FunctionList: v8.8.7 Perl parser is apparently inefficient
-
Based on older conversations here, I had been using an advanced version of the Perl parser for the Notepad++ FunctionList, which handles Classes (including, in Perl nomenclature, “Packages”) and Functions, compared to the simple FunctionList definition which had been shipped by default with Notepad++.
When Issue #17043 was submitted, I was prompted to submit my advanced Perl parser to be distributed, and it was released with v8.8.7.
However, soon after the release, Issue #17152 was created, claiming that even for simple Perl code, it can take multiple seconds when they switch tabs into Perl code – even for the unitTest file. I obviously hadn’t seen that over my 5 years of actively using my advanced Perl FL, but I don’t doubt that there might be inefficiencies in the regex used…
The FunctionList definition shipped with v8.8.7/8.8.8 is here.
I know that @guy038 enjoys trying to make regex more efficient, and that @MAPJe71 is much better at FL definitions than I am.
So if anyone wants to take a look at provide some efficiency advice on this FL, that would be great.
The expectations are that it would need to have the same unitTest results in the automated process, which looks like the following FL in the GUI:
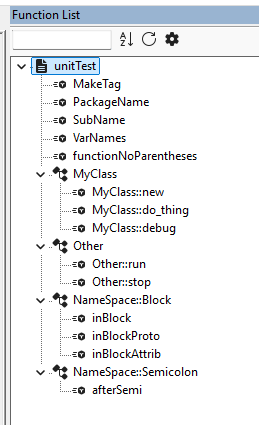
I am not great at determining regex efficiency, so I don’t know what might be able to be done to the regex to help the multiple users in the new issue, without giving up and reverting to the less-functional parser that was distributed in v8.8.6-and-earlier
-
I’m not familiar with Perl or with Notepad++ function lists, but just on general regex principles, this bit at line 60 and again at line 84 looks suspicious:
(?:\s*\([^()]*\))? (?:\s*\:\s*[^{]+)? \s*\{especially because
[^{]includes\s; so a lot of pointless retrying could occur. I think this:\s*+(?:\([^()]*+\)\s*+)?+ (?:\:[^{]+)?+ \{says the same thing without as much retrying. (You would think that not all those plus signs should be needed, and some might not be; but at least with the boost:regex engine in Notepad++, I’ve seen evidence that sometimes what seem like brain-dead obvious optimizations you would expect the engine to make are not in fact applied.)
However, since
\s*[^{]+matches the same strings as[^{]+(and makes the following\s*redundant when it matches), I suspect that might not be what you meant to write. What you have says, after a colon there has to be a string of one or more characters, which can be anything other than a left brace (including just one blank, line feed, etc.), then a left brace. If you add a possessive qualifier to the space —\s*+[^{]+— then there has to be at least one non-space character other than a left brace present after the colon and before the left brace (because if they’re all space characters the possessive\s*+will “eat them up” and there won’t be anything left to match[^{]+). So the three lines would be:\s*+(?:\([^()]*+\)\s*+)?+ (?:\:\s*+[^{]+)?+ \{if you meant to require at least one non-space character between the colon and the left brace.
I am not great at determining regex efficiency
The main principle is to think through the matching from left to right and try to write it so that at each character, there is only one choice: match, or don’t. In the three lines we started with, suppose the text to be matched starts with a blank. Is it the optional space at the start of the first line, or the one at the start of the second line, or the one at the start of the third line? Each possibility has to be tried to see if it works out.
In my rewrites, the first thing that happens is that any leading spaces are matched by
\s*+; there’s no retracing our steps later. Now, either the next character is a left parenthesis or it isn’t, so we immediately know whether we do or don’t use the first optional group. At the end of the first optional group, if we use it, we match all space characters again, so when we get to the second optional group, either there is a colon or there isn’t. And so on. Use possessive groups whenever possible. And assume the regex engine is dumb as dirt… just because you can “see” that some retry is pointless doesn’t mean it won’t plod along trying matches that can’t possibly work anyway. -
@Coises ,
Thanks for the suggestions.
When I tried updating those, with the possessives for the spaces, I could still notice the delay (if anything, it moved from about half a second to a full second when I would switch tabs).
But I decided at that point to go back to the v<=8.8.6 version, and start adding back in “features” of the updated version until it slowed down (because even in mine, the v8.8.6 was near instantaneous for the unitTest, whereas the v8.8.8 was noticeable, but usually less than a second). And I was surprised that it slowed down on the first thing I tried: the final
<className><nameExpr ...>was what was slowing it down.So looking at the v8.8.8 nameExpr at line 99,
\s\K((::)?\w+)+(?=::), the(::)?\w+falls prey to the uncertainty, and probably backtracked a lot. So I changed tosub\s+\K\w+(::\w+)*(?=::\w), and now the ambiguity causing backtracking goes away, and it’s back to nearly instantaneousSo with your possessives for the space, and reworking the className nameExpr, I think it’s probably much better. I will try to share that one with the users from the issue, and see if it improves things for them, as well.
-
@PeterJones said in FunctionList: v8.8.7 Perl parser is apparently inefficient:
I will try to share that one with the users from the issue, and see if it improves things for them, as well.
Got two confirmations for people who had the problem: the optimized regex improve performance dramatically. So I’ve submitted the updated parser to the codebase: hopefully, it will be released in the next version.
@Coises , thanks for the suggestion.
-
Hello, @peterjones, @coises and All,
Hum… Peter, I did not understand how the
unitTest.expected.resultis supposed to work !Sorry for being such a beginner, in this regard. I tried to rename this file as
unitTest.pl. without any improvement ! TheFunction Listpanel is desperately empty, after the unitTest.pl name :-((… And I cannot get your snapshot showing a functional
Function Listpanel, with name UnitTest. What obvious thing am I forgetting ?Best Regards,
guy038
-
Hum… Peter, I did not understand how the
unitTest.expected.resultis supposed to work !unitTest.expected.resultis the JSON file that Notepad++ uses during its automated tests to check the result (User Manual > Function List > Unit Test File Is Absent describes how to manually run).But the
unitTest.expected.resultis not the file you should use to test the Perl lexer. TheunitTestfile is Perl source code, and is the file that Notepad++ needs to load.If you were trying to get a FunctionList on the
unitTest.expected.result, that’s not going to happen, which probably explains the rest of your questions.For the
unitTestfile, which is Perl code, it has a perl shebang line, so Notepad++ can auto-recognize it. But if, for some strange reason it doesn’t, renamingunitTesttounitTest.plor manually choosing Language > P > Perl should be sufficient to get FunctionList to display (maybe with clicking the REFRESH button on the FL panel)But with this
perl.xmlin the pull request, the users who were having performance issues with the v8.8.7/8 parser have reported that performance issues have gone away. So I think we’ve solved it, at this point. -
Hi, @peterjones and All,
Peter, actually, we were not talking about the same thing !
On GitHub, under the tree structure
notepad-plus-plus/PowerEditor/Test/FunctionList/perl, there are two files :-
unitTest( named unitTest.txt ) -
unitTest.expected.result( named unitTest.expected.result )
And indeed, after downloading the
unitTest.txtfile and opening it within N++, it did automatically recognized this.txtfile as a Perl file, due to the first line#!/usr/bin/env perl
Now, in the
functionListsub-folder of my portable887_x64installation, I copied three files :-
perl.xmlof N++v8.8.6, that I renamedperl_886.xml -
perl.xmlof N++v8.8.7, that I just re-copied asperl_887.xml -
perl.xml, from your last link ( https://github.com/notepad-plus-plus/notepad-plus-plus/blob/3d829d9a311fa05f77479b79b5b340e05986a52e/PowerEditor/installer/functionList/perl.xml ), that I renamedPerl_NEW.xml
Then, after closing N++, from a
CMDprompt, I ran, successively, the three commands :• D:\887_x64\functionList>copy perl_886.xml perl.xml • D:\887_x64\functionList>copy perl_887.xml perl.xml • D:\887_x64\functionList>copy perl_NEW.xml perl.xmlI re-started N++, each time, with current tab =
unitTest.txtand opening theView > Function Listfeature, I did verify that :-
The
Function Listpanel withperl_886was immediate but quite incomplete -
The
Function Listpanel withperl_887was correct but with a slight delay at opening time -
The
Function Listpanel withperl_NEWwas correct and with no delay at all !
Therefore, I now have the necessary equipment to test the
Perl function listregexes and imagine possible new regexes. But just for myself, because I doubt I’ll find anything better than your solution !Best Regards,
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login