Can't decode byte 0x89 in position 0: ordinal not in range(128)
-
Hey Guys…need some help again with binary to Hex It seems I’m back to square one when trying to create a working python script that translates the Unicode to binary before converting to Hex. Error reads: UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0x89 in position 0: ordinal not in range(128)
import re # Use a very large number of chars per line to keep it on one line. CHAR_PER_LINE = 1 << 63 def convert_to_hex_lines(binary_data): # Convert binary data to hex representation raw_hex = ''.join('%02X' % ord(byte) for byte in binary_data) if CHAR_PER_LINE >= len(raw_hex): return raw_hex return '\r\n'.join(re.findall('.{1,%s}' % CHAR_PER_LINE, raw_hex)) # Read the binary data from the selected text in Notepad++ selstart = editor.getSelectionStart() selend = editor.getSelectionEnd() if selstart == selend: # If no selection, read the entire document as binary editor.beginUndoAction() editor.setReadOnly(False) editor.selectAll() # Select all text binary_data = editor.getText().encode('latin-1') # Encode as binary hex_output = convert_to_hex_lines(binary_data) editor.setText(hex_output) editor.endUndoAction() else: # If there is a selection, convert only the selected text editor.beginUndoAction() editor.setReadOnly(False) selected_text = editor.getSelText().encode('latin-1') # Encode as binary hex_output = convert_to_hex_lines(selected_text) editor.replaceSel(hex_output) editor.endUndoAction()Any help would be appreciated
Thanks.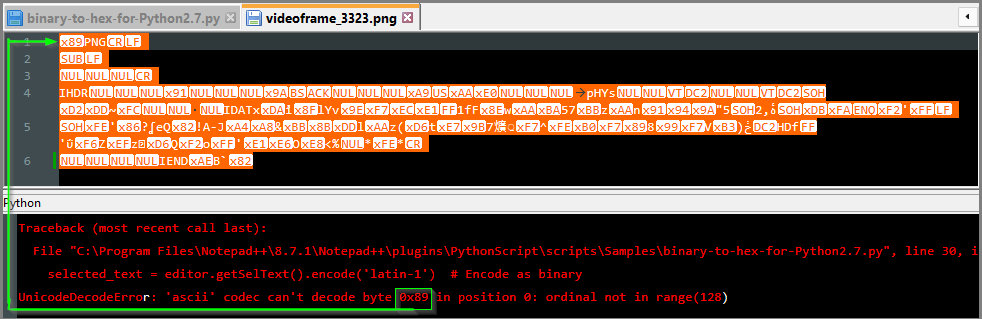
-
I don’t know Python, so I could be mistaken, but I think your approach cannot work reliably. I believe editor.getText() and editor.getSelText() return Python strings, which are always utf-8. Immediately there will be a problem: 0x89 is not a valid start for a utf-8 character, so if the document coding is set to utf-8, the result will be invalid; if it’s something else, the transformation might not be what you expect. I suspect what is happening here is that your document encoding is set to utf-8, and Python is balking when the code behind editor.getSelText() tries to put that in a Python string.
You might have better luck with editor.getCharAt(), which, according to documentation returns an integer rather than a string. Loop through the selection one byte at a time and convert each byte to hex.
-
@LanceMarchetti said in Can't decode byte 0x89 in position 0: ordinal not in range(128):
Any help would be appreciated
The best help I can give would be to tell you that I would not do what you are trying to do.
-
Don’t use
editor.getTextwith binary files. Notepad++ treats the file’s text as aNUL-terminated string for the purposes of that command, and most other text-retrieving commands. Apparently there are some ways for a plugin to get around this, but they are undoubtedly much more arcane.Have I ever mentioned how irritated I am that Don Ho refuses to implement a system for warning people that NPP is an inappropriate app for working with binary files?
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login