Korean script letters do not group in Notepad and Notepad++ (Help Wanted)
-
When I try to type the Korean alphabet, it does type the letters in Notepad and in Notepad++.
However, in both of those platforms, the letters do not join.For example, I want to get (한국).
I get (ᄒ ᅡ ᄂ ᄀ ᅮ ᄀ).Even in this chat-box for example, they join together appropriately.
Therefore, they are separated by spaces here.
I already tried to change the encodings and fonts, and the characters simply do not join.I understand that it is not a bug and that it is a specific feature.
But I want to know if there is a way to perform this character joining in Notepad and in Notepad++.I can still type the Korean script appropriately in more sophisticated and advanced typing platforms.
Such as those with .CSS and LaTeX support along with being able to type math formulas.Thanks.
-
I know nothing of the specifics of Korean, with or without Notepad++.
But I know that in Notepad++, with my normal selection of fonts, only some of the combining diacritics properly combine in Notepad++. For example, with Fira Code, Combining Overline U+0305 will combine with the x or y or z before them, but with . or a digit, they seem to combine with the next character rather than the previous character like they are supposed to:
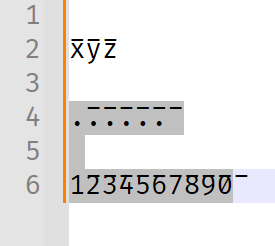
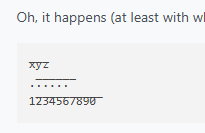
Oh, it happens (at least with whatever font I have in my browser) in the browser, too:
x̅y̅z̅ .̅.̅.̅.̅.̅.̅ 1̅2̅3̅4̅5̅6̅7̅8̅9̅0̅Screenshot:
So when I look at
한at compart’s unicode reference, and alsoᄒandᅡandᄂandᄀandᅮandᄀ-> they all show up as “Combining Class: Not Reordered”, whereas the Combining Overline U+0305 shows as “Combining Class: Above”. I don’t know if that means anything, however.I tried pasting
하ᄂ구ᄀinto LibreOffice Writer, and it combines some of the pieces but not all:
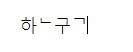 – it also uses NSimSum font when I paste those characters. And though I pasted them in as the six characters next to each other, once they are in, Writer treats them as 3 characters:
– it also uses NSimSum font when I paste those characters. And though I pasted them in as the six characters next to each other, once they are in, Writer treats them as 3 characters: 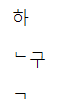
If I choose NSimSum in Notepad++, it doesn’t affect how they combine (or not), whether in DirectWrite or GDI mode…
So, anyway, I don’t think that’s much of an “answer” for you. But it’s a little more data.
Sorry if this is just rambling
-
@PeterJones said in Korean script letters do not group in Notepad and Notepad++ (Help Wanted):
I tried pasting 하ᄂ구ᄀ into LibreOffice Writer, and it combines some of the pieces but not all:
9b81f20d-99dd-4e01-82e8-986bc761c8d4-image.png – it also uses NSimSum font when I paste those characters. And though I pasted them in as the six characters next to each other, once they are in, Writer treats them as 3 charactersI’ve been trying to figure out what is going on here. I know nothing about the Korean language, but I did come across the Hangul jamo while implementing the Unicode rules for determining grapheme cluster boundaries as part of my Unicode-based search.
I don’t recommend trying to read that unless you have a lot of free time and brain power. The bottom line for this purpose is that Hangul syllables are written as separate characters, each of which can be composed of multiple Unicode code points. The most common sequence is LeadingConsonant+Vowel+TrailingConsonant, though there are extensions and complications.
Like many other Unicode characters, Korean characters come in composed and decomposed forms. I think all the modern Korean characters have a single-code-point composed form. They’re usually typed in a decomposed form, though, and assembled into composed form by an Input Method Editor, though decomposed form is permitted in Unicode.
The reason pasting that combination into LibreOffice Writer produces three characters rather than two — which, as you might notice, is also true in the web browser rendering — is because the original poster’s decomposition is wrong. The canonical decomposition of
한국(\ud55c\uad6d) isᄒ ᅡ ᆫ ᄀ ᅮ ᆨ(\u1112\u1161\u11ab\u1100\u116e\u11a8), notᄒ ᅡ ᄂ ᄀ ᅮ ᄀ(\u1112\u1161\u1102\u1100\u116e\u1100). The latter version uses all leading forms for the consonants, but the third and sixth code points should be the trailing forms.However, the correct decomposition still doesn’t compose visually in any font I can find in Notepad++.
I downloaded the current version of Scite and set the font to NSimSum by using Options | Open User Options File, typing:
font.base=font:NSimSum,size:12there, and saving. I opened an empty tab and chose File | Encoding | UTF-8. Then I pasted:
한국 á ç(You can’t see it here, but that is the canonical decomposition of all those characters.) Just as in Notepad++, the Latin letters with diacritics display as composed, but the Korean syllables do not.
Therefore, I think this is a Scintilla limitation. Why it doesn’t compose visually, when LibreOffice Writer and web browsers do, I have not yet been able to determine.
All this might not be as related to the problem @SalviaSage described as it appears to be. Notice that the original post says:
For example, I want to get (한국).
Those two characters are composed. They don’t consist of individual jamo. You can determine that by pasting them into Notepad++. You can also determine that neither the forum nor the web browser is performing the conversion to composed form by pasting this: 한국 into Notepad++. It looks the same here, but it’s six separate characters in Notepad++.
So I think the original poster’s problem has more to do with using, or not using, or misusing, an Input Method Editor. Unfortunately, I don’t know anything about those. Notepad++ will display the composed Korean characters just fine; for some reason, the individual jamo are going directly from the keyboard to Scintilla without composition. I’m thinking perhaps an inline IME is a default for a web browser, but not for Notepad++? I have to leave pursuit of that possibility to someone else.
-
C Coises referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login