Old WhatsApp conversations with legacy encoded emojis - find and replace?
-
Hello. I am trying to export and archive some old WhatsApp conversations from 2012-2013.
However… some of these conversations use legacy encoded emojis from IOS 4.0, pre the Unicode 6.0 Standard. They display like this in the exported WhatsApp text file: For example This is U+E058, which is disappointed face in the legacy standard - but the Unicode disappointed face is U+1F61E. If I create a test WhatsApp conversation put in a disappointed face and export the chat, the basic text file renders the disappointed face correctly (😞) as it uses the most recent Unicode.
In Notepad++, might it be possible to display the hex code points of my old chats, and then perhaps do some kind of find and replace on U+E058 to make it U+1F61E? How would I go about doing something like this? I am approaching the limits of my understanding.
Many thanks.
-
For such things, I use a script for the PythonScript plugin WhatUniChar.py, which I then assign a keyboard shortcut to (see our FAQ: install and run a script in PythonScript for how to use that plugin to run the downloaded script)
If you want to replace it with a Unicode character that’s not in the BMP (ie, U+10000 or higher), you have to use surrogate codes (as mentioned here in the User Manual).
A site like fileformat.info can tell you what they are – for example, it’s entry for
U+1F61E: look at the UTF-16 (0xD83D 0xDE1E) or “C/C++/Java source code” ("\uD83D\uDE1E") values. (Sorry for the ads there; I have my adblocker prevent its horrendous number of ads, so it doesn’t bother me, and I often forget to warn people about the ads when I post a link there; I remembered this time ;-).)Once you know that you want to convert
U+E058into the surrogate pairU+D83D U+DE1E, then
FIND =\x{E058}
REPLACE =\x{D83D}\x{DE1E}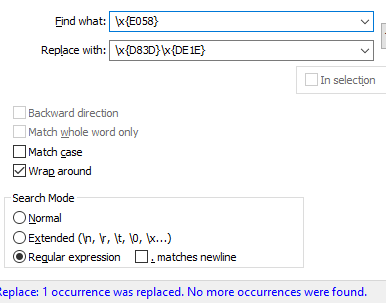
: =>
=> 
-
@PeterJones I did it - it worked! Thank you so much for going through the process in such detail. I knew it must be possible, and this whole process has taught me a great deal - not least an increased knowledge of Unicode characters!
Now I will look into how to semi-automate this process… -
Hello, @jakobeig, @peterjones and All,
Here are two links to easily get the surrogate values :
https://russellcottrell.com/greek/utilities/SurrogatePairCalculator.htm
You may enter, either, from up to bottom :
-
The
code pointof the character -
The
surrogate pairof the character -
The
characteritself
https://onlinetools.com/unicode/convert-unicode-to-utf16
-
You enter the character, itself, on the left panel
-
You get the
surrogate pairon the right panel
And, from the same site, the link :
https://onlinetools.com/unicode/convert-unicode-to-code-points
Would return the
code-pointof the character
Now, for me, the best way is to use the
compart.comsite and add, either, thecharacter, itscode-point, itsUTF-16encoding or itsUTF-8encoding :So, type in, in the
Google searchzone, either :-
site:compart.com 🚂
-
site:compart.com 1F682
-
site:compart.com 0xd83d 0xde82
-
site:compart.com 0xf0 0x9f 0x9a 0x82
And click, generally, on the first or second proposed link !
The good news is that I also created a macro which calculates, from within N++, the surrogate pair of any char over the
BMP, so with code-point>= \x{10000}!!This macro changes any
\x{[1]#####}string, of a stream selection, into its surrogate pair\x{####}\x{####}:<Macro name="Surrogates Pairs in Selection" Ctrl="no" Alt="yes" Shift="yes" Key="83"> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?-i)\\x\{(10|[[:xdigit:]])[[:xdigit:]]{4}" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="$0\x1F" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?i)(?:(1)|(2)|(3)|(4)|(5)|(6)|(7)|(8)|(9)|(A)|(B)|(C)|(D)|(E)|(F)|(10))(?=[[:xdigit:]]{4}\x1F\})|(?:(0)|(1)|(2)|(3)|(4)|(5)|(6)|(7)|(8)|(9)|(A)|(B)|(C)|(D)|(E)|(F))(?=[[:xdigit:]]{0,3}\x1F\})" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="(?{1}0000)(?{2}0001)(?{3}0010)(?{4}0011)(?{5}0100)(?{6}0101)(?{7}0110)(?{8}0111)(?{9}1000)(?{10}1001)(?{11}1010)(?{12}1011)(?{13}1100)(?{14}1101)(?{15}1110)(?{16}1111)(?{17}0000)(?{18}0001)(?{19}0010)(?{20}0011)(?{21}0100)(?{22}0101)(?{23}0110)(?{24}0111)(?{25}1000)(?{26}1001)(?{27}1010)(?{28}1011)(?{29}1100)(?{30}1101)(?{31}1110)(?{32}1111)" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="([01]{10})([01]{10})(?=\x1F)" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="110110\1\x1F}\\x{110111\2" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?:(0000)|(0001)|(0010)|(0011)|(0100)|(0101)|(0110)|(0111)|(1000)|(1001)|(1010)|(1011)|(1100)|(1101)|(1110)|(1111))(?=[[:xdigit:]]*\x1F\})|\x1F" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="(?{1}0)(?{2}1)(?{3}2)(?{4}3)(?{5}4)(?{6}5)(?{7}6)(?{8}7)(?{9}8)(?{10}9)(?11A)(?12B)(?13C)(?14D)(?15E)(?16F)" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> </Macro>-
Place it within the
<macros>..........</macros>.section of your activeshortcuts.wmlfile -
Save your
shortcuts.wmlfile -
Stop and restart Notepad++
Thus, for example, from the selected text, below, located in any file :
\x{10000} # The FIRST Unicode character of PLANE 1 ( SMP ) .... .... .... \x{1F682} # The 'STREAM LOCOMOTIVE' character .... .... .... \x{10FFFF} # The LAST Unicode character of PLANE 16 ( SPUA-B)After execution of this macro, you would get the expected text :
\x{D800}\x{DC00} # The FIRST Unicode character of PLANE 1 ( SMP ) .... .... .... \x{D83D}\x{DE82} # The 'STREAM LOCOMOTIVE' character .... .... .... \x{DBFF}\x{DFFF} # The LAST Unicode character of PLANE 16 ( SPUA-B)
Remark : I, personally, chose the
Alt + Shift + Sshortcut, but, of course, you may use any other one by changing the first line of the macro !Best Regards,
guy038
-
-
@PeterJones said in Old WhatsApp conversations with legacy encoded emojis - find and replace?:
For such things, I use a script for the PythonScript plugin WhatUniChar.py , which I then assign a keyboard shortcut to (see our FAQ: install and run a script in PythonScript for how to use that plugin to run the downloaded script)
… and I have another script that might not be helpful for your exact use case (because you have the actual character, not the text of the codepoint), but my pyscReplaceBackslashSequence.py, which I assign to
Alt+\, which allows me to type something likeU+1F61Eor\x{1F61E}or😞then hit myAlt+\shortcut, and it will convert it from the codepoint / entity into the actual character (and it handles the surrogate pair calculation inside the script) … so given the same “input” data that Guy showed in his example, instead of running Guy’s macro to show you the surrogate pair, you could use my script to actually convert that hex-notation into the actual character.Hmm, and I’ve just added a “TODO” for me to update my
WhatUniCharscript to show surrogate pairs for those not in the BMP… I’ll post an update here once I’ve got that script updated.UPDATE: WhatUniChar.py has been updated to show surrogate pair (it of course won’t help with your early-IOS-specific codepoints)
-
Hello @peterjones and All,
Peter, I’m afraid that your excellent and improved Python script
WhatUniChar.pydoes not work at all for anyNON-ASCIIcharacter found in anANSIencoded file :-(Luckily, everything is allright if we deal with Unicode encoded files (
UTF-8,UTF-8-BOM,UTF-16 BEandUTF-16 LE)
I suppose that it will not be easy to find out an acceptable solution, because :
-
The well-known
Windows-125xANSI encodings contains some NON-defined characters -
For characters between
U+0080andU+009F, they usually match some unicode characters with code-point overU+00FF -
For characters between
U+00A0andU+00FF, they can be searched with an unique syntaxe inANSIfiles and with two syntaxes in anUnicodefile !
Refer, for example, to the list of the
Win-1252characters, overU+007F, below :•---------------------•-------------------------•------------• | SEARCH in an | SEARCH in an | SEARCHED | | ANSI encoded file | UNICODE encoded file | character | •---------------------•----------•--------------•------------• | \x80 | : \x{20AC} | € | | \x81 | \x81 : \x{0081} | | | \x82 | : \x{201A} | ‚ | | \x83 | : \x{0192} | ƒ | | \x84 | : \x{201E} | „ | | \x85 | : \x{2026} | … | | \x86 | : \x{2020} | † | | \x87 | : \x{2021} | ‡ | | \x88 | : \x{02C6} | ˆ | | \x89 | : \x{2030} | ‰ | | \x8A | : \x{0160} | Š | | \x8B | : \x{2039} | ‹ | | \x8C | : \x{0152} | Œ | | \x8D | \x8D : \x{008D} | | | \x8E | : \x{017D} | Ž | | \x8F | \X8F : \x{008F} | | •---------------------•----------•--------------•------------• | \x90 | \x90 : \x{0090} | | | \x91 | : \x{2018} | ‘ | | \x92 | : \x{2019} | ’ | | \x93 | : \x{201C} | “ | | \x94 | : \x{201D} | ” | | \x95 | : \x{2022} | • | | \x96 | : \x{2013} | – | | \x97 | : \x{2014} | — | | \x98 | : \x{02DC} | ˜ | | \x99 | : \x{2122} | ™ | | \x9A | : \x{0161} | š | | \x9B | : \x{203A} | › | | \x9C | : \x{0153} | œ | | \x9D | \x9D : \x{009D} | | | \x9E | : \x{017E} | ž | | \x9F | : \x{0178} | Ÿ | •---------------------•----------•--------------•------------• | \xA0 | \xA0 : \x{00A0} | | | \xA1 | \xA1 : \x{00A1} | ¡ | | \xA2 | \xA2 : \x{00A2} | ¢ | | \xA3 | \xA3 : \x{00A3} | £ | | \xA4 | \xA4 : \x{00A4} | ¤ | | \xA5 | \xA5 : \x{00A5} | ¥ | | \xA6 | \xA6 : \x{00A6} | ¦ | | \xA7 | \xA7 : \x{00A7} | § | | \xA8 | \xA8 : \x{00A8} | ¨ | | \xA9 | \xA9 : \x{00A9} | © | | \xAA | \xAA : \x{00AA} | ª | | \xAB | \xAB : \x{00AB} | « | | \xAC | \xAC : \x{00AC} | ¬ | | \xAD | \xAD : \x{00AD} | | | \xAE | \xAE : \x{00AE} | ® | | \xAF | \xAF : \x{00AF} | ¯ | •---------------------•----------•--------------•------------• | \xB0 | \xB0 : \x{00B0} | ° | | \xB1 | \xB1 : \x{00B1} | ± | | \xB2 | \xB2 : \x{00B2} | ² | | \xB3 | \xB3 : \x{00B3} | ³ | | \xB4 | \xB4 : \x{00B4} | ´ | | \xB5 | \xB5 : \x{00B5} | µ | | \xB6 | \xB6 : \x{00B6} | ¶ | | \xB7 | \xB7 : \x{00B7} | · | | \xB8 | \xB8 : \x{00B8} | ¸ | | \xB9 | \xB9 : \x{00B9} | ¹ | | \xBA | \xBA : \x{00BA} | º | | \xBB | \xBB : \x{00BB} | » | | \xBC | \xBC : \x{00BC} | ¼ | | \xBD | \xBD : \x{00BD} | ½ | | \xBE | \xBE : \x{00BE} | ¾ | | \xBF | \xBF : \x{00BF} | ¿ | •---------------------•----------•--------------•------------• | \xC0 | \xC0 : \x{00C0} | À | | \xC1 | \xC1 : \x{00C1} | Á | | \xC2 | \xC2 : \x{00C2} |  | | \xC3 | \xC3 : \x{00C3} | à | | \xC4 | \xC4 : \x{00C4} | Ä | | \xC5 | \xC5 : \x{00C5} | Å | | \xC6 | \xC6 : \x{00C6} | Æ | | \xC7 | \xC7 : \x{00C7} | Ç | | \xC8 | \xC8 : \x{00C8} | È | | \xC9 | \xC9 : \x{00C9} | É | | \xCA | \xCA : \x{00CA} | Ê | | \xCB | \xCB : \x{00CB} | Ë | | \xCC | \xCC : \x{00CC} | Ì | | \xCD | \xCD : \x{00CD} | Í | | \xCE | \xCE : \x{00CE} | Î | | \xCF | \xCF : \x{00CF} | Ï | •---------------------•----------•--------------•------------• | \xD0 | \xD0 : \x{00D0} | Ð | | \xD1 | \xD1 : \x{00D1} | Ñ | | \xD2 | \xD2 : \x{00D2} | Ò | | \xD3 | \xD3 : \x{00D3} | Ó | | \xD4 | \xD4 : \x{00D4} | Ô | | \xD5 | \xD5 : \x{00D5} | Õ | | \xD6 | \xD6 : \x{00D6} | Ö | | \xD7 | \xD7 : \x{00D7} | × | | \xD8 | \xD8 : \x{00D8} | Ø | | \xD9 | \xD9 : \x{00D9} | Ù | | \xDA | \xDA : \x{00DA} | Ú | | \xDB | \xDB : \x{00DB} | Û | | \xDC | \xDC : \x{00DC} | Ü | | \xDD | \xDD : \x{00DD} | Ý | | \xDE | \xDE : \x{00DE} | Þ | | \xDF | \xDF : \x{00DF} | ß | •---------------------•----------•--------------•------------• | \xE0 | \xE0 : \x{00E0} | à | | \xE1 | \xE1 : \x{00E1} | á | | \xE2 | \xE2 : \x{00E2} | â | | \xE3 | \xE3 : \x{00E3} | ã | | \xE4 | \xE4 : \x{00E4} | ä | | \xE5 | \xE5 : \x{00E5} | å | | \xE6 | \xE6 : \x{00E6} | æ | | \xE7 | \xE7 : \x{00E7} | ç | | \xE8 | \xE8 : \x{00E8} | è | | \xE9 | \xE9 : \x{00E9} | é | | \xEA | \xEA : \x{00EA} | ê | | \xEB | \xEB : \x{00EB} | ë | | \xEC | \xEC : \x{00EC} | ì | | \xED | \xED : \x{00ED} | í | | \xEE | \xEE : \x{00EE} | î | | \xEF | \xEF : \x{00EF} | ï | •---------------------•----------•--------------•------------• | \xF0 | \xF0 : \x{00F0} | ð | | \xF1 | \xF1 : \x{00F1} | ñ | | \xF2 | \xF2 : \x{00F2} | ò | | \xF3 | \xF3 : \x{00F3} | ó | | \xF4 | \xF4 : \x{00F4} | ô | | \xF5 | \xF5 : \x{00F5} | õ | | \xF6 | \xF6 : \x{00F6} | ö | | \xF7 | \xF7 : \x{00F7} | ÷ | | \xF8 | \xF8 : \x{00F8} | ø | | \xF9 | \xF9 : \x{00F9} | ù | | \xFA | \xFA : \x{00FA} | ú | | \xFB | \xFB : \x{00FB} | û | | \xFC | \xFC : \x{00FC} | ü | | \xFD | \xFD : \x{00FD} | ý | | \xFE | \xFE : \x{00FE} | þ | | \xFF | \xFF : \x{00FF} | ÿ | •---------------------•----------•--------------•------------•Best Regards,
guy038
-
-
@guy038 said in Old WhatsApp conversations with legacy encoded emojis - find and replace?:
WhatUniChar.py does not work at all for any NON-ASCII character found in an ANSI encoded file
The shocking thing is is that you seem to expect that to actually work. :-)
Aside from historical points of interest (perhaps this is one of those), isn’t it time to let go of non-Unicode encodings? -
@guy038 said in Old WhatsApp conversations with legacy encoded emojis - find and replace?:
I’m afraid that your excellent and improved Python script
WhatUniChar.pydoes not work at all for any NON-ASCII character found in an ANSI encoded fileOf course it doesn’t. That’s why I named it
WhatUniChar, whereUniis short forUnicode. If the characters are not encoded as Unicode codepoints, that script is the wrong tool for the job.The ANSI character sets were useful in the 80s, when there was no single, agreed-upon international encoding, but since Unicode was developed in the 90s and popularized in the 00’s, there’s been no convincing reason for me to continue to use those ancient charsets. (And the fact that Notepad++ still has major, daily-use features – such as UDL and auto-completions – that are not Unicode-enabled is a huge embarrassment to an otherwise-excellent application.)
-
Hello, @peterjones, @alan-kilborn and All,
From, your two last posts, Alan and Peter, I asked myself : which is the distribution of all my
textfiles, regarding their encoding ?I considered, as a text file, all the files with the main following extensions, by importance level :
txt,.py,html,htm,xml,ini,msg,csv,logas well as few other files with rare extension
Now, using the
iconv.exeutility to get all theNON-UTF8files and, then, thexxd.exesoftware to omit theUFT-16encoded files, I was able, little by little, to restrict my list to360files, about, for which I possibly could change the encoding fromANSItoUTF-8!Of course, opening all the files, one at a time, in N++, changing their encoding and saving them seemed rather tedious. Thus, I used a simple python script to achieve this task easily :
''' NAME : Move_to_UTF8_encoding.py REMARK : The fonction 'npp_get_statusbar' is an idea of @alan-kilborn This script : - Opens a file which contains a list of ABSOLUTE file-paths - Read, successively, the file-paths from that list - Open EACH file in N++ - Perform the 'Convert to UTD-8' action on the CURRENT opened ANSI file - Save and close EACH file, one at a time NOTES : - The file, containing the list of ABSOLUTE file-paths to OPEN, is an UTF-8 encoded file, with 'Windows' EOL - This list must NOT contain EMPTY or BLANK lines - But, any line beginning with the '#' character is simply IGNORED ( So begin any EMPTY line or COMMENT line with a '#' char ! ) - The PATHS are designated by a SIMPLE character ANTI-SLASH ( Ex : D:\Dir_1\Dir_2\Name.txt ). NO need to DOUBLE the ANTISLASH ( \\ ) - On the same way, NO need to SURROUND the file-paths, containing SPACE characters, with DOUBLE-QUOTES - This list may contain some ACCENTUATED characters ''' from Npp import * import time import ctypes from ctypes.wintypes import BOOL, HWND, WPARAM, LPARAM, UINT console.show() console.clear() with open('D:\\Verif.txt') as file: for file_path in file: file_path = file_path.strip('\n') if file_path[0] == "#": continue notepad.open(file_path) # ---------------------------------------------------------------------------------------------------------------------------------------------------- # From @alan-kilborn, in post https://community.notepad-plus-plus.org/topic/21733/pythonscript-different-behavior-in-script-vs-in-immediate-mode/4 # ---------------------------------------------------------------------------------------------------------------------------------------------------- def npp_get_statusbar(statusbar_item_number): WNDENUMPROC = ctypes.WINFUNCTYPE(BOOL, HWND, LPARAM) FindWindowW = ctypes.windll.user32.FindWindowW FindWindowExW = ctypes.windll.user32.FindWindowExW SendMessageW = ctypes.windll.user32.SendMessageW LRESULT = LPARAM SendMessageW.restype = LRESULT SendMessageW.argtypes = [ HWND, UINT, WPARAM, LPARAM ] EnumChildWindows = ctypes.windll.user32.EnumChildWindows GetClassNameW = ctypes.windll.user32.GetClassNameW create_unicode_buffer = ctypes.create_unicode_buffer SBT_OWNERDRAW = 0x1000 WM_USER = 0x400; SB_GETTEXTLENGTHW = WM_USER + 12; SB_GETTEXTW = WM_USER + 13 npp_get_statusbar.STATUSBAR_HANDLE = None def get_result_from_statusbar(statusbar_item_number): assert statusbar_item_number <= 5 retcode = SendMessageW(npp_get_statusbar.STATUSBAR_HANDLE, SB_GETTEXTLENGTHW, statusbar_item_number, 0) length = retcode & 0xFFFF type = (retcode >> 16) & 0xFFFF assert (type != SBT_OWNERDRAW) text_buffer = create_unicode_buffer(length) retcode = SendMessageW(npp_get_statusbar.STATUSBAR_HANDLE, SB_GETTEXTW, statusbar_item_number, ctypes.addressof(text_buffer)) retval = '{}'.format(text_buffer[:length]) return retval def EnumCallback(hwnd, lparam): curr_class = create_unicode_buffer(256) GetClassNameW(hwnd, curr_class, 256) if curr_class.value.lower() == "msctls_statusbar32": npp_get_statusbar.STATUSBAR_HANDLE = hwnd return False # stop the enumeration return True # continue the enumeration npp_hwnd = FindWindowW(u"Notepad++", None) EnumChildWindows(npp_hwnd, WNDENUMPROC(EnumCallback), 0) if npp_get_statusbar.STATUSBAR_HANDLE: return get_result_from_statusbar(statusbar_item_number) assert False St_bar = npp_get_statusbar(4) # Zone 4 ( STATUSBARSECTION.UNICODETYPE ) if St_bar == 'ANSI': # => Conversion to 'UTF-8', without BOM, RECOMMENDED ! time.sleep(0.5) notepad.runMenuCommand("Encoding", "Convert to UTF-8") notepad.save() time.sleep(0.5) notepad.close()
REMARK :
- As I was a bit anxious about the needed time to get the encoding change and the save action, for each file, I preferred to use timers to properly ensure the entire process but, may be, these timers are not necessary !
So, after the various modifications, I got a list of
11,578files whose distribution, according to their encoding, is as follows :UTF-8 BOM : 208 | UTF-16 LE BOM : 39 | UTF-16 BE BOM : 4 | UTF-8 : 540 ( 0 byte ) | => 10,737 with UNICODE encoding ( 92,7 % ) UTF-8 : 9,946 | ANSI : 841 ---------- TOTAL 11,578You certainly note that there still are a lot of
ANSIfiles, but most of them are lang or configuration files for which the change of the encoding is rather forbidden or, at least, not welcome !Best Regards,
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login