Cannot change Encoding to correct encoding of UTF-8
-
Hello fellow NPP’ers,
I read many posts of this type, but still haven’t found a solution to my issue.
I have a .py file, which is saved in Pycharm using UTF-8 encoding.
The file has code + Hebrew within some string assignments, like:
DOWNLOAD_FOLDER = r"C:\Users\MYUSER\Documents\עבודה\SOMFOLDER\תלושים"
When I open this file in NPP, I get chinese letters instead of the Hebrew letters, and the default encoding is GB2312 (Simplified).When I try to change encoding by: Encoding->UTF-8, nothing happens, and when I try to change to: Encoding->Character Sets->Hebrew->Windows-1255/OEM 862/ISO 8859-8, I get Gibberish.
Under Settings->Style Configurator->Default Style, my font is “Courier New”.
Please assist me in solving this issue.
Notepad++ v8.8.2 (32-bit)
Build time : Jun 26 2025 - 01:11:16
Scintilla/Lexilla included : 5.5.7/5.4.5
Boost Regex included : 1_85
Path : C:\Program Files (x86)\Notepad++\notepad++.exe
Command Line : “C:\Users\MYUSER\Documents\עבודה\SOMFOLDER\my_file.py”
Admin mode : OFF
Local Conf mode : OFF
Cloud Config : OFF
Periodic Backup : ON
Placeholders : OFF
Scintilla Rendering Mode : SC_TECHNOLOGY_DEFAULT (0)
Multi-instance Mode : monoInst
File Status Auto-Detection : cdEnabledNew (for current file/tab only)
Dark Mode : OFF
Display Info :
primary monitor: 1920x1080, scaling 100%
visible monitors count: 2
installed Display Class adapters:
0001: Description - Intel® HD Graphics 520
0001: DriverVersion - 27.20.100.8477
OS Name : Windows 10 Enterprise (64-bit)
OS Version : 22H2
OS Build : 19045.6036
Current ANSI codepage : 1252
Plugins :
DSpellCheck (1.4.6)
mimeTools (3.1)
NppConverter (4.6)
NppExport (0.4) -
I am not sure this will work, but it’s easy enough to try:
Open Settings | Preferences… | MISC. and look for Autodetect character encoding. If that box is checked, un-check it and then try opening the file.
Also (in case that doesn’t do it), what is your selection at Settings | Preferences… | New Document: Encoding? In particular, if you have selected UTF-8 but have not checked Apply to opened ANSI files, try checking that.
-
@Tom-Sasson said in Cannot change Encoding to correct encoding of UTF-8:
When I open this file in NPP, I get chinese letters instead of the Hebrew letters, and the default encoding is GB2312 (Simplified).
When I try to change encoding by: Encoding->UTF-8, nothing happens
When I think about it… this doesn’t seem like it should be. Some questions:
-
Are you selecting Encoding | UTF-8 or Encoding | Convert to UTF-8? You said the former, but I want to be sure, because there is a difference.
-
When you attempt to change the encoding, I assume you mean the text display does not change. In the status bar near the bottom right, where it shows
GB2312after opening the file, does that change toUTF-8when you try to change the encoding? -
Is it possible for you to upload a copy of the file somewhere? (Understood that might not be acceptable to you for privacy reasons, or might be inconvenient for you.) I could be confused, but it seems to me like a bug if the file is not being re-interpreted as UTF-8 when you select that option, even if it was mis-identified as GB2312. I’d like to attempt to reproduce it and maybe see if I can figure out why it’s not changing. (Someone else with better knowledge might jump in here and clarify, though.)
-
-
DOWNLOAD_FOLDER = r"C:\Users\MYUSER\Documents\עבודה\SOMFOLDER\תלושים"Unfortunately, that alone isn’t enough to replicate the problem for us. If I save that line of code into a UTF-8-encoded file, and open it in Notepad++, it is properly recognized and interpreted as UTF-8.
As @Coises suggested, if you could share enough code that we could replicate it, it would be great. (See below for a way to hexdump the file, to make sure we can create the same file as you, even if we don’t have pycharm available.)
If there is proprietary information in your code, could you pare it down to the minimum UTF-8 file that you can create in Pycharm that shows the same problem when loaded in Notepad++? If not, you will have to do more investigation on your side with us randomly guessing as to how to direct you: as @Coises suggested, my first steps would be to turn off the autodetect, as no encoding autodetect works 100% of the time; once that’s off, you might also want to see if changing Settings > Preferences > New Document to choose UTF-8 and ☑ Apply to opened ANSI files in the Encoding box on that page of settings.
Normally, with the symptoms you gave, I would guess that Notepad++ saw too many “invalid” UTF-8 sequences: UTF-8 has limited sets of high-order byte sequences that are allowed – for example, after a normal ASCII character, a high-order byte will never be less than
0xC0– and a bunch more rules like that, where this table in the Wikipedia UTF-8 article gives the rules for valid UTF-8 high-byte sequences.Whether you are providing us with a minimal file to replicate, or whether you are investigating proprietary files on your own, the next thing I would suggest is a way to hexdump the file – so you can see what bytes pycharm is writing to disk, vs what characters Notepad++ is interpreting those characters. Since you mentioned pycharm, I am assuming you have Python3 installed on your computer, so save the following as
hexdump.py:import sys; data=open(sys.argv[1],'rb').read(); offset=0; while offset < len(data): chunk = data[offset : offset + 16]; hex_values = ' '.join(f'{byte:02x}' for byte in chunk); ascii_values = ''.join(chr(byte) if 32 <= byte <= 126 else '.' for byte in chunk); print(f'{offset:08x} {hex_values:<48} |{ascii_values}|'); offset += 16;Then, if your file created by pycharm is called
tom.py, runpython hexdump.py tom.pyC:\usr\local\share\TempData\Npp>python hexdump.py tom.py 00000000 44 4f 57 4e 4c 4f 41 44 5f 46 4f 4c 44 45 52 20 |DOWNLOAD_FOLDER | 00000010 3d 20 72 22 43 3a 5c 55 73 65 72 73 5c 4d 59 55 |= r"C:\Users\MYU| 00000020 53 45 52 5c 44 6f 63 75 6d 65 6e 74 73 5c d7 a2 |SER\Documents\..| 00000030 d7 91 d7 95 d7 93 d7 94 5c 53 4f 4d 46 4f 4c 44 |........\SOMFOLD| 00000040 45 52 5c d7 aa d7 9c d7 95 d7 a9 d7 99 d7 9d 22 |ER\............"|If this is the “minimal file” with no proprietary info, then paste that hexdump along with the raw text of the file when you reply.
If you are just investigating on your own, then look for the first character where you have a Hebrew character in pycharm but it shows up as Chinese (or whatever) in Notepad++: for example, the end of line 3 in the dump is 5c (the
\backslash), followed byd7 a2(which isע: mixed LTR and RTL is really confusing to me, so that surprised me at first). Anyway, you can look for “problematic” sequences, like anytime a small byte (00-7F) is followed by a “medium” byte (80-BF), which isn’t allowed; or anytime a high byte (C0-F7) is followed by anything other than a “medium byte”. Maybe you’ll find that pycharm is saving an invalid UTF-8 (though I doubt it). -
@Coises said in Cannot change Encoding to correct encoding of UTF-8:
Open Settings | Preferences… | MISC. and look for Autodetect character encoding.
Thank you for your suggestion, this liitle “trick” with unchecking Autodetect fixed the issue for me
-
I have the same problem. My UTF-8 file is identified as Chinese Big5 (Traditional) encoding. When I choose the correct UTF-8 encoding (not convert) nothing happens, the encoding that is used remains as Big5. I was able to open the file with correct encoding by disabling “Autodetect character encoding” like @Coises suggested, which allowed me open the file with correct encoding. But I don’t understand why that is needed, I want character encoding autodetection to be on, but shouldn’t I be able to manually override the autodetected character encoding?
As @PeterJones suggested, I pared my text file to the minimum, and uploaded it at https://pastebin.com/rHpqwWLp . It’s just a file with the line
🥲ııııı. When I open it Notepad++ v8.6.4 32 bit on Windows 10 22H2, I see Chinese characters and I am unable to change the encoding to UTF-8. I suspect it might not be possible to replicate this on Windows 11, because the 🥲 emoji does not exist in Windows 10 (I am unable to see it right now as I type this reply), which probably contributes to the issue. But I tried this with different emojis that also don’t exist in Windows 10, but I don’t have the same issue then. Just this emoji, followed by fiveıcharacters create this problem (four characters don’t reproduce). Different text sequences, e.g. fiveşcharacters do not reproduce it either, but something likeıışııdoes. Anyway, I don’t have an issue with the autodetection being wrong, I just have an issue with being unable to override it without completely disabling autodetection. -
@debiedowner said in Cannot change Encoding to correct encoding of UTF-8:
I just have an issue with being unable to override it without completely disabling autodetection.
Under most circumstances, you can (for example, the ones listed above). You have found a weird edge case.
I tried the following experiment:
- Settings > Preferences > MISC > autodetect off
- created a new UTF-8 file
- paste in
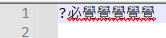
🥲ııııı(which can be copied from your post, and now this post) - save it to a filename
- Encoding > Character Sets > Chinese > Big5 => it now looks like
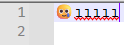
- Encoding > UTF-8 (not Convert To…), and it properly goes back to
- Settings > Preferences > MISC > autodetect on
- same file is still loaded, and still showing as the correct UTF-8
- Encoding > Character Sets > Chinese > Big5 => it’s back to the weird version it was before, as expected when you interpret those bytes as Big5
- Encoding > UTF-8 =>
- expect, like before, that it would go back to being a smiley first,
- but instead, it stays as Big5, which it should not do.
This seems like a bug to me. Autodetect character encoding option should only be in force when opening a file; using the Encoding menu to change how the bytes are interpreted should override anything that’s autodetected, because that’s the whole point of being able to change it with a file loaded.
Do you have the ability / account to be able to put in an official bug report in the issue tracker, because this is something the developer should be made aware of. If so, doing a combination of your steps-to-reproduce plus mine should give him a good picture of what’s going wrong. (Yours shows the real-world use case. Mine will help debug the process without having to open/close files frequently.)
(Maybe someone else [even the developer] will disagree with me, claiming that the Encoding menu should follow that option, too. I would be disappointed if that were the decision, but it’s a possibility.)
I want character encoding autodetection to be on
Out of curiosity, what character encodings do you normally use? If you have auto-detect turned off, does Notepad++ read your normal files incorrectly?
- Settings > Preferences > MISC > autodetect off
-
@PeterJones said in Cannot change Encoding to correct encoding of UTF-8:
You have found a weird edge case.
I was pursuing the same sort of tests when you posted. The edge cases seem to be:
-
When a file is opened as a character set, it can’t be reinterpreted as ANSI or any of the UTF encodings. It can be reinterpreted as a different character set.
-
When a file is opened as ANSI or any of the UTF encodings, it can be reinterpreted as a character set. If you then attempt to reinterpret it again as ANSI or and of the UTF encodings, it will be reinterpreted as the encoding with which it originally opened. (After that you can change it to a different ANSI or UTF encoding.)
It seems like those two behaviors might be related.
I’ve tried before to understand the code that reads files and works out character encoding. I was not successful. So I don’t know whether to think this is an accepted limitation or a mistake. From a user’s point of view it doesn’t make much sense.
-
-
Looks to me like an example of this known issue.
The common trigger is a sequence of emoji followed by ASCII alphanumerics.
I’m guessing the character boundaries get confused between the last emoji and the first ASCII character, with the “tail” of the emoji being mistaken for a DBCS lead byte.
-
@rdipardo said in Cannot change Encoding to correct encoding of UTF-8:
Looks to me like an example of this known issue.
That could be. Character set inference will always have a non-zero failure rate on Windows text files.
The bigger question is, why can’t the interpretation of the file be manually reset? If Notepad++ guesses ANSI, or UTF-8, and it’s wrong, you can change between them, or to a specific character set. But if Notepad++ guesses a character set, you can reinterpret the file as a different character set, but you can’t reinterpret it as Unicode (or ANSI). You have to turn off the Autodetect character encoding setting, so it won’t guess a character set, then open the file again.
-
The common trigger is a sequence of emoji followed by ASCII alphanumerics.
I’m guessing the character boundaries get confused between the last emoji and the first ASCII character, with the “tail” of the emoji being mistaken for a DBCS lead byte.Interesting, in that this example is emoji followed by U+0131. So there isn’t an ASCII character to trigger it. But it is still likely the same bug, or intimately related.
What surprises me, and what I think is different, is that the Encoding menu actions don’t behave the same, based on the option. I was under the impression that the Encoding menu actions (without “convert to”) were just supposed to change how Notepad++ interprets the bytes in the file – primarily for the purpose of fixing it when autodetect is wrong. So the fact that with the option off, it does allow it to be fixed, but when the option is on, it doesn’t allow it to be fixed, is what looks like a separate bug, to me. (Unless there’s someplace where it’s expressed that the intention is for the Encoding menu actions to honor that setting, in which case they are useless for fixing autodetection issues.)
-
@Coises said in Cannot change Encoding to correct encoding of UTF-8:
You have to turn off the Autodetect character encoding setting, so it won’t guess a character set, then open the file again.
Or, as I showed, turn off the option, then just change the encoding in the menu. It properly re-interprets the bytes as whatever you choose, if you have the autodetect turned off. No closing/re-opening of the file needed.
-
@PeterJones said in Cannot change Encoding to correct encoding of UTF-8:
@Coises said in Cannot change Encoding to correct encoding of UTF-8:
You have to turn off the Autodetect character encoding setting, so it won’t guess a character set, then open the file again.
Or, as I showed, turn off the option, then just change the encoding in the menu. It properly re-interprets the bytes as whatever you choose, if you have the autodetect turned off. No closing/re-opening of the file needed.
Yes, you are correct. I missed that.
It seems like Notepad++ should, but doesn’t, ignore that setting and behave as if it were unchecked when you explicitly request reinterpreting the file as ANSI or Unicode.
-
Hello, @tom-sasson, @peterjones, @coises, @debiedowner and All,
Peter, I’ve just tried your
python 3file, namedhexdump.pyagainst the single line that you gave :DOWNLOAD_FOLDER = r"C:\Users\MYUSER\Documents\עבודה\SOMFOLDER\תלושים"And I did obtain the same dump than yours !
The usual Unicode Hebrew script lies between
0591and05F4.Thus, as this text is coded in
UTF-8, any Hebrew character is always coded in two bytes, fromD6 91toD7 B4. So :-
The sequence
d7 a2 d7 91 d7 95 d7 93 d7 94corresponds, as expected, to5Hebrew characters (10bytes ), between the two antislashs. -
The sequence
d7 aa d7 9c d7 95 d7 a9 d7 99 d7 9dcorresponds, as expected to6Hebrew characters (12bytes ), between the last antislash and the last double-quote.
To my mind, in this specific case, we should not speak about low byte, medium byte and high byte, but rather of :
-
The leading byte, which can be
D6orD7 -
The continuation byte, which can be any value between
91andBF, when the leading byte =D6and any value between80and87, OR between90andAAOR betweenAFandB4, when the leading byte isD7
Given the last Unicode
v17.0Hebrew code chart at :https://www.unicode.org/charts/PDF/U0590.pdf
Best Regards,
guy038
-
-
@guy038 said in Cannot change Encoding to correct encoding of UTF-8:
we should not speak about low byte, medium byte and high byte,
It was a colloquial choice. I wasn’t talking about valid sequences – and especially not valid Hebrew sequences. I was assigning lables (“low”, “medium”, and “high”) to specific groups of byte values. In valid UTF-8, there will never be what I called a “low byte” [
00-7f] followed by what I called a “medium byte” [80-BF], because UTF-8 doesn’t allow starting a new multi-byte sequence with anything in that range. Furthermore, in valid UTF-8, there will never be a “high byte” [C0-F7] followed by another “high byte” or a “low byte”: there will always be one or more “medium bytes” [80-BF] after a “high byte”. Thus, I was describing a way to find a bad sequence. (And I also wasn’t limiting myself to talking about Hebrew characters, because I wanted my description to work even if the file had other UTF-8 characters as well, and my description would have helped find those, too. Also, I wasn’t very optimistic that one existed: it was just something I suggested looking for, and as the reply indicated, the issue wasn’t bad UTF-8 sequences, but Notepad++'s failure to autodetect.)update: If I had known/remembered the term, I probably should have used the word “continuation byte”, but I didn’t know that UTF-8 already had a term for that.
-
I consider back to basics logic might be needed so will explain in some details how I understand the forever it seems inducing headache caused by multiple encodings and character sets/ranges.
I will try to explain it this way: ANSI encodings use character sets with re-using ASCII Extended bytes as a value. Unicode encodings use character ranges as are unique being linear with their own bytes as a value.
Changing a character set does not need re-encoding though Notepad++ wants to convert to wide-char/unicode can at times screw it up. Like German ANSI converted to Hebrew unicode is screwed with many issue reports and seen it myself in testing. Notepad++ with using the CharDet library can select the incorrect character range as it can choose to implicitly convert to unicode.
In SciTE for example, I can change an ANSI character set by changing the property value of
character.setwithout any re-encoding to unicode. Thecode.pageproperty can set a character set that is suitable so that settingcharacter.setmay not be needed at times. What Notepad++ does is not like what other editors do with some probable error of assumption of my view. Those learning the Notepad++ way without learning from others could be trapped in a belief that may not be correct. That means trying to solve these related problems can be derailed in discussions.Those that think that encoding is directly related to character sets IMO are missing the basic concept as they are more so indirectly related. Character sets in ANSI is more like choosing font characters rather then the encoding. With ANSI encoding, Asian languages as being more complex languages IMO which can be 2 bytes per character to increase the size of the character set.
While automation can save effort of re-doing things. Computers have the processing speed while humans should have the fundamental logic if their brains work OK. When it comes to CharDet, the user might be better at choosing the code page or the character set for ANSI files that use any Extended ASCII bytes instead of trusting a library that can sometimes fail to make the correct choice. The implicit unicode conversion can exasperate the failure.
-
@mpheath said in Cannot change Encoding to correct encoding of UTF-8:
What Notepad++ does is not like what other editors do with some probable error of assumption of my view.
Not only that — some of those faulty assumptions have even been patched in to N++'s copy of Scintilla!
See, for example, Neil’s critique of this modification to
ScintillaWin.cxx. -
@debiedowner said in Cannot change Encoding to correct encoding of UTF-8:
Anyway, I don’t have an issue with the autodetection being wrong, I just have an issue with being unable to override it without completely disabling autodetection.
In this thread @mpheath and @rdipardo have discussed other problems, and @PeterJones has noted that you can disable the setting, change encoding and immediately enable the setting again, but I agree that what you describe seems like unintended, and certainly unexpected, behavior.
The culprit is here:
if (nppGui._detectEncoding) fileFormat._encoding = detectCodepage(data, lenFile);This occurs as the file is reloaded. (Changing the encoding in Notepad++ always reloads the file. That makes sense because it needs the original data to reinterpret using the new encoding. File data is not always stored in the editor the same way it is stored in the file itself.) It’s the same process used to load the file originally. There is no flag passed down to tell it to skip the codepage detection and just do what the user requested.
A few lines earlier there is a similar test for Unicode byte order marks. If a user with default code page Windows-1252 (that covers most places with a latin-based alphabet) opens a new tab in Notepad++, sets encoding to ANSI (if necessary), pastes in the following text:
abcand saves the file, then closes the tab and opens the file again, the first three characters will be missing, and the file will be opened as UTF-8 with BOM. Nothing you can do will show those three characters again in the editor; you can change the encoding to ANSI, but they will still be missing.
It seems to me that the file loading routine should somehow be made aware of the context and should skip all file format detection when it is being called to reinterpret a file using a different encoding. At this point, I don’t have a suggestion as to how best to make that information available to FileManager::loadFileData.
-
Reported as Issue #17033.
-
 G guy038 referenced this topic on
G guy038 referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login