how to delete duplicate lines and keep one line in notepad++ like attached image
-
Gen 1:1
Gen 1:1
Gen 1:1
Gen 1:2
Gen 1:2
Gen 1:2
Gen 1:3
Gen 1:6
Gen 1:6
Gen 1:7
Gen 1:8
Gen 1:8
Gen 1:8
Gen 1:8
Gen 1:8- looks like this
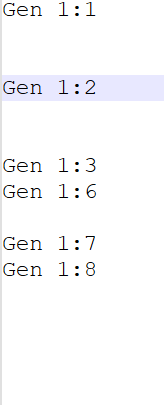
- looks like this
-
Interesting. Most of the time, what people want is Edit > Line Operations > Remove Duplicate Lines … but that gets rid of the lines completely, whereas you seem to want to delete the text but keep the empty lines.
There are other ways to do it, but if I were doing it for me, I would break it into two steps:
- indicate the lines to be emptied using ☹
FIND WHAT =(?-s)(?:^|\G)(.+)\R\K(?=\1)
REPLACE WITH =☹
SEARCH MODE = Regular Expression
REPLACE ALL - empty any lines starting with ☹:
FIND WHAT =(?-s)^☹.*$
REPLACE WITH = empty/nothing
SEARCH MODE = Regular Expression
REPLACE ALL
This works by matching the zero-width between a pair of duplicate lines, and replacing that with a frown; then replace any lines that start with a frown with an empty line (but keep the EOL sequence). Since the “lookahead” is used in the first regex, the cursor hasn’t moved forward, so it can match the current line just after the previous replacement as the “old” and again check the next line to see if it matches.
Or you could do it all in “one” step, as long as you are willing to hit REPLACE ALL more than once:
- FIND WHAT =
(?-s)(?:^|\G)(.+)\R(^$\R)*\K\1
REPLACE WITH = empty/nothing
SEARCH MODE = Regular Expression
REPLACE ALL until there are no more matches and the status line in the Replace dialog saysReplace All: 0 occurrences were replaced in entire file
This works by looking for a line, and any empty lines, followed by the same line again, matching the second occurrence of the line, and replacing it with nothing. But because this one replaced the second non-empty line with nothing, it loses the “memory” of the first line, and thus it won’t be able to match another immediate instance of that same first line. However, if you run it a few times, it will eventually catch them all.
Both of these procedures assume that the data is in the order you suggest, where all the repeats are right in a row… if your data had 1:1 then 1:2 then 1:1 again, it would not find the second 1:1 as a duplicate.
-—Useful References
- indicate the lines to be emptied using ☹
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login