Getting "Invalid Regular Expression" for an extremely simple expression
-
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
While I appreciate the help, my point coming here was not to get help with regular expressions, which I’ve been using for decades, it was to report a bug in NP++ RE search.
Also, I did mention that I had not checked the box for “. matches newline” so the RE should not need the removal of the CRLF. I knew exactly what string I was looking for and that it existed.
We couldn’t know, from your post, your level of sophistication. For example, if someone posted the expression you gave here, they might not understand that if there were multiple quoted strings on a single line and the one ending in employeeId were not the first one, that expression would match everything from the first quote on the line through the string ending in employeeId. Since the expression would try each quote in turn and then scan all the way to the end of the line, if lines were long and contained many quoted strings, that could possibly trigger the matching complexity heuristic.
The heuristic that puts up that message is part of the Boost::Regex package, which Notepad++ uses for regular expressions. Unfortunately, that means it’s a bit of a black box to most of us, even those who know something about the Notepad++ code base.
If your purpose is to post a bug report, rather than to ask for help, this forum is not the right place to do it; Issues for Notepad++ on GitHub is where you would need to do that.
You would need to include a minimal way to reproduce the error message. This one comes up enough to be annoying, so I don’t think it’s unreasonable that someone might take an interest in following what happens in the code and trying to get to the bottom of why this message sometimes appears when it doesn’t seem to make sense. Perhaps it is a bug, or perhaps we could better understand what regular expressions and data cause this error when it is not intuitively expected.
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
@Scott-Gartner said:
While I appreciate the help, my point coming here was not to get help with regular expressions, which I’ve been using for decades, it was to report a bug in NP++ RE search.
Also, I did mention that I had not checked the box for “. matches newline” so the RE should not need the removal of the CRLF. I knew exactly what string I was looking for and that it existed.
We couldn’t know, from your post, your level of sophistication. For example, if someone posted the expression you gave here, they might not understand that if there were multiple quoted strings on a single line and the one ending in employeeId were not the first one, that expression would match everything from the first quote on the line through the string ending in employeeId. Since the expression would try each quote in turn and then scan all the way to the end of the line, if lines were long and contained many quoted strings, that could possibly trigger the matching complexity heuristic.
The heuristic that puts up that message is part of the Boost::Regex package, which Notepad++ uses for regular expressions. Unfortunately, that means it’s a bit of a black box to most of us, even those who know something about the Notepad++ code base.
If your purpose is to post a bug report, rather than to ask for help, this forum is not the right place to do it; Issues for Notepad++ on GitHub is where you would need to do that.
You would need to include a minimal way to reproduce the error message. This one comes up enough to be annoying, so I don’t think it’s unreasonable that someone might take an interest in following what happens in the code and trying to get to the bottom of why this message sometimes appears when it doesn’t seem to make sense. Perhaps it is a bug, or perhaps we could better understand what regular expressions and data cause this error when it is not intuitively expected.
Thanks @Coises, I thought this was the best first place to post this. Considering the obvious simplicity of the RE and the text of the error, I actually expected others to chime in saying they had seen this as well. I actually can’t imagine that it’s a problem in an underlying RE library, unless they have recently rewritten that library or made some significant change. I kinda assumed this would turn out to be a timeout bug that was masquerading as a bug in the RE library (and I think that’s still the most likely culprit considering how old and well-tested most of the RE standard libraries are).
Given that nobody else chimed in as having seen the bug, I’ll post it to GitHub.
-
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
Given that nobody else chimed in as having seen the bug, I’ll post it to GitHub.
It’s not so much that we haven’t seen that behavior as that if there is anyone who understands the Boost::regex library code deeply enough to distinguish a situation in which issuance of that error is “working as intended” from one in which it is not, that person has not made themselves known.
You mentioned in another post:
I have run extremely similar searches using NP++ in the past with no issues until recent versions.
Since you already have a test case on your machine now… if you could install an older version and demonstrate to yourself that this exact search of these exact files does not cause this error in that version, but does in some later version, that would go a long way toward indicating that it is a bug, and it would give us some idea where to look (either a newer version of Boost::regex or some change in the way it’s incorporated into Notepad++).
A test case we can use to reproduce it would still be almost essential, though.
-
All, maybe @Scott-Gartner is on to something.
On a lark I did a Find in Files for
".*employeeId"in a set of folders with a few thousand text files. It ground away for a while, scanning through files and thenFind: Invalid Regular Expressionpopped up at the bottom of the dialog box. The...button has the complexity message.I’ll skip explaining the trial and error. The line it’s failing on is 40,390 characters long. It’s part of some JavaScript code loading JSON into a variable. It’s a plain text file with no highlighting. If I chop it in half the find hangs unusually long but then says
not found.Maybe one of you can figure out what is happening. I put the file at https://pastebin.com/gYBMQnF8
It also fails on v8.3.3 which is the oldest copy I currently have on the machine. It fails for both x32 and x64 and so that’s not an issue. It fails when running using
-noPluginSurprisingly, it also fails if I try
".*?employeeId"which I though would disable backtracking. There are a lot of quotes in that line. -
@mkupper said in Getting "Invalid Regular Expression" for an extremely simple expression:
Maybe one of you can figure out what is happening. I put the file at https://pastebin.com/gYBMQnF8
[…]
Surprisingly, it also fails if I try".*?employeeId"which I though would disable backtracking. There are a lot of quotes in that line.I can confirm that both your expressions fail with the complexity message on that file. (Notepad++ v8.6.8-x64)
I also note that the expression I suggested:
"[^"\r\n]*employeeId"
finds the single occurrence of that expression, in line 2, and does not cause an error.Edit to add:
If for some reason one really did want to match the first quote on a line, the last occurrence of employeeId" on the same line, and everything in between (as the original poster’s expression says), this:
"(.*employeeId"|.*(*SKIP)(*FAIL))
would work. -
@mkupper said in Getting "Invalid Regular Expression" for an extremely simple expression:
Surprisingly, it also fails if I try ".*?employeeId"which I though would disable backtracking. There are a lot of quotes in that line.
Either way — shortest first or longest first — the regular expression engine finds a quote, then scans all the way to the end of the line looking for
employeeId". When it doesn’t find it, it moves on to the next quote and tries the same thing again. Apparently there is not enough intelligence, or optimization, or “smarts,” or whatever you want to call it, for the engine to realize that if it didn’t findemployeeIdthe first time it scanned the line, it’s not going to find it when it scans again starting from a later position.The message is, in my opinion, poorly worded. It says, “The complexity of matching the regular expression exceeded predefined bounds.” I think a lot of people misread that as “complexity of the regular expression” instead of “complexity of matching the regular expression.”
Even then, though, it’s not really complexity that triggers the message, it’s inefficiency. When I looked at that code once before, I wasn’t able to follow the details, but I could get the overall sense of it. It’s looking to see how much “work” (measured, I think, as the size of some internal stack) it’s doing relative to how much progress it’s making moving the starting match point forward in the file. When it looks like the amount of text being scanned is growing far faster (worse than proportional to the square, I think) than the amount of text being processed — that is, it’s re-examining the same text again and again and not making much headway — it issues this message.
-
When you have something like
".*employeeId"you are asking the regular expression engine to- Find a double quote.
- Skip over any number of characters, it could be billions and those characters can be double quotes, until you find the
e. It ls looking for the last ‘e’ on the line as it first tries for the longest match. - See if the next character is the letter
m. If not back the step 2 scanner for the previous ‘e’ and retry step 3 again. Keep looping and backing up until you either find an ‘e’ followed by ‘m’ or you backed up all the way to the double quote found in step one. The process is known as backtracking. If there were no matches resumes step one to scan for another another double quotes and starts it all over.
The test file I posted has 5205 double quotes and 4007 of the letter e. It’s going to crunch away at that line trying about 20 million starting and ending points before it decided there was no match and moved to the next line.
I thought quick fix was
".*?employeeId"but that only changes in step 2 that it will look for the first e and that work it’s way forwards. It’s still at least 20 million tests as theemployeeId"part does not exist in the line of text.Either way, the regular expression engine decided after a few million attempts to match that it was a waste of time, and blames you for making an expression that was too complicated…
@Coises’
"[^"\r\n]*employeeId"works because his step 2 is[^"\r\n]*ewhich scans forward. for anything that is not a double quote or end of line. It The hunt for theemployeeId"part will abort much faster as it’ll hit the next double quote and then go back to step one. The\r\npart is necessary as the not-a character scanner will cheerfully scan past the end of a line and scan all the way top to the end of the file when it’s hunting. The regular is-a-character scanner stops at the end of the line.Thus @Coises’ version aborts the scan much faster as it is not scanning to nearly the end of a long line over and over. We are making the assumption though that you were not seeking a match that spans from the first double quote on a line and goes past all intervening double quotes on to
employeeId"The “.*?employeeId” expression I proposed would give you the shortest match or"....employeeId"but still did too much scanning.Note that any of the matches proposed will return the wrong match if the data string contains escaped double quotes
"...\"...employeeId". Details such as this are why regular expressions are not a good idea for JSON. -
@Coises said :
The message is, in my opinion, poorly worded. It says, “The complexity of matching the regular expression exceeded predefined bounds.”
I think a lot of people misread that as “complexity of the regular expression” instead of “complexity of matching the regular expression.”
Maybe put in a feature request to change this wording to something better? Or at least suggest some better wording here?
-
@Alan-Kilborn said in Getting "Invalid Regular Expression" for an extremely simple expression:
Maybe put in a feature request to change this wording to something better? Or at least suggest some better wording here?
Hmmm… honestly, I’m not sure there is a good way to word that message — the very existence of the message is the problem. The right way (in my oh-so-humble opinion) to handle this would be to pop up a progress dialog when searches take more than a user-configurable amount of time, and let the user decide when it’s been going on too long and should be canceled.
Doing something like that with the search in Columns++ is on my list of potential future enhancements. I think it might require modifying Boost::regex, though; if it does, I will find that idea rather uncomfortable. If I ever do get it done and working right in my plugin, that could serve as a proof-of-concept for doing it in Notepad++.
Or (considering that the problem @mkupper demonstrated would have been avoided if the regex processing recognized that if a fixed string didn’t match from a given position to the end of a line it couldn’t possibly match from a later position in the line to the end of the same line), maybe we just need a smarter Regex engine. (I have no idea if such a thing exists… oy, another research project!)
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
the very existence of the message is the problem
It’s what Boost provides (apparently).
Enhancements should be pursued through the Boost project, IMO.A sort of obvious statement: Boost is to Notepad++ regex as Scintilla is to Notepad++ editing…and although there are some Notepad++ side hacks to Scintilla, I’d think that Notepad++ hacks to Boost would be more difficult and harder to maintain.
maybe we just need a smarter Regex engine
Replacing the regex engine that Notepad++ uses would likely be a hard sell to the Notepad++ author, but I suppose anything is possible.
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
maybe we just need a smarter Regex engine. (I have no idea if such a thing exists… oy, another research project!)
The
regexPython package is generally considered one of the most capable regex engines out there, but even that package takes quadratic time (in the length of the input) when testing the regular expression".*employeeId"on many repetitions of the string"employeeI"(including a space after the closing quote).As I understand it, some regex implementations (like this one) enable compiling a regex to a DFA, which has no backtracking and thus could never take more than linear time to process any input, but there’s a big issue here:
The Notepad++ regex engine would need to automatically determine when a regular expression can be represented with a DFA (which no engine that I know of can do), because I somehow doubt that the user base would be in favor of a new option that can’t even be understood without studying CS theory.
NOTE: To spare the ambitious among you some trouble, don’t even bother trying to come up with a general algorithm that can determine whether a Boost regex can be represented with a DFA. Such an algorithm is literally impossible for boring pedantic reasons.
-
I was more just surprised that there are (apparently) no optimizing heuristics such as recognizing that if B contains no back-references to A, if A.*B doesn’t match at the first position A matches, it can’t match anywhere in the line (if . does not match line endings) or anywhere at all (if . does match line endings). I would have thought that .*, especially, was so common that simple expressions joined by .* would have more clever processing.
Apparently regular expressions are executed rather literally (like compiling code in debug mode with optimization off). Then again, aside from here, in Notepad++, I guess regular expressions are usually used by fairly “geeky” types who are capable of recognizing what the expressions imply and optimizing them before handing them to the regular expression engine.
-
@mkupper You are 100% correct, I don’t dispute anything you said. Also, I misspoke in an earlier reply when I said this RE had no backtracking, what I meant to say was that it had no back references. Obviously backtracking is the bread and butter of regular expressions.
The fact is that I started with a much more complicated regular expression and got the error, so I simplified the regular expression, then simplified it again until I got a super simple regular expression, the one I posted, that still caused the error.
However, now I have to admit that the problem was my assumptions. What I didn’t realize was that there was a couple of rogue json files that had come in with a project. These files were 10k and the whole JSON was in one line, no carriage returns at all (which isn’t all that different from the test file you created). Not sure why, maybe they were just generated by some code like that or maybe they were trying for some kind of minification, though I can’t imagine doing without the CRs would make that much difference.
Also, when I said that Visual Studio did it fine, it turns out I was lying. I had started the search and then walked away so I didn’t realize how long it took (though it did eventually finish it took hours because of those giant files, and it used 100% CPU for most of that time, DOH!).
So, in the end the only thing left is a suggestion that the multi-file find shouldn’t fail because it runs into a file that breaks, when all the other files work just fine. Once I removed the heinous one-line JSON files the search completed for my original (complex) RE. Strangely enough I still get the error for “.*employeeId”, so there’s something else that’s tweaking it. However “[^”]*employeeId" works just fine as well as “[^”\r\n]*employeeId".
I think in the end it’s good I came here first rather than reporting it straight to GitHub as the conversation definitely made me take a second look at my assumptions. Thanks guys!
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
@Alan-Kilborn said in Getting "Invalid Regular Expression" for an extremely simple expression:
Maybe put in a feature request to change this wording to something better? Or at least suggest some better wording here?
Hmmm… honestly, I’m not sure there is a good way to word that message — the very existence of the message is the problem. The right way (in my oh-so-humble opinion) to handle this would be to pop up a progress dialog when searches take more than a user-configurable amount of time, and let the user decide when it’s been going on too long and should be canceled.
Doing something like that with the search in Columns++ is on my list of potential future enhancements. I think it might require modifying Boost::regex, though; if it does, I will find that idea rather uncomfortable. If I ever do get it done and working right in my plugin, that could serve as a proof-of-concept for doing it in Notepad++.
Or (considering that the problem @mkupper demonstrated would have been avoided if the regex processing recognized that if a fixed string didn’t match from a given position to the end of a line it couldn’t possibly match from a later position in the line to the end of the same line), maybe we just need a smarter Regex engine. (I have no idea if such a thing exists… oy, another research project!)
Seems like it could fail on one file without failing on the whole batch as well. This is especially annoying if the file it fails on is number 4,000.
-
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
Seems like it could fail on one file without failing on the whole batch as well. This is especially annoying if the file it fails on is number 4,000.
Absolutely. It’s not the expression that fails, it’s the combination of the expression and the data.
By the way, did you ever try either of these expressions on your data:
"[^"\r\n]*employeeId"
"(.*employeeId"|.*(*SKIP)(*FAIL))just to see if they would work to find what you wanted?
-
@Coises said in Getting "Invalid Regular Expression" for an extremely simple expression:
@Scott-Gartner said in Getting "Invalid Regular Expression" for an extremely simple expression:
Seems like it could fail on one file without failing on the whole batch as well. This is especially annoying if the file it fails on is number 4,000.
Absolutely. It’s not the expression that fails, it’s the combination of the expression and the data.
By the way, did you ever try either of these expressions on your data:
"[^"\r\n]*employeeId"
"(.*employeeId"|.*(*SKIP)(*FAIL))just to see if they would work to find what you wanted?
I didn’t try the second, but I did try the first and once I got rid of the heinous json files it works. The “real” RE that I was trying to run (which is much more complex than the one above, which was the simplest I found that produced the error) works as well (I never put that in here because it wasn’t germane to the discussion).
-
Hello, @scott-gartner, @alan-kilborn, @coises, @mkupper, @mark-Olson, @terry-r and All,
I’ve been away for the last few days as we’ve been on a 4-day trip to Burgundy with some friends: hiking trails, visiting monuments, including the ‘must-see’ Hospice de Beaune, and, of course, the local gastronomy !
Interesting and disturbing topic, indeed !
But, before I get into that, let me correct two common mistakes :
First, @scott-gartner said :
Also, I did mention that I had not checked the box for “. matches newline” so the RE should not need the removal of the CRLF. I knew exactly what string I was looking for and that it existed
This assertion is FALSE !
To be convinced of this fact :
-
Open a new tab
-
Type in the following text :
"this is a test to see the scope of the search "this is a test to see the scope of the searchIf you search for the regex
"[^"]*test, even if the. matches newlineoption is not set, you should get two matches :-
The first match in line
1( obvious one ) -
The second match in line
6and7, which includes one CRLF, at the end of line6
This result is due to the regex part
[^"]which matches absolutely all chars but the double quote, and so, including theEOLchars as well !Now, if you use, instead, the regex
"[^"\r\n]*test, you’ll get only one match, in line1
Secondly, @mkupper said :
Surprisingly, it also fails if I try “.*?employeeId” which I though would disable backtracking.
No, adding the
?symbol in order to get a lazy quantifier, instead of the gready one, is not related to the backtracking process. There are two independant things ! My personal idea about it, is that the term bactracking process should be named the retry process !For example :
-
Open a new tab
-
Type in this one-line text :
this is a test to see what happens_with_that_regexAnd let’s use the simple regex
^.+?a\w+$-
At first sight, we could say that the regex letter
a, after the LAZY quantifier, should match the first letteraof the subject string ! -
But, after matching the part
this is a, the regex wait for a word char as next character. this is not the case as it’s aspacechar. -
Thus the process backtracks ( I would say retries ) and increases the number of chars before an other
aletter, till the stringthis is a test to see wha -
The next char is, indeed, a word char ( letter
t), but again the next one is aspacechar -
So, the process backtracks ( I would say retries ) increasing the number of chars for an other
aletter, till the stringthis is a test to see what ha. This time, the remainder of the subject stringppens_with_that_regexis entirely made of word characters -
As a result, the regex
^.+?a\w+$is truly verified against this subject string :
this is a test to see what happens_with_that_regex ^<----------.+?------------->a<--------\w+-------->$To be convinced, simply use the regex S/R, below :
SEARCH
(?x) ^ (.+?) (a) (\w+) $REPLACE
Group 1 = >\1<\r\nGroup 2 = >\2<\r\nGroup 3 = >\3<\r\nGroup 0 = >$0<\r\nto see the different groups involved !
In other words :
-
We are not searching for the closest letter
a, after the string matched by the regex^.+?, but : -
We are searching for the closest expression, matched by the regex
a\w+$, after the string matched by the regex^.+?
If we had used, instead, the regex
^(.+)a\w+$:-
The part
^.+awould have directly matched thethis is a test to see what happens_with_thastring -
And the part
\w+$correctly finds the stringt_regexwhich is an ending block of word chars
Leading to :
this is a test to see what happens_with_that_regex ^<--------------------.+------------------>a<-\w+->$See the difference, with the previous case, by using this regex S/R :
SEARCH
(?x) ^ (.+) (a) (\w+) $REPLACE
Group 1 = >\1<\r\nGroup 2 = >\2<\r\nGroup 3 = >\3<\r\nGroup 0 = >$0<\r\n
An other example with TRUE backtracking process :
If we consider the simple regex
\w+\w{14}\d+, against the subject stringABC12345DEFABC34566677890-
First, of course, the sub-regex
\w+matches all the subject string -
Then, the
\w+backtracks, so decreases, one position at a time, till14positions, in order that the stringABC12345DEFmatches the\w+part and the stringABC34566677890matches the regex part\w{14} -
Finally, the sub-regex
\w+backtracks again by1position, in order that the stringABC12345DEmatches the\w+part, the stringFABC3456667789matches the\w{14}part and the final0matches the\d+part
Again, you may verify, the results with the regex S/R :
SEARCH
(?x) (\w+) (\w{14}) ( \d+)REPLACE
Group 1 = >\1<\r\nGroup 2 = >\2<\r\nGroup 3 = >\3<\r\nGroup 0 = >$0<\r\n
Now, let’s go back to our main problem !
From the @mkupper’s file, that I downloaded, I tried to simplify the problem. Thus, I used this text :
".*employeeId" See https://community.notepad-plus-plus.org/topic/25868/getting-invalid-regular-expression-for-an-extremely-simple-expression/ "abcdefghijklmnopqrstuvwxyz"abcdefghijklmnopqrstuvwxyz"abcdefghijklmnopqrstuvwxyz.........."abcdefghijklmnopqrstuvwxyz"abcdefghijklmnopqrstuvwxyzAs you can see, the first five lines are identical to the @mkupper’s text :
-
A first empty line
-
The second line, matched by the
".*employeeId"regex -
A third empty line
-
A fourth line with the link
-
A fifth empty line
-
Finally, a sixth line containing the string
"abcdefghijklmnopqrstuvwxyz, repeated exactly2,672times, without any line-break -
Save this file with name
Text_OK.txt
Note : the
Test_OK.txtfile should have a size of72,294bytes-
Now, select all the file contents
-
Copy it in the clipboard
-
Open a new tab
-
Paste the clipboard contents
-
Add an unique string
"abcdefghijklmnopqrstuvwxyzat the very end of file -
Save it with name
Test_KO.txt
This time, the
Test_KO.txtshould have a size of72321bytes ( the sum72,294 + 27)
Regarding the search process, itself :
-
Move to the very first line of each file
-
Open the Find dialog (
Ctrl + F) -
Uncheck all the box options
-
SEARCH
".*employeeId" -
Select the
Regular expressionsearch mode -
Click two times on the
Find Nextbutton
Note that I first did the tests on my old
Win XP - 32 bitslaptop, with just1 Gbof RAM, and N++ portablev7.9.2-
With a sixth line containing exactly
2,672times the string"abcdefghijklmnopqrstuvwxyz( fileTest_OK.txt), the regex search".*employeeId"detects the unique match, in line2then displays the messageFind: Can't find the text "".*employeeId""=> Results OK -
With a sixth line containing exactly
2,673times the string"abcdefghijklmnopqrstuvwxyz( fileTest_KO.txt), the regex search".*employeeId"detects the unique match, in line2, then wrongly finds all the file contents !
Remember that, before N++
v.8.0, when explanations on regex syntax were absent, in the search dialog, it was the normal way for the regex engine to display a possible regex problem !!
Then, using my recent
Win 10 - 64 bitslaptop, with32 Gbof RAM and N++ portablev8.6.5, I did the same tests. I initially thought that the limit between the two cases would be much higther, given the capacities of my new laptop, but the most extraordinary thing is that I got exactly the same limit, namely :-
With a sixth line containing exactly
2,672times the string"abcdefghijklmnopqrstuvwxyz( fileTest_OK.txt), the regex search".*employeeId"detects the unique match, in line2, then the messageFind: Can't find the text "".*employeeId"" from caret to end-of-file=> Results OK -
With a sixth line containing exactly
2,673times the string"abcdefghijklmnopqrstuvwxyz( fileTest_KO.txt), the regex search".*employeeId"detects the unique match, in line2, then writes the messageFind invalid Regular Expressionand the error message said
The complexity of matching the regular expression ... ... that takes an indefinite period of time to locate
I also tested this regex against the same files with the
SciTEsoftware ofSCIntilla, downloading theSingle file 64-bits executablenamed Sc550.exe. Unlike with Notepad++,SciTEdoes not find any wrong second match !So, as a conclusion, I think that it seems to be a real bug. However, I can’t decide if it’s a Boost regex’s bug or a N++ bug in the way to use the
Boost regexengine !Best Regards,
guy038
Could someone repeat my tests, with recent N++ version and confirm my assumptions regarding the
Test_OK.txtandText_KO.txtfiles, which differ of27characters only !! -
-
 G guy038 referenced this topic on
G guy038 referenced this topic on
-
@guy038 said in Getting "Invalid Regular Expression" for an extremely simple expression:
Could someone repeat my tests, with recent N++ version and confirm my assumptions regarding the Test_OK.txt and Text_KO.txt files, which differ of 27 characters only !!
I can replicate these results on a no-plugin version of my 64-bit Notepad++ clone (which was between 8.6.7 and 8.6.8 at the time I ran your tests). So it sounds like this bug is real and still exists.
-
@guy038 said in Getting "Invalid Regular Expression" for an extremely simple expression:
First, @scott-gartner said :
Also, I did mention that I had not checked the box for “. matches newline” so the RE should not need the removal of the CRLF. I knew exactly what string I was looking for and that it existed
This assertion is FALSE !
Guy, be careful. He made that assertion with regards to the original regex he showed us:
".*employeeId"– you then tested the assertion using a completely different regex:"[^"]*test. The.*that he was talking about is wholly different than the[^"]*that you tested. With the test textthis "has employeeId" in a single line this "does not have employeeId" on the same line as the start quote so the second will not match the third "employeeId" will match as wellUsing the original
".*employeeId"does not stretch the match over multiple lines, as expected (see below) when. matches newlinesis checked. Using the equivalent of your test,"[^"]*employeeId", of course it will spread across multiple lines, because the manual character class is not the same as the.*that he made the assertion about, and has no.for. matches newlineto influence.".*employeeId"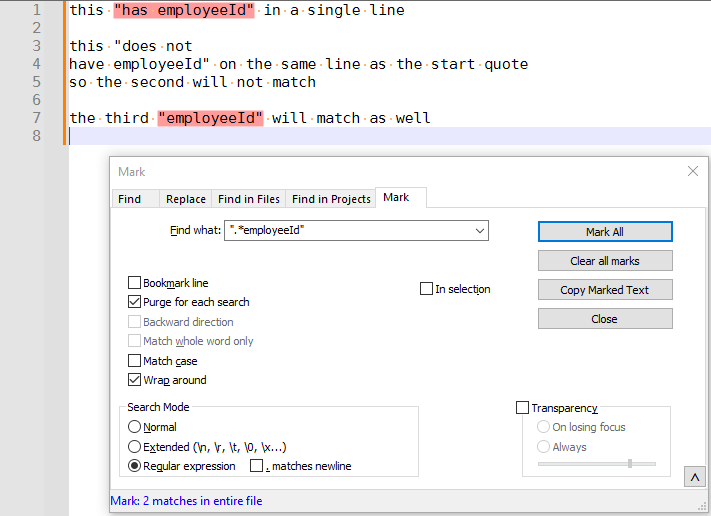
"[^"]*employeeId"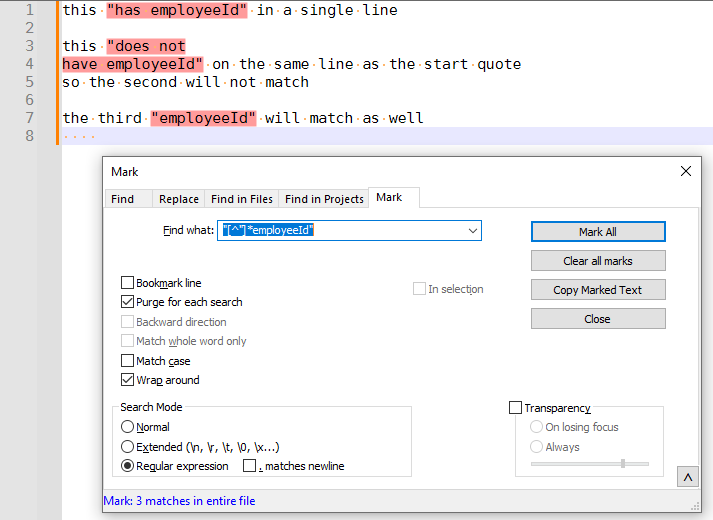
-
Hello, @scott-gartner, @peterjones and All,
Oh…, yes, Peter, you’re right about it ! So, @scott-gartner, I’m sorry for misinterpreting your statement !
Best regards,
guy038