How To Export Line & Column Coordinates to Clipboard ?
-
Appreciate your prompt response. The Python Script suggestion by mkupper below worked for me. Regarding the accuracy of the byte representations, I default to Base64 before applying coordinates. Thanks for the heads-up on that though.
-
Thanks mkupper , your script worked for me! How would I go about adding an extra instruction to the string to include the char found at a given position? I take it that Notepad++ reads the character to the right of the cursor?
-
@LanceMarchetti said in How To Export Line & Column Coordinates to Clipboard ?:
I take it that Notepad++ reads the character to the right of the cursor?
That’s just called “the current position” (of the caret).
How would I go about adding an extra instruction to the string to include the char found at a given position?
editor.getTextRange(editor.getCurrentPos(), editor.positionAfter(editor.getCurrentPos()))Obviously, no error checking added to that (like say if your current position is the final position in the file, the line of code is probably not correct…).
-
Thanks Alan. I struggled getting your addition to work, so I threw it at GPT-4 and it threw some magic back at me and it works like a charm now!
#Python script to copy current line, column, position, and byte info in Notepad++ to the clipboard # current_pos = editor.getCurrentPos() line = editor.lineFromPosition(current_pos) + 1 column = editor.getColumn(current_pos) + 1 position = current_pos + 1 byte_identifier = editor.getCharAt(current_pos) # *Get the Alt+key value using ASCII code points* if 'a' <= chr(byte_identifier) <= 'z': alt_key_value = ord(chr(byte_identifier)) else: alt_key_value = ord(chr(byte_identifier).upper()) clipboard_text = ( str(line) + " / " + str(column) + " / " + str(position) + " / ANSI " + hex(byte_identifier) + " [" + str(alt_key_value) + "]" ) editor.copyText(clipboard_text) #Example output result: # 2 / 1 / 7 / ANSI 0x1a [26] -
struggled getting your addition to work
Hmm, well you can see that it works using the PythonScript console:
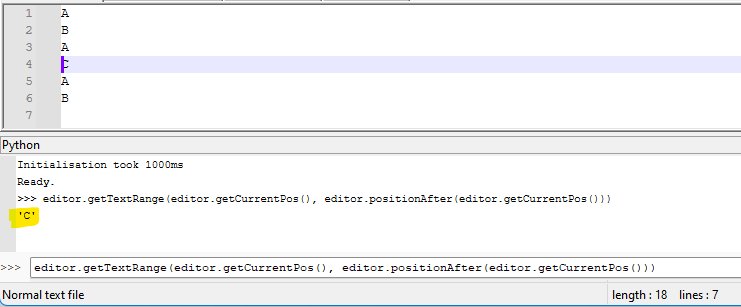
To open the console, choose Plugins > PythonScript > Show Console and then paste the line of code I provided at the box with the
>>>before it, and press Enter.So, to add what I did to @mkupper 's previous effort, you obtain the quite long:
editor.copyText(str(editor.lineFromPosition(editor.getCurrentPos())+1) + " / " + str(editor.getColumn(editor.getCurrentPos())+1) + " / " + str(editor.getCurrentPos()+1) + " / " + editor.getTextRange(editor.getCurrentPos(), editor.positionAfter(editor.getCurrentPos())))and that worked in my test to provide:
4 / 1 / 10 / C
so I threw it at GPT-4
Is this what people (that don’t know what they’re doing) do now?
I really hope the people of questionable skill in the self-driving car arena (or INSERT OTHER AREA OF CRITICAL IMPORTANCE HERE) don’t do this…
and it threw some magic back at me and it works like a charm now
Try executing its “magic” with your caret to the immediate left of a multibyte Unicode UTF-8 character, in a UTF8-encoded text file.
Result: Epic fail.
Details of epic fail, under PS2:
Traceback (most recent call last): if 'a' <= chr(byte_identifier) <= 'z': ValueError: chr() arg not in range(256)```Details of epic fail, under PS3:
Traceback: if 'a' <= chr(byte_identifier) <= 'z': <class 'ValueError'>: chr() arg not in range(0x110000)I suppose it is OK, because the code when it works it does output “ANSI”, suggesting its expertise is limited to ANSI encoding, but in today’s world, UTF-8 is the standard, so let’s write code for it.
BTW, there’s a plugin that provides pretty much everything you seem to be looking for in your output (well, except for getting the data into the clipboard). It’s called “Goto Line, Column” but a glance through Plugins Admin 's list didn’t seem to show it. Anyway, it can be found HERE and a previous mention of it in this forum occurred HERE.
-
Thanks Allan…I see now what you mean. It does work. And by the way I discovered an error in the GPT code. Numbers and lowercase translate to the correct ASCII key values, but as soon as I copy any Uppercase characters, I get the same key values of the lowercase set.
Example: ABC = [47] [48] [49] instead of [65] [66 [67]
Can you perhaps tell me how to fix that?
Oh, and just a side-note. I’m pretty new at this coding stuff, so I’m definitely going to make horrendous blunders. I drive trucks as my day job. My sideline interest is in computers and my time is restricted to a few hours on weekends with the PC.
I spend my time devising a new method of Steganography which I currently call Coordinated-Based Extraction.
I’m very excited about it, but I discovered sites like Stack-overflow are not as patient with newbies… , so I use artificial intelligence to help me understand how certain tools can be built with basic functions to achieve my goal.My methods with Notepad++ are so laughably unconventional that this past week I created a 12500x12500 pixel GIF image in Paintshop, and imported it into Notepad++ and then managed to bring the file size down to under 1KB while preserving the same image dimensions. The GIF still opens successfully. However the load to memory is a staggering 420MB.
I then created a 1x1 pixel GIF that weighed in at 830KB. To achieve this, I obfuscated a 310x310px jpeg image of a fishing boat by reversing it’s Base64 representation then decoded the entire string into a mishmash of bytes that in no way look like jpeg image data. But I was thrilled that I was able to unravel the process to uncover the original order of the bytes.
ANSI is just easier on my eyes without all the UTF-8 0x… blocks. Although I just have to be aware of the invisible bytes like no-break-space, tabs , line-feed, carriage return bytes etc.But at some stage I will definitely need to progress to the wonders of UTF-8 :)
-
@LanceMarchetti said in How To Export Line & Column Coordinates to Clipboard ?:
Example: ABC = [47] [48] [49] instead of [65] [66 [67]
Can you perhaps tell me how to fix that?
When you posted the AI generated code I saw that it contained
# *Get the Alt+key value using ASCII code points* if 'a' <= chr(byte_identifier) <= 'z': alt_key_value = ord(chr(byte_identifier)) else: alt_key_value = ord(chr(byte_identifier).upper())I puzzled over that and assumed the AI generated whatever you asked for and had wanted and asked that rather odd bit of code.
- The first line with
if 'a' <= chr(byte_identifier) <= 'z':says if it’s a lower case letter fromatozthen do the second line. - The second line seems like AI generated nonsense. It converts a number into a character and converts that character back into a the same number we had in the first place. At any rate, we are getting the numeric encoding of how the lower case ‘a’ to ‘z’ are stored in computer memory.
- The third line with the
else:is ok and means that if the character is NOT a lower case ‘a’ to ‘z’ then will do the fourth line. - The fourth line coverts whatever character we are at to its upper case version and then returns the numeric encoding of how the upper case version of whatever character we are dealing would be stored in computer memory.
Anyway, the entire thing seemed to be nonsense and so I assumed it was something wanted for whatever mysterious reasons. Part of what led me to that conclusion is that you had already convert a binary stream of data which is a image file, presumably a GIF, into a human readable decimal, hex, or some other encoding, and were then doing things in Notepad++ with that human readable version of the image. I could not see why you would have a need or desire to know the internal computer encoding of the human readable characters you are working with. They have little, if any, relationship with the original pixels in your image file.
That all said. You could replace that chunk of four lines with
alt_key_value = ord(chr(byte_identifier))You don’t need the lines with the
if, theelse, nor the last line that gets the upper case representation of a character. It’s still sort of strange if you had asked me but then the world of steganography can get strange at times. Maybe I should have replied to you in haiku? :-)Others have already commented on that the AI generated code only knows about bytes and was not set up to handle that these days text often contains Unicode characters that are well outside of the range used by plain ASCII.
- The first line with
-
@LanceMarchetti - I had a couple of thoughts based on what you seem to be trying to do.
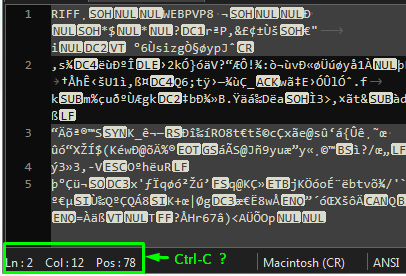
First - In your first post at the top of this page you included a screen shot of what looks like you using Notepad++ to view a .wepb image file using Notepad++. Notepad++ intended to be used with text files, not binary data files such as .WebP image files.
Text files are organized into lines of text with each one ending with an end-of-line mark. Notepad++ recognizes several ways that text can be encoded within a file and also recognizes several different styles of end-of-line marks.
Binary files usually have a structure that is not rows of text each ending with an end-of-line mark. Notepad++ does not know the structure, whatever it may be, but attempts to organize and display it as lines of text. What you see in Notepad++ is likely not recognizable or usable in Notepad++ or any text editor.
Second - WebP is a compressed image format. Image compression usually involves detecting regions within the image that have the same or similar pixel values, colors, brightness, etc. and translating those into shortcut codes. What you see in Notepad++ is alphabet soup, with the letters all chopped up, possibly pureed, well stirred, and some letters either removed or with parts removed. It’s not easy to extract the original message.
Third - If you intend to do a deep dive on an image file I would start with a tool such as Hexdump for Windows and to figure out the WebP file format. It may help to find tools that know a little about the structure of WebP files and to dump them in human readable format.
Notepad++ will be of little help other than to view and organize the text the output or results from tools such as hexdump.exe or whatever tools you find that extracts information from WebP files.
-
Brilliant snippet replacement indeed. Thank You, all ASCII Alt keys now return the correct values to clipboard.
-
@mkupper Noted on WebP image data chunks and line-endings. Thanks.
So basically, for now I’m going to have to work with Base64 to prevent any ‘bad byte’ coordinates. And Notepad++ is actually great when working with Base64.I think what makes my idea for extraction unique compared to other methods of Steganography , is that the target image is not altered or injected with any foreign bytes whatsoever, and can remain as is. (provided it is not edited or re-saved to a lossy compression after coordinates have been mapped)
I then convert a random external source image to Base64 and then ‘fetch’ the needed characters form the target image (using generated coordinates) to then compile the source image from the correct sequence of bytes identified in the target image.
Theoretically, using this method, it is possible to extract a larger image from a smaller one, which I’m guessing till now has not yet been possible.?
Example :
A 270KB Jpeg image of a wedding dress can be extracted from a 56KB GIF image of a fishing boat.The coordinate-set compiled from a source image is unique and
can only be applied to the intended target image
It will not work on just any image.Scenario 1:
Cindy in Washington wants to communicate to Franco in Brazil about where she feels their relationship is heading. She is using the PC at work and prefers not to email an image over the network or via webmail.
So she sends him an email that says:“Hi there Franco, I saw that one and only Instagram photo of you and your Dad building that sailing boat. Its truly amazing! I downloaded it and applied the necessary calculations for completion that you were asking about.”
sailboat_measurements.txtThe wedding dress (sailboat_measurements.txt) will remain in the form of coordinates (1,4,13,67,3,3…) until the receiver presents the right matching image for the extraction to occur by using a script (in this case a Javascript & HTML app)
Anyhow…this is what my mind has been busy with for a while now, so I appreciate you taking the time to read all my drivel.
If you would like to drop any further tips or advice my way concerning how I could create a more practical or solid coding environment that will allow me to compile my tool into a web app, that would be great. Thanks
Email: bWFyY2hldHRpLmxhbmNlQGdtYWlsLmNvbQ
-
@mkupper Here is a screenshot of a test I ran today of the extraction tool I’m working on :)
[https://drive.google.com/file/d/1F8zmZpvFWtudVecKA-FCyGxjcOziYd9F/view?usp=sharing](link url)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login