Need help with adding </i> to the end of multiple different strings.
-
@PeterJones
Your regex is very complex an I am NO way near understanding, that’s why I come here for help. I’m still a noob with regex.
Your regex got the majority which I’m super thankful for.
It only missed ONE:466 00:44:40,050 --> 00:44:43,928 - <i>How's his pulse?</i> - RUDENKO: It's high. Not to worry too much.I can work with that. Thank you so much for this, much appreciated.
FYI: I’m 70 years old an have a hard time wrapping my head around those complex regex command strings.
Cheers, Hank -
This post is deleted! -
@Hank-K said in Need help with adding </i> to the end of multiple different strings.:
It only missed ONE:
…
Oops, it missed this one too:It didn’t miss either of those for me:
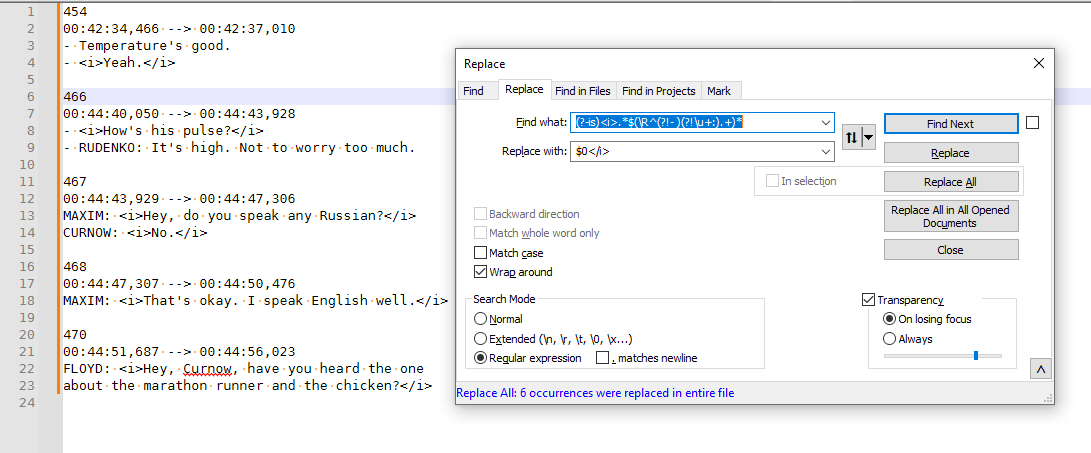
Did you have your cursor later in the file and not have Wrap Around checkmarked?
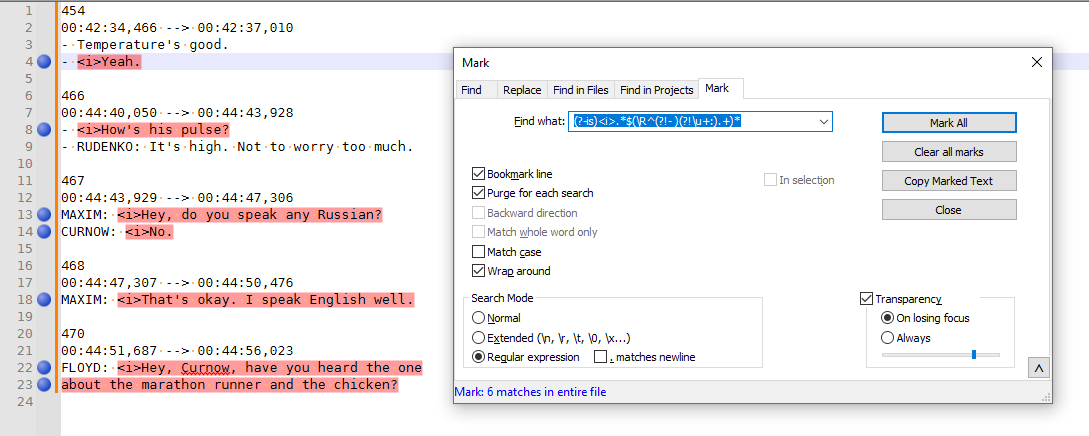
addendum: here’s a “before” picture using the Mark tab in the dialog box, to show what it’s going to replace
I am NO way near understanding
The only way to learn is to study and practice what you’ve been given. The same is true at 7 or 70
-
@PeterJones said in Need help with adding </i> to the end of multiple different strings.:
…
You are TOTALLY correct … my BAD, old age sorry.
This is so AMAZING… thank you so MUCH Peter. -
@PeterJones
I forgot to mention one issue, which is some of the line strings could already have the </i>.
In those cases I get double</i></i>.
But easy fix afterwards.
Thanks again. -
@Hank-K said in Need help with adding </i> to the end of multiple different strings.:
But easy fix afterwards.
Adding in the restriction to not already have the </i> would make it much more complicated regex. I think it’s best to just run the one above, then remove any duplicate
</i></i> -
You might find it easier to use Subtitle Edit.
One of the options under Tools | Fix common errors… is Fix invalid italic tags.
-
Hello, @hank-k, @peterjones and All,
@peterjones, I think that we can shorten your regex to :
SEARCH
(?-is)<i>.*(\R(?!- |\u+:).+)?REPLACE
$0</i>-
Indeed, the
$before\Rand the^after\Rare useless -
The two conditions can be combined in a single look-ahead
Note that, in your regex, the conditions are :
IF ( DIFFERENT from
-\x20) at beginning of line AND ( IF DIFFERENT from\u+:) at beginning of line :=> Look for the next part
\R.+But, in my regex the unique condition is :
IF ( DIFFERENT from
-\x20OR DIFFERENT from\u+:) at beginning of line :=> Look for the next part
\R.+
However, these two formulations are totally identical, because the conditions are mutually exclusive.
So, ONLY
3cases may occur :-\x20\u+:Result Notes False False MATCH The regex = (?-is)<i>.*\R.+False True NO match The regex = (?-is)<i>.*True False NO match The regex = (?-is)<i>.*Best Regards,
guy038
-
-
Logically (per De Morgan’s Laws),
NOT(A OR B)is identical toNOT(A) AND NOT(B). Neither one is logically “simpler” or “harder”; they are just alternate formulations of the same logical concept. An individual might more naturally think in terms of one or the other, but they are the same thing. In this case, because of the way I was building it up to try to help the original poster understand, I thought it best to keep it in the same format that I built it up step-by-step in my mind.And I left the ^ and $ in there, again because they were there at an earlier stage in the development process, and there’s no good reason to remove them. (And in my mind, they help distinguish between “the end of the logical line”
$and “the separator character(s) that goes between one line and the next”\R, so they serve a mental purpose, and have no effect on the final regex.)I am quite willing to have things in alternate formats if it helps me understand or explain a regex better.
-
Hi, @hank-k, @peterjones and All,
@peterjones, I was upset because I initially thought that your two consecutive conditions should be interpreted as
IF(NOT (A))ORIF(NOT (B)), and I was perplex as my regex was interpreted asIF NOT ((A) OR (B))and I know, because of the Morgan’s laws, that one of the two should be false !Luckily, I was wrong. Your regex must be interpreted as
IF (NOT (A)) AND IF (NOT (B)), because each condition must be true, right after the line-break ! And, of course, you’re right : it’s just the two forms of the same logical concept :-)
Now, regarding the necessity to add the
$assertion or not, I did some tests and the problem seems quite difficult !Paste the following text in a new tab :
a a a a z a z a z a z a z a z a z a z a z a z a z a zIn this text :
-
Each line is repeated with the
3possible line-breaks (\r\n,\n, and\r) -
We have, successively,
3empty lines,3chars a,3strings aFFz,3strings aLSz,3strings aPSz and3strings aNELz
Just test the search of
$against these lines : after the first six lines correctly detected, the regex matches a null length after, both, thealetter and thezletterTo my mind, a correct regex to grasp all the characters of a line and thus, all the chars till the very end of each line, could be :
- SEARCH/MARK
(?s)^([^\r\n]+?|)(?=\r\n|\r|\n)
And, in order to get the very end of these lines, we would use the regex :
- SEARCH/MARK
(?s)^([^\r\n]+?|)(?=\r\n|\r|\n)\K
As you see, these formulations are not obvious too !
In fact, the simple
$regex matches any position right before theCR,LF,FF,LS,PSorNELcharacterBest Regards,
guy038
-
-
Hi, @peterjones and All,
Regarding the mix of special chars, in lines, which can be wrongly interpreted as line-ending chars, I improved my previous regex about :
-
The way to catch all the line contents of any complete line, wrapped or not, whatever its line-ending char(s), even none
-
The way to catch the true
$assertion, which represents the very end of any line, empty or not
SEARCH / MARK
(?s)^(?:[^\r\n]+?|(?<![\x{000C}\x{0085}\x{2028}\x{2029}]))(?=\r\n|\r|\n|\z)The contents of each line is stored as group
0, which can be re-used, in the replacement part, with the$0syntaxSEARCH / MARK
(?s)^(?:[^\r\n]+?|(?<![\x{000C}\x{0085}\x{2028}\x{2029}]))\K(?=\r\n|\r|\n|\z)This second regex gives the zero-length location of the very end of each line, empty or not, whatever its line-ending char(s), even none
I added some tests when special chars are alone or begin or end the current line, and this for the
3line-end syntaxes (\r\n,\nand\r), giving the INPUT text, below, which should work in all cases :a a a a z a z a z a z a z a z a z a z a z a z a z a z z z z z z z z z z z z z a a a a a a a a a a a aJust test my two new regexes against this INPUT text !
Best Regards
guy038
P.S. :
With the free-spacing mode, the first regex becomes :
SEARCH / MARK
(?xs) ^ (?: [^\r\n]+? | (?<! [\x{000C}\x{0085}\x{2028}\x{2029}] ) ) (?= \r\n | \r | \n | \z )So, this regex searches, either, for :
-
The smallest range of characters, different from
\rand\n, after beginning of current line, till the line-ending char(s) or the very end of file -
A zero-length string, at beginning of current line, not preceded by any of these four chars
\x{00OC},\x{0085},\x{2028}and\x{2029}and followed with any line-ending char(s) or by the very end of file
-
-
@guy038 said:
Paste the following text in a new tab … Each line is repeated with the 3 possible line-breaks ( \r\n, \n, and \r )
For me, at least, the line ending types indicated didn’t carry over in the copy, that is, I got this:
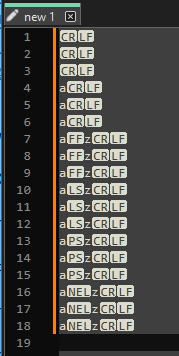
It’s not really a problem, but to carry on from that point to replicate what @guy038 is testing, one should manually adjust the line-endings before continuing.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login