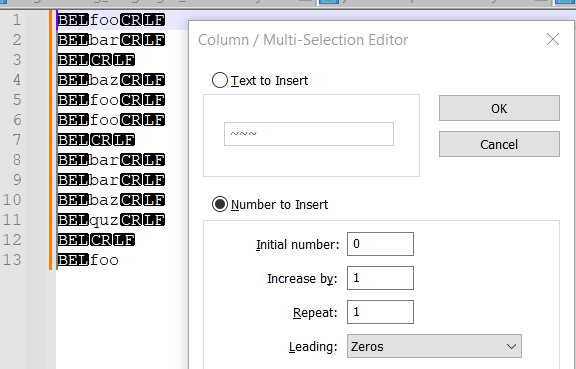
foo bar baz foo foo bar bar baz quz foo- Use the find/replace form to replace
^with\x07. This adds aBELcharacter (convenient because it does not show up naturally in most text documents) to the beginning of each line. - Make a column selection in the first column of every line of the file, then use the column editor to insert a number (with leading zeros to facilitate sorting). This numbers the rows, so they can later be put back in order.
- Use the find/replace form to replace
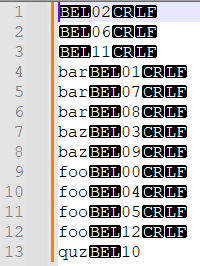
(?-s)^(\d+)(\x07)(.*)with${3}${2}${1}. This puts the column numbers after everything else. - Use the menu command
Edit->Line Operations->Sort Lines Lex. Ascending Ignoring Case. Now all the lines with the same text are grouped together, and a single regex-replace can get rid of all but the first line with given text.
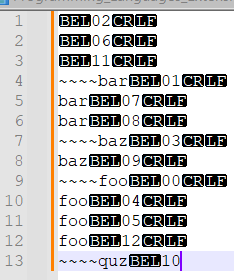
- Find/replace
(?-s)^(.+)\x07\d+(?:\R\1\x07\d+)*with~~~~${0}. This marks the first instance of each line, so that it won’t be deleted later. Note that the~~~~in this example should be replaced with some other text that occurs nowhere in your document.
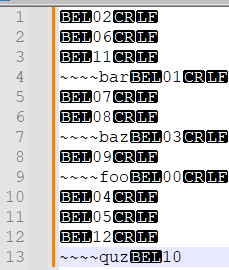
- Find/replace
(?-s)^(?!~~~~).*(\x07\d+)with${1}. This clears the text but not the line number of any line that does not have the first instance of its text.
- Find/replace
^~~~~with nothing. This removes the starting marker. - Find/replace
(?-s)^(.*)(\x07)(\d+)$with${3}${2}$1. This brings the line numbers back to the front so that the lines can go back in order. - Use the menu command
Edit->Line Operations->Sort Lines Lex. Ascending Ignoring Case. Now all the lines are back in their original order.
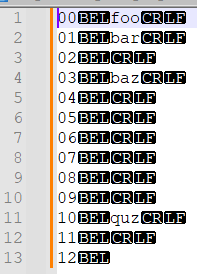
- Find/replace
^\d+\x07with nothing. This removes the line numbers and separator.
Finally, you are left with the original document with the non-first instances of each line’s text replaced with nothing! A lot of steps, but every step is highly scalable and won’t exhibit bad performance on very large files.
foo bar baz quz - Use the find/replace form to replace