Searching for ASCII characters in CJK ANSI files using regular expressions
-
In SCI_GETCODEPAGE is NOT always either 0 or 65001 I noted that in addition to the well-known values of CP_ACP (0) and CP_UTF8 (65001), there are four other values which SCI_GETCODEPAGE can return in Notepad++.
These values — 932 (Japanese, Shift-JIS), 936 (Chinese Simplified, GB2312), 949 (Korean, Windows-949 / Unified Hangul Code) or 950 (Chinese Traditional, Big5) — only occur when the system default code page is one of those values and the file is in “ANSI” encoding. Unless one of those is already your system default code page, testing this requires opening Control Panel (the old-style one, not modern Settings), selecting Region, then the Administrative tab, clicking the Change system locale… button, selecting one of the listed languages from the drop-down, clicking OK, and then restarting the machine.
I have only tested with Japanese. I do not read, write or speak Japanese, so I could be missing relevant details.
Thinking about what I observed made me wonder if the search I included in Columns++ would malfunction when in ANSI mode with a CJK file. It seemed that the regular expression search, at least, would have to… and, as expected, it does. Normal and extended searches appear to behave correctly.
I then observed that the same happens with the built-in Notepad++ search (also only in regular expression mode).
The specific error I expected, and found, is that when searching a Japanese test for ASCII letters, the search shows hits which are, in fact, not ASCII characters but the second byte of a double-byte character. I used this text, from a section of a Japanese Wikipedia page:
浄土思想でいう「極楽浄土」(阿弥陀如来が治める浄土の一種、西方浄土)は西方にあり、1年の内で2度、昼と夜との長さが同じになる春分と秋分は、太陽が真東から昇り、真西に沈むので、西方に沈む太陽を礼拝し、遙か彼方の極楽浄土に思いをはせたのが彼岸の始まりである。昼夜・東西が平行になるお彼岸の時期には、「あの世」への門が開くといわれてきた。現在ではこのように仏教行事として説明される場合が多い。それがやがて、祖先供養の行事へと趣旨が変わって定着した。Here are a couple screen shots:
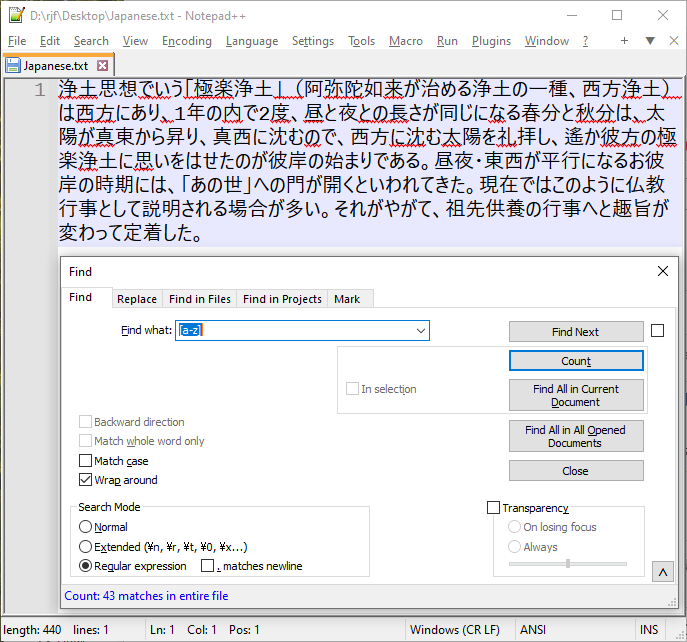
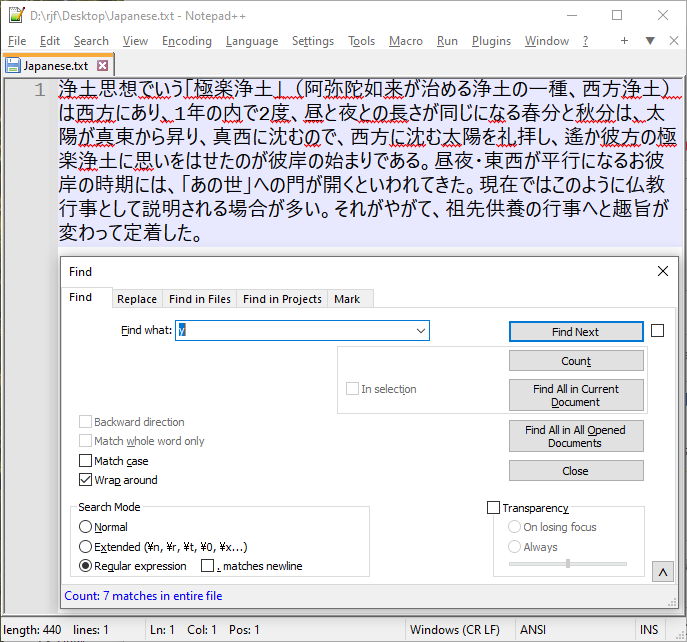
I would expect, but have not endeavored to demonstrate, that mismatching of Japanese characters could also occur. Since many bytes in this code page can be either leading or trailing bytes, and the regular expression search in ANSI mode is (as best I can tell) treating the text as a stream of independent bytes, I believe the trailing byte of one character and the leading byte of the next could match the two bytes of a different, single character in the search string.
I could not find anything about this in the GitHub issues. I’m wondering if this is an accepted limitation (i.e., if you want to search CJK, you must convert to Unicode), a known bug that hasn’t been addressed, or just something no one ever came across and reported.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login