How to group lines with same beginning
-
Hello!
I would like to know if it’s possible to group several lines that share the same beginning up to a certain mark into just one line.My file is like this:
aaaa$$$$$$hello1 aaaa$$$$hello2 aaaa$$$$hello3 bbbb$$$$$$$$hello4 bbbb$$$$hello5 cccc$$$$hello6 cccc$$$$hello7 cccc$$$$hello8*aaaa, bbbb, cccc and hello1…hello8 are just examples, not the real text in my document.
So, I would like to know how to group easily, maybe with a macro or a built-in feature in Notepad, these lines that share the same beginning (aaaa, bbbb, cccc) up to the mark $, resulting into:
aaaa$$$$$$hello1 / hello2 / hello3 bbbb$$$$$$$$hello4 / hello5 cccc$$$$hello6 / hello7 / hello8Thinking of macros, I know how to record a simple macro, but I don’t know how to create a macro that basically goes through all the lines in the document from top to bottom and groups them with a function “If beginning of the line until you find a $ is the same as the beginning of the previous line, group this line with the previous one”.
Could you please help me to do this?
Thank you very much in advance.
-–
moderator added code markdown around text; please don’t forget to use the
</>button to mark example text as “code” so that characters don’t get changed by the forum -
Your problem seems very similar to this one: https://community.notepad-plus-plus.org/topic/26062/eliminate-excess-verbiage-from-audio-transcript
Maybe you can figure out how to do what you want, based on the solution of that other one.
-
The following sequence of regex-replace should do the trick.
Open the find/replace form with
Search->Replace...or Ctrl+H (using default keybindings).Make sure
Search Modeis set toRegular expressionandWrap aroundis checked.- Mark the first line in each series of lines with the same start using the following replacement:
- Find what:
(?-s)^([^\$\r\n]*)(.*\R)(?:\1(.*)(?:\R|\z))* - Replace with:
\x07${0}
- Find what:
- Convert your document into the desired final form (shown below)
- Find what:
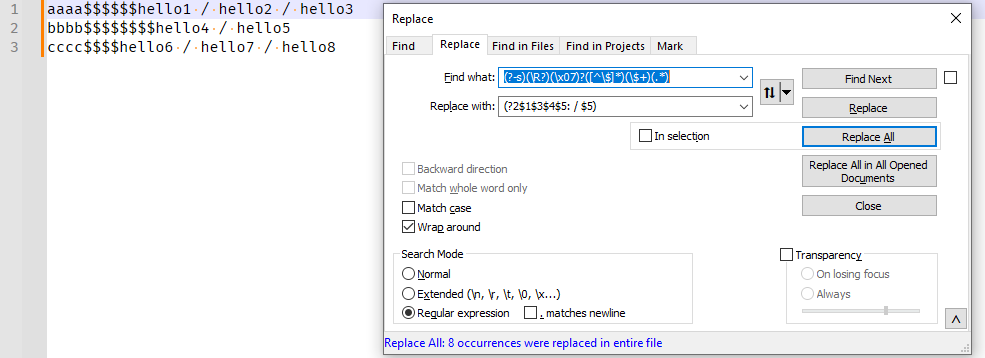
(?-s)(\R?)(\x07)?([^\$]*)(\$+)(.*) - Replace with:
(?2$1$3$4$5: / $5)
- Find what:
Result:
aaaa$$$$$$hello1 / hello2 / hello3 bbbb$$$$$$$$hello4 / hello5 cccc$$$$hello6 / hello7 / hello8The first and second regular expressions can be tweaked a fair amount to solve similar problems to this one.
- Mark the first line in each series of lines with the same start using the following replacement:
-
I wanted to see if someone could learn to fish.
Apparently you just wanted to feed them for today.
:-) -
Thank you so much, Mark, for your reply! :)
I’m very sorry I couldn’t reply sooner. Due to several issues, I haven’t been able to. I apologize for it.
Anyway, I really appreciate your help. I’ve tried to follow the steps you indicate, but at point 1, after making sure that Search Mode is set to Regular expression and Wrap around is checked, when I try to do the replacement (I’ve tried to do it both by clicking “Replace All” and “Replace”), Notepad throws error message ‘Find: Invalid regular expression’.
What do you think we could change in the expression of that first Find what?
-
Thank you for the link, but although the question in there may be somewhat similar, I would prefer to learn through my own one, if possible, which is the one that matches exactly with my needs.
You could consider this a fish of courtesy, and later, if I feel like eating similar fishes like this one, don’t worry I will do my best to catch them by myself. :)
-
It’s so similar to the other one that you missed a golden opportunity to learn something. And since you were spoon fed, I’m confident you won’t be doing any learning.
-
@Nataly-Flower said in How to group lines with same beginning:
after making sure that Search Mode is set to Regular expression and Wrap around is checked, when I try to do the replacement (I’ve tried to do it both by clicking “Replace All” and “Replace”), Notepad throws error message ‘Find: Invalid regular expression’.
Then you have done something wrong, because when I copy @Mark-Olson’s first regex, and use it on your data, it works perfectly, without giving an error:
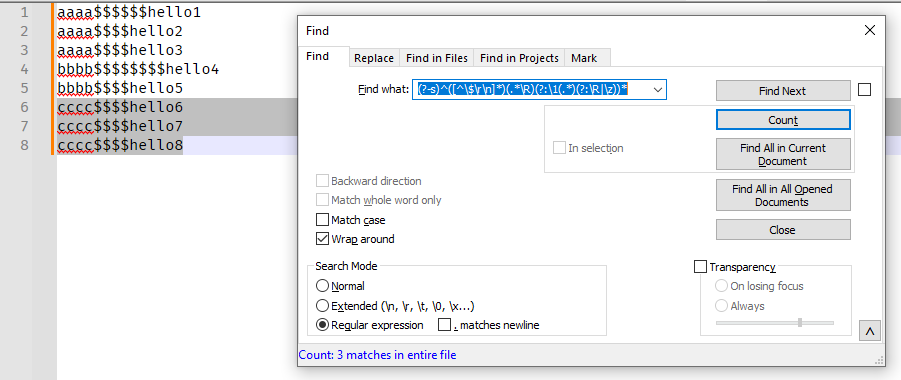
So does the second:
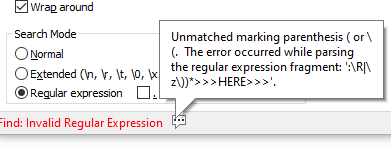
We cannot begin to guess what you did wrong, because you shared nothing about the error message: If you hover over the little popout-icon in the
Find: Invalid Regular Expressionmessage, it will tell you exactly what’s wrong with your regex. Here’s one where I intentionally edited the regex to be invalid
Hmm, I said you had done something wrong… but another question might be: how big is your file? And how many lines in a row might match with the exact same prefix? Because there is a limit to how many bytes can fit inside a capture group in a regex. So if you have lines that are thousands of characters wide, or have thousands of the
aaaa-prefixed lines, it might be enough to overwhelm the regex engine. If it gets too big, it can come back with anInvalid Regular Expressionmessage, even though it’s really an “invalid size” problem. But you haven’t given us enough to be sure. -
Thank you very much for your assistance. I appreciate it a lot. :)
I must say you have given me the key to realize what was happening. I was not really doing anything wrong, nor there is anything wrong with the regex formulated above by @Mark-Olson, whom I also thank for his help once again.
When you asked about the size of my file, I tried to perform the replacements in the original file and indeed it gives an error, and hovering the mouse over the little icon you said, I could see the following message: ‘Ran out of stack space trying to match the regular expression’. I must say it is noticeable here that I am still a novice in the use of Notepad++, because I didn’t know that a message could be seen in that icon, I thought it was an icon accompanying the Find: Invalid Regular Expression message.
Therefore, I have tried again the replacements this time on a smaller version of the file, and this time they have worked perfectly, without problems. It was a question of file size.
Having said this, I would like to thank you once again for helping me. Thank you so much.
-
Fortunately, this problem can still be solved with regular expressions, because the regex engines used by most scripting languages (including Python and C#) are not susceptible to the same match length limit that Notepad++ suffers from.
Here’s a PythonScript script that would solve the problem. I’ve tested it with documents that have as many as 400000 consecutive lines that all have the same beginning before the first
$character. And before someone complains that this is basically just a couple of simple PythonScript commands wrapped around a pure Python script, I’m aware of that and I just wanted to post this anyway.By the way, this highlights a general pattern: if you are dissatisfied with the performance of Notepad++'s native find/replace form, try using
re.subto do the same find/replace operation in PythonScript, and you will likely see a massive performance improvement.''' ====== SOURCE ====== Requires PythonScript (https://github.com/bruderstein/PythonScript/releases) Based on this question: https://community.notepad-plus-plus.org/post/96456 ====== DESCRIPTION ====== The goal of this script is to replace a document of the form """ aaaa$$$$$$hello1 aaaa$$$$hello2 aaaa$$$$hello3 bbbb$$$$$$$$hello4 bbbb$$$$hello5 cccc$$$$hello6 cccc$$$$hello7 cccc$$$$hello8 """ with """ aaaa$$$$$$hello1 / hello2 / hello3 bbbb$$$$$$$$hello4 / hello5 cccc$$$$hello6 / hello7 / hello8 """ In the words of the original poster, "So, I would like to know how to group easily, maybe with a macro or a built-in feature in Notepad, these lines that share the same beginning (aaaa, bbbb, cccc) up to the mark $" ====== EXAMPLE ====== See above. ''' from Npp import editor import re # You could add a bunch of text that matches the problem with the below: # editor.setText('\r\n'.join(('%s$$$$hello%d' % (x * 4, ii)) for x in 'abcdefghijklm' for ii in range(400_000))) oldText = editor.getText() # Use BEL to mark the first line in each series of lines with the same start FIRST_REX = r'(?m)^([^$\r\n]*)([^\r\n]*(?:\r?\n|\r))((?:\1(?:[^\r\n]*)(?:\r?\n|\r)?)*)' # print('======= DOING FIRST REPLACEMENTS ======') def replacer1(m): # print(m.groups()) return '\x07' + m.group(0) newText1 = re.sub(FIRST_REX, replacer1, oldText) # Convert your document into the desired final form # print('======= DOING SECOND REPLACEMENTS ======') def replacer2(m): grps = m.groups() # print(grps) return ('%s%s%s%s' % (grps[0], grps[2], grps[3], grps[4])) if grps[1] else (' / ' + grps[4]) newText2 = re.sub(r'((?:\r?\n|\r)?)(\x07)?([^$\r\n]*)(\$+)([^\r\n]*)', replacer2, newText1) editor.setText(newText2)EDIT: The regex search form in JsonTools can also achieve this task much faster than Notepad++, but still noticeably slower than PythonScript. The main advantage of the regex search form is that, when using the
s_fafunction, it provides a tree view making it easy to see all the capture groups of each regex search result.I have not tested other plugins like ColumnsPlusPlus or MultiReplace for this task, but in my experience neither of those plugins comes anywhere close to the raw performance of Python’s
re.subwhen the number of replacements is very large. -
@Mark-Olson said:
And before someone complains that this is basically just a couple of simple PythonScript commands wrapped around a pure Python script
It’s no problem. In fact, it’s totally appropriate. :-)
Just to point out:
Python’s
reuses a different engine than Notepad++ does. While this can be a “good thing”, sometimes it will trip a user up – they’ll get a “tricky” regular expression working in Notepad++, and then run into trouble when trying to automate using the same expression in a script. I’m not saying anything like that would happen with the specific problem of this thread…it’s just something to be aware of. -
@Alan-Kilborn said in How to group lines with same beginning:
Python’s re uses a different engine than Notepad++ does. While this can be a “good thing”, sometimes it will trip a user up – they’ll get a “tricky” regular expression working in Notepad++, and then run into trouble when trying to automate using the same expression in a script.
This does in fact happen in multiple places in my script. I’ll just break down how the regular expressions I used had to change to be compatible with Python’s
reengine.STEP 1 REGEX CHANGES
(?-s)^([^\$\r\n]*)(.*\R)(?:\1(.*)(?:\R|\z))*
becomes
(?m)^([^$\r\n]*)([^\r\n]*(?:\r?\n|\r))((?:\1(?:[^\r\n]*)(?:\r?\n|\r)?)*)(?-s)is unnecessary (because.already does not match newline by default inre)(?m)is necessary to make it so that^matches at the beginning of the file and at the beginning of lines. In Notepad++ regex,^matches the beginning of lines by default.- Every instance of
.must become[^\r\n]because in Python.matches\r, which is bad because that is the first character of the\r\nsequence that indicates a newline in Windows. - Every instance of
\R(shorthand for any newline) must become(?:\r?\n|\r), which matches the three most common newlines (\n,\r\n, and\r)
The Step 2 regex also needs to be changed from
(?-s)(\R?)(\x07)?([^\$]*)(\$+)(.*)to((?:\r?\n|\r)?)(\x07)?([^$\r\n]*)(\$+)([^\r\n]*)because of point 3 above (the lack of\Rin Python’sre)Finally, I had to create callback functions (the
def replacer1(m):anddef replacer2(m)) above, because the replacement regexes I used in Notepad++ don’t work in Python.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login