Remove data lines with same value in certain column
-
Hello,
I have a very large dataset with over 10 million lines of data.
The data format is shown in screenshot below

I have more than 400,000 set of these data line by line in this text dataset file. The first 4 lines in the example are like headers and the data I want to clean up starts with 1461 302; 1826 302, etc. In the second column, values start with 302, then change to 287.13, then return back to 302. Different small dataset have different values. But the pattern is the same.
I want to remove the lines where the second column value are the same before it changes to a different value. And I want to keep the last row of data before second column value changes.
So my desired data format will be as below:

I successfully did this operation last year using Notepad++ but forgot how I did it. What I remember was I used the Search/Replace function and Line Operation and Bookmark function to first select all the rows I want to delete, then delete them.
Please help me with this issue. Very much appreciated!
-
I’m a bit confused. In the example you gave, the desired results you showed don’t match the description you gave. Were the actual desired results:
#391393 ! Node 990292 Mine Year2Ø33 ! [type—Linear ; option—linear ; timeunit=d ; unitc1ass=CARDINAL; userunit=] 748 302 8765 287.13 13879 302 ENDIf so, you can do that by selecting Search | Replace… from the menu, entering:
Find what:
^\d+ ([\d.]+)\R(?:\d+ \1\R)*(\d+) \1$
Replace with:\2 \1
Wrap around checked
Search Mode: Regular expressionand clicking Replace All.
This assumes that, as in your example data, the first column is all integers but the second column can have decimals.
-
Hi, thank you so much for your quick reply.
Sorry my description is off and hard to understand. But the desired data format in the second screenshot is correct.
Hopefully picture below can clarify my question better:


I want to delete the rows circled in red and keep the rest.
Thank you!!!
-
I feel like I might still be missing something.
Are you saying that you only want to delete the lines with duplicate second values in the first group that follows a line with only the letters GAP in it?
If that’s the case, then try changing my suggestion to:
Find what:
^GAP\R\d+ ([\d.]+)\R(?:\d+ \1\R)*(\d+) \1$
Replace with:GAP\r\n\2 \1I’m assuming you want to replace this more than once (or you’d just do it by hand) — either it occurs multiple times in one file, or one time in multiple files, or multiple times in multiple files — but I’m having trouble grasping what differentiates the specific group of lines you want to remove from the other groups of lines that follow the same pattern.
-
Hello, @jizhao-li, @coises and All,
If I fully understand what you expect to, this means that :
-
After a GAP indication, you want to replace all lines of text, before a first line with a decimal number, by the last line with integer numbers only
-
And the text, from the first line with a decimal number, till the next END indication, is not changed at all
If so, the regex S/R, below, should do the work, nicely :
SEARCH
(?-s)^(GAP\R)(\d+ \d+\R)+(?=.+\.)REPLACE
$1$2
Note that this regex assumes that no blank character exists at the end of all the lines, before the first line with a decimal number !
Else, just use the
Edit > Blank Operations > Trim Trailing Spaceto suppress these extra blank characters at end of lines
As you can see, only the last occurrence of the group
\d+ \d+\Ris re-used, in the replacement phase, with the$2syntaxBest regards
guy038
-
-
If you are working with single files that have 10 million lines of data in a tabular format, I strongly recommend that you use a scripting language like Python (specifically a library like pandas or polars) to manipulate those files, rather than using regular expressions in Notepad++. Not only is Python well-suited for automation of such tasks, a Python script with the right packages would probably perform the desired manipulations many times faster than a comparable solution in Notepad++.
This is especially true if you are working with many such files, since the Find/Replace in Files functionality in Notepad++ is rather slow compared to many alternatives.
To be clear, I’m not dumping on Notepad++ in general, simply saying that its regex search/replace functionality does not scale very well to extremely large files or large numbers of files. I quite like the flexibility of Notepad++ regex search/replace for modestly sized files.
-
Hi, @jizhao-li, @coises, @mark-olson and All,
Despite the legitimate warning, provided by @mark-olson, I was under the impression that my replacement would work correctly, even with a file of
10 millionlines-
Since each character, less than
\x{80}, is coded with one byte only -
Since the average length of each line is around
9.9characters, only
Thus, I created such a file containing
897,000lines for10,668,000bytes and… guess what ?=> Even with my out of date
XPlaptop, it took about13.6 sonly, to modify the15,000occurrences of theTest_Jizhao.txtfile !After replacement, this file now contains
561,000lines for7,308,000bytes. And, of course, with a regex, I verified that between aGAPline and the first line with decimal number, only one line with two integer numbers existsBest Regards,
guy038
-
-
Hi @guy038 ,
Thank you so much for the help.
Your regex worked for most of my lines. And for the lines that didn’t work, it’s not your code not working, but I didn’t describe my problem in enough detail.
Your understanding is mostly correct, but there are two circumstances I missed clarifying:
-
About the line with decimal number. The line beforewhich I want to replace all lines of text, doesn’t need to have a decimal number in the second column, but a different value than what the earlier lines (lines I want to remove) have. See examples below:
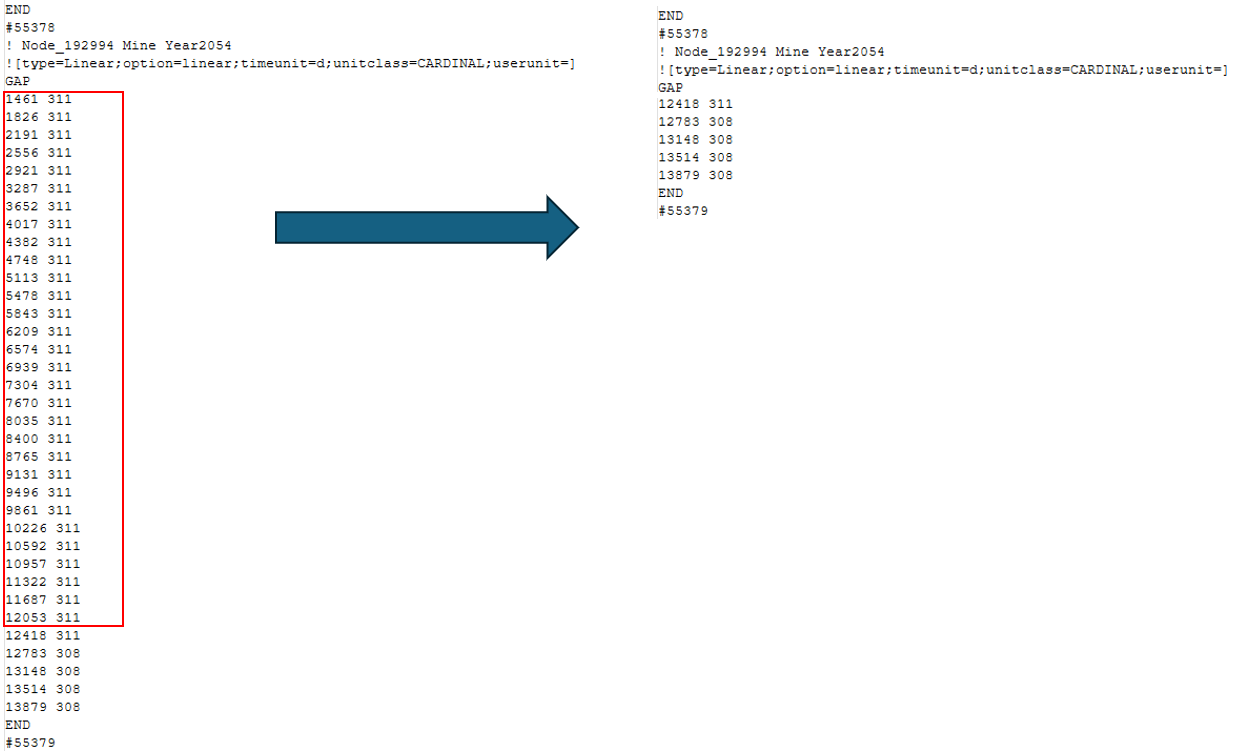
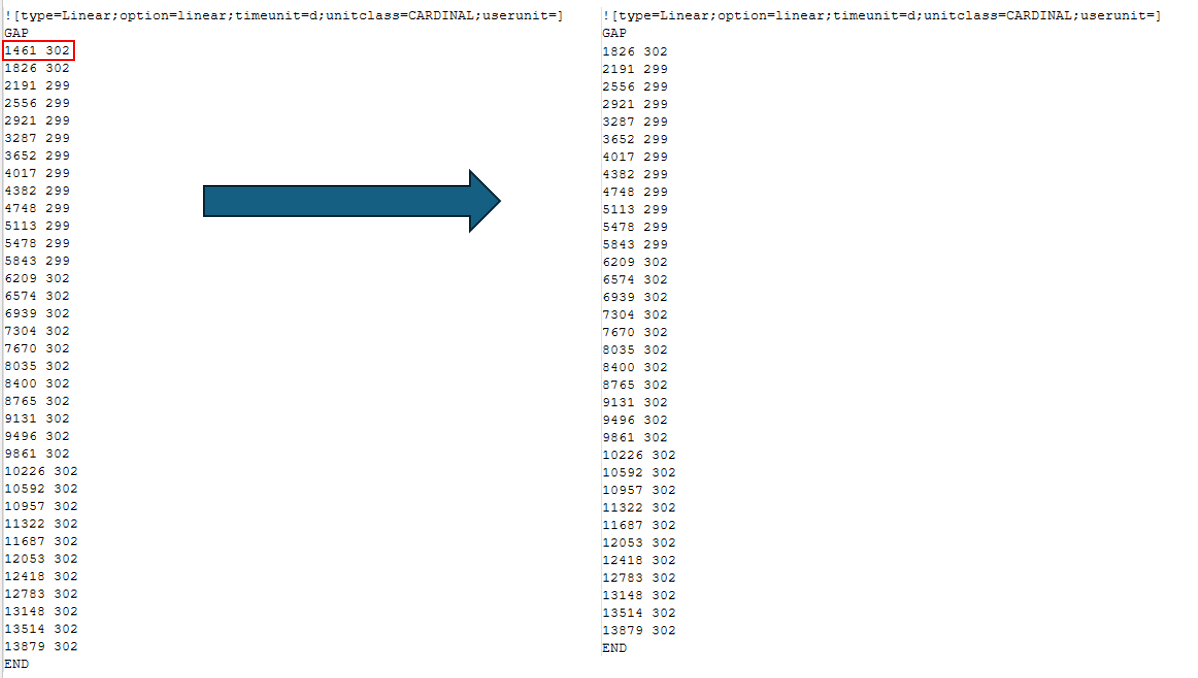
-
There are some circumstances where the second column values are the same for all rows between a GAP and a END. In these cases, do not delete any lines, keep them all. See example below:
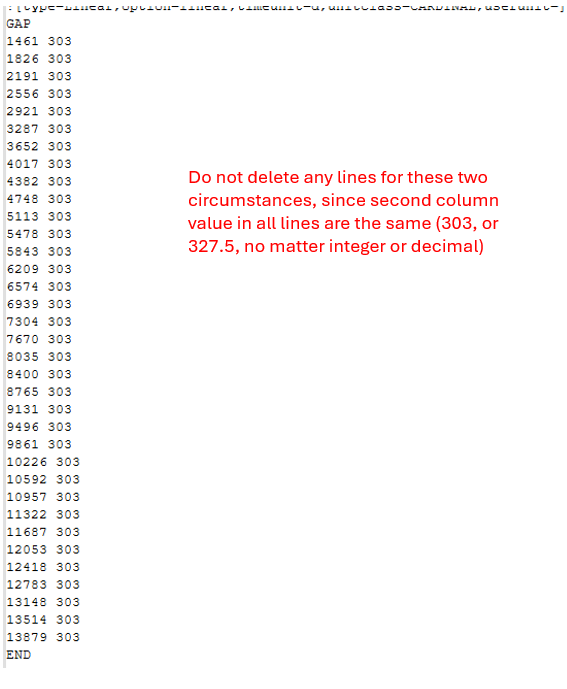
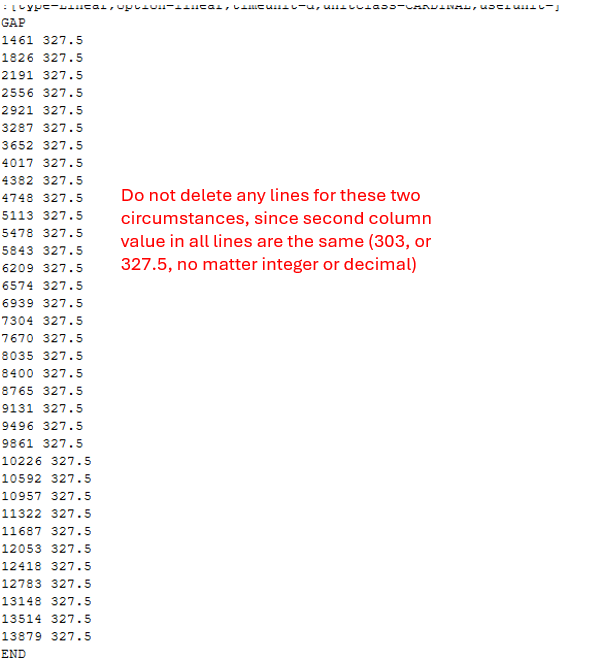
Thank you so much for your help. Your regex definitely helps. If you could slightly adjust it to account for the two circumstances I mentioned above that would be great and much appreciated!
-
-
Hi @Coises,
Thank you so much for your help. I just tried your regex codes and it worked almost 100% for my problem.
There is one circumstance where it didn’t give me the format I wanted, which is shown in the screenshot below:
In this case there is no duplicate second values in this group of data and I actually want to keep all the rows as they are and don’t delete any rows. But using your regex code all the rows except for the last row were deleted.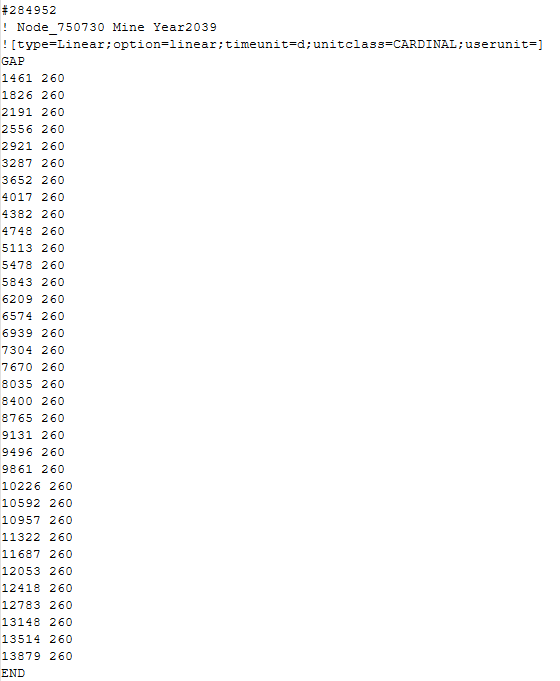
Basically your code works perfectly when there IS a duplicate values in the second column. But when there is NO duplicate values in the second column, I want to keep the original data as they are.
I hope this doesn’t add more confusion. Could you please adjust the code and send it to me? Thank you so much!
-
@Jizhao-Li said in Remove data lines with same value in certain column:
I think I understand. You want to delete all but the last line from the first set of lines with the same second number that follows “GAP,” but only if there is at least one additional set of lines following.
Try changing the find expression to:
^GAP\R\d+ ([\d.]+)\R(?:\d+ \1\R)*(\d+) \1(?=\R\d+ \d+$)(?!\R\d+ \1$)That’s the same test, except it checks to see that it is followed by a line that has two numbers, but not a line with has two numbers with the same second number.
-
Hi, @jizhao-li, @coises, @mark-olson and All,
Ah… OK. Thanks, @jizhao-li, for your additional pieces of information :-)
Then, from this INPUT text, below :
GAP 1461 311 1826 311 2191 311 2556 311 2921 311 3287 311 3652 311 4017 311 4382 311 4748 311 5113 311 5478 311 5843 311 6209 311 6574 311 6939 311 7304 311 7670 311 8035 311 8400 311 8765 311 9131 311 9496 311 9861 311 10026 311 10592 311 10957 311 11322 311 11687 311 12053 311 12418 311 12783 308 13148 308 13514 308 13789 308 END GAP 1461 303 1826 303 2191 303 2556 303 2921 303 3287 303 3652 303 4017 303 4382 303 4748 303 5113 303 5478 303 5843 303 6209 303 6574 303 6939 303 7304 303 7670 303 8035 303 8400 303 8765 303 9131 303 9496 303 9861 303 10026 303 10592 303 10957 303 11322 303 11687 303 12053 303 12418 303 12783 303 13148 303 13514 303 13789 303 END GAP 1461 327.5 1826 327.5 2191 327.5 2556 327.5 2921 327.5 3287 327.5 3652 327.5 4017 327.5 4382 327.5 4748 327.5 5113 327.5 5478 327.5 5843 327.5 6209 327.5 6574 327.5 6939 327.5 7304 327.5 7670 327.5 8035 327.5 8400 327.5 8765 327.5 9131 327.5 9496 327.5 9861 327.5 10026 327.5 10592 327.5 10957 327.5 11322 327.5 11687 327.5 12053 327.5 12418 327.5 12783 327.5 13148 327.5 13514 327.5 13789 327.5 END GAP 1461 302 1826 302 2191 299 2556 299 2921 299 3287 299 3652 299 4017 299 4382 299 4748 299 5113 299 5478 299 5843 299 6209 302 6574 302 6939 302 7304 302 7670 302 8035 302 8400 302 8765 302 9131 302 9496 302 9861 302 10026 302 10592 302 10957 302 11322 302 11687 302 12053 302 12418 302 12783 302 13148 302 13514 302 13789 302 ENDThe following regex S/R should do the work nicely :
SEARCH
(?-is)^(GAP\R)(\d+ (\d+(?:\.\d+)?)\R)+?(?=\d+ (?!\3$))REPLACE
\1\2And here is your expected OUTPUT text :
GAP 12418 311 12783 308 13148 308 13514 308 13789 308 END GAP 1461 303 1826 303 2191 303 2556 303 2921 303 3287 303 3652 303 4017 303 4382 303 4748 303 5113 303 5478 303 5843 303 6209 303 6574 303 6939 303 7304 303 7670 303 8035 303 8400 303 8765 303 9131 303 9496 303 9861 303 10026 303 10592 303 10957 303 11322 303 11687 303 12053 303 12418 303 12783 303 13148 303 13514 303 13789 303 END GAP 1461 327.5 1826 327.5 2191 327.5 2556 327.5 2921 327.5 3287 327.5 3652 327.5 4017 327.5 4382 327.5 4748 327.5 5113 327.5 5478 327.5 5843 327.5 6209 327.5 6574 327.5 6939 327.5 7304 327.5 7670 327.5 8035 327.5 8400 327.5 8765 327.5 9131 327.5 9496 327.5 9861 327.5 10026 327.5 10592 327.5 10957 327.5 11322 327.5 11687 327.5 12053 327.5 12418 327.5 12783 327.5 13148 327.5 13514 327.5 13789 327.5 END GAP 1826 302 2191 299 2556 299 2921 299 3287 299 3652 299 4017 299 4382 299 4748 299 5113 299 5478 299 5843 299 6209 302 6574 302 6939 302 7304 302 7670 302 8035 302 8400 302 8765 302 9131 302 9496 302 9861 302 10026 302 10592 302 10957 302 11322 302 11687 302 12053 302 12418 302 12783 302 13148 302 13514 302 13789 302 END
Some other tests, all OK ! On the left the INPUT text and on the right the OUTPUT text :
GAP 4017 123 4382 123 GAP 4748 123 5478 123 5113 123 5843 456 5478 123 6209 456 5843 456 => 6574 456 6209 456 6939 456 6574 456 7304 456 6939 456 END 7304 456 END GAP 4017 123 4382 123 GAP 4748 123 5478 123 5113 123 5843 456.789 5478 123 6209 456.789 5843 456.789 => 6574 456.789 6209 456.789 6939 456.789 6574 456.789 7304 456.789 6939 456.789 END 7304 456.789 END GAP 4017 123 4382 123 GAP 4748 123 5478 123 5113 123 5843 123.789 5478 123 6209 123.789 5843 123.789 => 6574 123.789 6209 123.789 6939 123.789 6574 123.789 7304 123.789 6939 123.789 END 7304 123.789 END GAP 4017 123.012 4382 123.012 GAP 4748 123.012 5478 123.012 5113 123.012 5843 456 5478 123.012 => 6209 456 5843 456 6574 456 6209 456 6939 456 6574 456 7304 456 6939 456 END 7304 456 END GAP 4017 123.012 4382 123.012 GAP 4748 123.012 5478 123.012 5113 123.012 5843 123 5478 123.012 => 6209 123 5843 123 6574 123 6209 123 6939 123 6574 123 7304 123 6939 123 END 7304 123 END GAP 4017 123.012 4382 123.012 GAP 4748 123.012 5478 123.012 5113 123.012 5843 456.789 5478 123.012 6209 456.789 5843 456.789 => 6574 456.789 6209 456.789 6939 456.789 6574 456.789 7304 456.789 6939 456.789 END 7304 456.789 END GAP 4017 123 GAP 4382 123 4748 123 4748 123 5113 456 5113 456 5478 456 5478 456 5843 456 5843 456 => 6209 456 6209 456 6574 123 6574 123 6939 123 6939 123 7304 123 7304 123 END END GAP 4017 123.012 GAP 4382 123.012 4748 123.012 4748 123.012 5113 456.789 5113 456.789 5478 456.789 5478 456.789 5843 456.789 5843 456.789 => 6209 456.789 6209 456.789 6574 123.012 6574 123.012 6939 123.012 6939 123.012 7304 123.012 7304 123.012 END END
Note that your file will be unchanged if you redo the search-replacement !!
Best Regards,
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login