Highlighting with self created words in "langs.xml" does not work
-
Thanks a lot for your detailed answer :-)
I’ll try both, EnhanceAnyLexer for a short-term solution and an inquiry to the Lexilla team to enhance the HTML lexer.
-
Update: Asked the Lexilla community now. Check this:
https://github.com/ScintillaOrg/lexilla/issues/260
[ I’m still not allowed to post links -> please remove () in the URL ]
–
moderator fixed link -
I’m still not allowed to post links
I fixed your link, and you’ve now been upvoted enough that you will be able to post links in the future.
Asked the Lexilla community
I appreciate the level of detail in your feature-request. Hopefully they’ll pay attention. (I’m adding a comment to give more reasons as to why it’s useful.)
-
in the GH issue, you commented,
I have to admit, that I cannot contribute to this discussion… ;-)
I was able to glean enough from the official answer there that I’ll be able to start experimenting with the “substyle” feature of Lexilla, as I have time. The PythonScript plugin has the methods necessary to call the substyle commands, so I’ll play around with it. However, with one-sentence documentation, and the example buried in their SciTE source code, it will take me a while to wrap my head around it, and then even more time before I have a useful implementation to share.
-
I appreciate your efforts here very much. Thank you very much for that 👍
For now, until a Notepad++ native solution using substyles is available, I’m happy with the EnhanceAnyLexer plugin. Once a solution is implemented, do I see it here or by thoroughly reading the Notepad++ release notes?
-
@Manfred-Drechsel said in Highlighting with self created words in "langs.xml" does not work:
do I see it here
The very first thing to do is watch the Lexilla issue for it. If a Lexilla code change from it is integrated into Lexilla, things are “on their way”. If not, the whole thing is dead.
-
watch the Lexilla issue for it.
Actually, Lexilla’s answer was, essentially, that we should use the existing “substyle” feature, which is available on the PHP lexer (well, really the HTML lexer, which handles PHP).
I’ve already got a proof-of-concept version of a PythonScript implementation, and will be cleaning it up to be able to be a script that can be run from
startup.pyand automatically apply the keyword lists to substyles (similar to the original PythonScript version of EnhanceAnyLexer).do I see it here or by thoroughly reading the Notepad++ release notes?
I’d say “watch here”. Once I have my cleaned-up version ready for public usage, I’ll link it here.
(And because it uses so much of the same backend logic as EnhanceAnyLexer, in the long term, I’m thinking of seeing if I can figure out how to use V and see if I can put in a PR to have @Ekopalypse add it to his existing plugin, because I think it will fit naturally there… though I’m not yet sure if what I think matches reality 😉. Or whether I can figure out enough to hack in some V code. )
-
I said,
Once I have my cleaned-up version ready for public usage, I’ll link it here.
I’ve got it as good as it’s likely to get for now.
You can grab the most recent version of the script from this github location
This script requires the PythonScript plugin. It has been verified as working on both PythonScript 2 (available through the Plugins Admin) or PythonScript 3 (you can grab the most recent v3.0.xx pre-release here; you need to grab at least 3.0.18 or newer).
See the instructions in FAQ: How to install and run a script in PythonScript for how to install and run the plugin and script.As mentioned in that FAQ, this is one of the scripts that you can run from
startup.py. Assuming you name the script’s fileSubStylesForLexer.pylike the file is called in my GitHub repo link above, then you can add the following line to yourstartup.pyto have it automatically run whenever you run Notepad++:import SubStylesForLexerDetails
As far as I can tell from my research, as of Scintilla 5.5.1 / Notepad++ v8.6.9, there are only a handful of languages in the Lexilla bundle that allow substyling, and those have specific styles that allow substyles. These include (among others), C/C++/C# and HTML/XML/PHP (see the comments near the top of the script for the complete list that it supports)
Since there are only a small list, my script has everything needed (except for your choice of foreground and background colors, and your list of keywords for each color) for each of those languages and the styles that allow substyles.
Essentially, this script checks the active file, and if it’s one of the filetypes supported. If so, it will enable the substyles based on the list and colors defined in the script.
You will need to edit the script for the language(s) you care about. For my example, since this discussion was started with PHP, I will use PHP as the example, but the ideas are the same for the other languages:
- Edit the
SubStylesForLexer.pyscript - Go to the
class PHP_SubstyleLexerdefinition in the script - Scroll down to the lines starting with
INSTRUCTIONSin thedef colorize(self):for that class - Since you care about PHP, you will want one or more list for
SCE_HPHP_WORD.- You can tell that
SCE_HPHP_WORDis the style you want, because a few lines above, you can see thatSCE_HPHP_WORD = 121, and you know fromstylers.xml(or your theme’s XML) that theWORDstyle (the PHP style with the keyword list) hasstyleID="121". - So if you were picking a different language, you would want to make sure to focus on the
SCE_xxxthat has the same value as your language’s styleID.
- You can tell that
- For this example, assume you have two lists of keywords
wordx wordy wordzwhich you want as RED (255,0,0) on YELLOW (255,255,0)anotherx anothery anotherzwhich you want as DARK BLUE (0,0,127) on GREY (127,127,127)
- to implement those two examples, change the line
into the following two linesself._style[SCE_HPHP_WORD].append(dict(fg=(0,0,255), bg=(255,255,0), keywords="pryrt"))
… and saveself._style[SCE_HPHP_WORD].append(dict(fg=(255,0,0), bg=(255,255,0), keywords="wordx wordy wordz")) self._style[SCE_HPHP_WORD].append(dict(fg=(0,0,127), bg=(127,127,127), keywords="anotherx anothery anotherz")) - if any of those words are currently in the
stylers.xmlor theme’s list, you will have to editstylers.xmlor that theme’s XML to remove the overlapping words. After editing a config file, you will have to restart - once you’ve run the script (or if you’ve included it in
startup.py, once you’ve restarted Notepad++), the script will automatically add the colors you define for your specific list of keywords
Example / Test Case
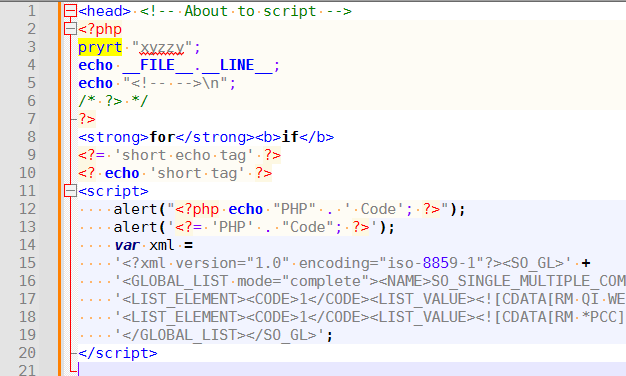
Before editing your copy of the script for your list of words, I highly recommend using the following PHP file as a test to make sure it’s set up correctly: save this PHP to
example.php, run the script, and then toggle openexample.php: it should show the wordpryrtnear the top as blue-foreground-on-yellow-background.example.php:<head> <!-- About to script --> <?php pryrt "xyzzy"; echo __FILE__.__LINE__; echo "<!-- -->\n"; /* ?> */ ?> <strong>for</strong><b>if</b> <?= 'short echo tag' ?> <? echo 'short tag' ?> <script> alert("<?php echo "PHP" . ' Code'; ?>"); alert('<?= 'PHP' . "Code"; ?>'); var xml = '<?xml version="1.0" encoding="iso-8859-1"?><SO_GL>' + '<GLOBAL_LIST mode="complete"><NAME>SO_SINGLE_MULTIPLE_COMMAND_BUILDER</NAME>' + '<LIST_ELEMENT><CODE>1</CODE><LIST_VALUE><![CDATA[RM QI WEB BOOKING]]></LIST_VALUE></LIST_ELEMENT>' + '<LIST_ELEMENT><CODE>1</CODE><LIST_VALUE><![CDATA[RM *PCC]]></LIST_VALUE></LIST_ELEMENT>' + '</GLOBAL_LIST></SO_GL>'; </script>screenshot with the script working (shows highlighting of
pryrtpsuedo-keyword):
- Edit the
-
Great! :-)
I’ll try that the next days. Pretty busy currently…
But before that, some questions if I got it right (major steps only):
- I install PythonScript and change startup.py (add
import SubStylesForLexer) - I add some
self._style[SCE_HPHP_WORD].appendcommands to SubStylesForLexer.py (and remove words in langs.xml / stylers.xml) - use it
I saw that the callback used is
on_bufferactivated. Does this mean the colorize is at file open? Not while editing?Since it’s (not yet?) a native Notepad++ solution, what would you think is the advantage over installing EnhanceAnyLexer and editing EnhanceAnyLexerConfig.ini ?
Many thanks for your efforts in this case :-)
- I install PythonScript and change startup.py (add
-
@Manfred-Drechsel said in Highlighting with self created words in "langs.xml" does not work:
- I install PythonScript and change startup.py (add
import SubStylesForLexer) - I add some
self._style[SCE_HPHP_WORD].appendcommands to SubStylesForLexer.py (and remove words in langs.xml / stylers.xml) - use it
Those are the right steps
I saw that the callback used is
on_bufferactivated. Does this mean the colorize is at file open? Not while editing?No, while you stay in the editor and are editing, the coloring will happen live. So if you added a second instance of
pryrtin my example, it would immediately show up as colorized.When notepad++ opens a file, behind the scenes, it does the various scintilla calls, including setting up the keyword lists (because the file type might be different, and there’s only a scintilla-instance per VIEW, not a scintilla-instance per FILE/tab). My implementation essentially populates the new substyle keywords at this same time. Once the style keywords and substyle keywords have been populated, Scintilla/Lexilla will continue to use those settings as long as you don’t change tabs.
Since it’s (not yet?) a native Notepad++ solution,
No one has put in a feature request with Notepad++ to implement these substyles. Until someone does, it’s guaranteed to never be implemented in core Notepad++. Given that it can be done using plugins or scripting, it’s doubtful that the dev would see much point in implementing it, even if they did get a feature request.
what would you think is the advantage over installing EnhanceAnyLexer and editing EnhanceAnyLexerConfig.ini ?
In general, the active lexer will always parse the text (or portion of the text) once for every change made in the document, for doing live syntax highlighting; using the substyles for a given lexer will be done at the same time. (My script just gives Scintilla/Lexilla the list of keywords and what colors to use for those keywords, but Scintilla/Lexilla is what handles actually doing the colorizing, not my script; naming the function
colorizewas probably a bad naming scheme in my script).For the current EnhanceAnyLexer (“EAH”), if I understand it correctly, what happens is that after Scintilla/Lexilla has done its style/substyle pass, then EAH will run a regex on the text (I think it limits to visible text, rather than whole document for efficiency; I might be wrong), and then will ask Scintilla to add colors using Scintilla Indicators – but it basically requires a second pass through the text to apply the colors.
Because the EAH regex requires a second pass through the text compared to using substyles, I think substyles will be technically faster (though I don’t know how much faster).
Long term: if I can put my substyle
on_bufferactivatedcommands into a plugin (whether it my own, or adding it into EAH), then it can make the setup every time a new tab/file is activated faster, and it would allow EAH to activate substyle-based styling without having to do a regex parse to check the list of words in regex – that would then leave EAH to do just the complicated matches that can only be done with regex, rather than spending time also using a regex to find a list of keywords. - I install PythonScript and change startup.py (add
-
Wow, that sounds good!
Even that EAH works, it’s - as I wrote - sluggish, as the in there defined PHP constant keywords are ~34 KB. The language construct keywords are only ~700 bytes. The function keywords (defined in NPP’s
langs.xml) are ~17 KB.And when the colorizing in the end is natively done by Scintilla/Lexilla, that’s great news 😁
-
@PeterJones said in Highlighting with self created words in "langs.xml" does not work:
EnhanceAnyLexer (“EAH”)
It was just pointed out to me how glaring that was. I meant to type “EAL”, obviously. But even better, the badcronym lasted through the entire post (and into a reply). Sorry. :-)
-
Classic repeating without thinking from my side 😂
-
Your understanding of how the current version of EnhanceAnyLexer works is correct :-)
If you need help getting started with V, let me know. There are some hurdles that are not so obvious. Either message me or open an issue on github.
As for substyles for existing lexers, hmm … without having given it much thought, I assume it can be added. Basically we just need some additional styles and their configuration and apply them when activating the buffer.
Should be doable. -
I said earlier,
No one has put in a feature request with Notepad++ to implement these substyles. Until someone does, it’s guaranteed to never be implemented in core Notepad++.
I actually just put in the feature request for the main app.
The more I thought about it, the more I thought it would work best in the main app, where the keyword list and color definitions could all go in the Style Configurator, alongside the normal keyword lists. I think I’ve figured out the places I’d need to edit, and I’ve offered to do the work and put in the PR, if Don gives his stamp of approval on the general concept.
If he rejects the concept, I’ll start exploring other options.
-
Tried now the PythonScript solution. Could not really reliable get it working.
First, it did not colorize on startup of NPP. Accidentally, I found out, that it starts colorizing if I open the PythonScript console. Output by the way is below. Solution after some looking around was to change the initialization type from “LAZY” (default after installation) to “ATSTARTUP”.
Second, trying with an arbitrary PHP keyword (here CURLOPT_STDERR) does not work. No clue why.
This is the relevant part of
SubStylesForLexer.py:self._style[SCE_HPHP_WORD].append(dict(fg=(0,135,68), bg=(255,255,255), keywords="pryrt_a")) self._style[SCE_HPHP_WORD].append(dict(fg=(0,0,255), bg=(255,255,0), keywords="pryrt_b")) self._style[SCE_HPHP_WORD].append(dict(fg=(0,135,68), bg=(255,255,255), keywords="CURLOPT_STDERR"))This is my test PHP script (results see comments):
<?php pryrt_a "xyzzy"; # works as expected :-) pryrt_b "xyzzy"; # works as expected :-) $test = CURLOPT_STDERR; # does not colorize :-\ ?>What am I doing wrong?
However, if the feature would be implemented nativ in NPP, that would be much better :-)
Placed my 👍 already at GitHub :-)–
Just for information, the PythonScript console output:Initialized SubstyleLexerInterface Python 2.7.18 (v2.7.18:8d21aa21f2, Apr 20 2020, 13:25:05) [MSC v.1500 64 bit (AMD64)] Initialisation took 15ms Ready. -
First, it did not colorize on startup of NPP. Accidentally, I found out, that it starts colorizing if I open the PythonScript console. Output by the way is below. Solution after some looking around was to change the initialization type from “LAZY” (default after installation) to “ATSTARTUP”.
That was explained in the FAQ: How to install and run a script in PythonScript I linked you to originally, in the instructions for how to get it to run automatically. I am sorry you didn’t notice that.
Second, trying with an arbitrary PHP keyword (here CURLOPT_STDERR) does not work. No clue why.
This is the relevant part of
SubStylesForLexer.py:self._style[SCE_HPHP_WORD].append(dict(fg=(0,135,68), bg=(255,255,255), keywords="pryrt_a")) self._style[SCE_HPHP_WORD].append(dict(fg=(0,0,255), bg=(255,255,0), keywords="pryrt_b")) self._style[SCE_HPHP_WORD].append(dict(fg=(0,135,68), bg=(255,255,255), keywords="CURLOPT_STDERR"))What am I doing wrong?
Apparently, the lexer used for PHP requires all the keywords to be in lowercase. To make it work, just change the case of your keyword to lowercase. (This makes it match the case it was before you removed
curlopt_stderrfrom the list instylers.xml, too):self._style[SCE_HPHP_WORD].append(dict(fg=(0,135,68), bg=(255,255,255), keywords="curlopt_stderr"))
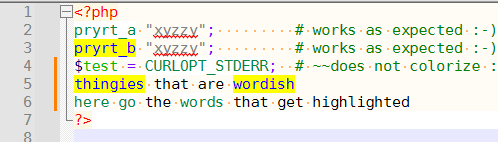
But as a second note: I noticed that you did two different
.append()calls for the same color. Each.append()creates a new list. The intention, if you have multiple words you want the same color, is to have multiple words in the string for the same.append(), like:self._style[SCE_HPHP_WORD].append(dict(fg=(0,135,68), bg=(255,255,255), keywords="pryrt_a curlopt_stderr more words go here")) self._style[SCE_HPHP_WORD].append(dict(fg=(0,0,255), bg=(255,255,0), keywords="pryrt_b and other secondcolor wordish thingies"))Here’s a screenshot showing various words from those multi-word lists highlighted, proving it only needs
However, if the feature would be implemented nativ in NPP, that would be much better :-)
That will take a while, since I’ll just be working on it in my free time. Like you, I am not paid to develop the Notepad++ application. In fact, until this year, I had never contributed any actual code to the codebase (though I had done a couple of XML config default updates over the years, and I am heavily involved in the Notepad++ documentation). But as a code-contributor, I’m a newbie to this project, and the Notepad++ codebase is a large, complicated critter to navigate.
Depending on how long it takes me, it might not even be done in before the next release. But I will work on it as I have time, and I will report back here when/if the PR gets merged – after that happens, it will be the version after that announcement that it makes it into the Notepad++ application.
Apparently, I’ll have to pay attention to which lexers require the keyword lists to be in lowercase, and either document that well, or have my code fix the case for those lexers. So thanks for that heads-up.
-
if the feature would be implemented native in NPP, that would be much better
Actually, the end result would be the same.
You’re probably just saying that because the script setup takes you outside your comfort zone.
You’re lucky that the author of Notepad++ has agreed to accept changes to have it be native; this often does not happen, and add-on scripts to add features or change functionality are all one has. -
@PeterJones
Can confirm now, that for me the PythonScript solution fully works. I added 1963 constant and 103 language construct keywords and special vars to SubStylesForLexer. py with different colors and all lowercase. The 1270 function keywords still are in the NPP definitions (langs.xml and stylers.xml). >Thanks a lot for your great job!<So I will uninstall the EAL plugin now and stay with substyles.
@Alan-Kilborn
No, I do not have a “need native solution” comfort zone. My only argument to have a NPP solution was performance. Nothing else. I never had and have a problem with script setups or similar. -
@Manfred-Drechsel said in Highlighting with self created words in "langs.xml" does not work:
for me the PythonScript solution fully works.
Glad to hear it. (For future readers of this discussion, I have updated the downloadable script to make the ATSTARTUP more obvious (it’s now in the comments near the top of the script, not just in the instructions-FAQ)
My only argument to have a NPP solution was performance. I never had and have a problem with script setups or similar
If you haven’t had performance problems with other scripts, you likely won’t with this one, either.
The only time the script comes into play is when you change from one document to another (the
on_bufferactivated) – and that’s a brief number of commands that shouldn’t take a noticeable amount of time. (There might technically be a difference, but with how few commands it is, it would be on the order of a tiny fraction of a second of difference.)Once the
on_bufferactivatedhas been run, Scintilla will do the actual lexing and syntax highlighting using the code compiled into Notepad++, whether theon_bufferactivatedstuff was run from a script or from native Notepad++, so the syntax highlighting will not have any performance difference.