Negative lookbehind regular expression not working on Notepad++
-
This post is deleted! -
@dr-ramaanand said in Negative lookbehind regular expression not working on Notepad++:
(?<!<span\b[^>]*?color\s*:\s*black[^>]*>\s*)Lookbehinds cannot have variable length (ie, the
*or other numeric quantifiers). Rework your regex (no, I won’t do it for you) to put all the lookbehind options to the left, but instead of having them in lookbehinds, use\Kto rest the start of the match to happen after the stuff that must come before. -
@PeterJones I understand what you mean but the regular expression
((?<!<span\b[^>]*?color\s*:\s*black[^>]*>\s*)(?<!<p\b[^>]*?color\s*:\s*black[^>]*>\s*<span\b[^>]*>\s*))\K<code\s*style="background-color:\s*transparent;">is also invalid. The\Kis supposed to skip whatever precedes it and match what follows it, right? -
@dr-ramaanand said in Negative lookbehind regular expression not working on Notepad++:
I understand what you mean …
Are you sure? Because the new regex you showed still has a lookbehind with an asterisk in it. If you are switching to
\Kinstead of lookbehind, you have to also get rid of the lookbehinds and make everything before the\Knormal, not lookbehind. -
@PeterJones The RegEx
(<span\b[^>]*?color\s*:\s*black[^>]*>\s*|p\b[^>]*?color\s*:\s*black[^>]*>\s*<span\b[^>]*>\s*)\K<code\s*style="background-color:\s*transparent;">skips what I want to match and matches what I want to skip for that block I typed for testing right at the top of this thread. Am I missing something you are trying to convey or have you misunderstood? See https://npp-user-manual.org/docs/searching/#assertions for the explanation of how to use\K -
@dr-ramaanand said in Negative lookbehind regular expression not working on Notepad++:
The
\Kis supposed to skip whatever precedes it and match what follows it, right?Not quite. The
\Ksays “whatever came before this must have matched, but the official match will start after this” – soabc\Kdrequiresabcto come before thed, but the official “matched text” is just thed -
@dr-ramaanand said in Negative lookbehind regular expression not working on Notepad++:
@PeterJones The RegEx
(<span\b[^>]*?color\s*:\s*black[^>]*>\s*|p\b[^>]*?color\s*:\s*black[^>]*>\s*<span\b[^>]*>\s*)\K<code\s*style="background-color:\s*transparent;">skips what I want to match and matches what I want to skip for that block I typed for testing right at the top of this thread. Am I missing something you are trying to convey or have you misunderstood?For questions like that, you’ll have to wait for someone who has more patience than I do.
-
@dr-ramaanand said in Negative lookbehind regular expression not working on Notepad++:
(?<!<span\b[^>]?color\s:\sblack[^>]>\s*)(?<!<p\b[^>]?color\s:\sblack[^>]>\s*<span\b[^>]>\s)<code\sstyle="background-color:\stransparent;">
I think this my above RegEx is most accurate but it needs some modification to work on Notepad++. It works on https://regex101.com if I choose the ECMA script (JavaScript) Regular expression flavor. I am wondering if I can download JavaScript for Notepad++ from here: https://github.com/notepad-plus-plus/userDefinedLanguages/blob/master/udl-list.md
-
@dr-ramaanand Someone please tell me how to install JavaScript in Notepad++ and use it as per what this mentioned: https://community.notepad-plus-plus.org/topic/18592/adding-a-shortcut-to-a-language/3
-
No one can help you here unless everyone knows what you are trying to do. Stating you have an error so the only help possible is focused just on just explaining the error so results in quite limited communication. You seem to be trying to match a whole tag to get another tag which I do not not know why you are trying to do it, what should be matched exactly and what data is wanted. Seems you know but we do not know.
If you want to use JScript (Microsoft’s javascript), then try installing the ActiveX plugin in Plugin Admin. You may want to download the script56.chm help file for the regular expression syntax. Seems like an act of desperation though perhaps you might discover a nicer way to interact with Notepad++ so good luck with it.
-
@dr-ramaanand that post is a bit old, but it’s based on Python code, not Java code. The Python Plugin is available via Plugins > Plugins Admin… - more detailed instructions can be found earlier in that thread.
A more recent post with an alternative that you might find easier to implement would be this one: https://community.notepad-plus-plus.org/topic/26591/marco-s-do-not-record-and-execute-shortcuts/11
-
@dr-ramaanand said in Negative lookbehind regular expression not working on Notepad++:
@dr-ramaanand Someone please tell me how to install JavaScript in Notepad++ and use it as per what this mentioned: https://community.notepad-plus-plus.org/topic/18592/adding-a-shortcut-to-a-language/3
The page you linked to doesn’t mention “JavaScript” ever. The page you linked to does mention the PythonScript plugin.
That conversation shows using the PythonScript plugin to change the Language-menu syntax-highlighting selection in Notepad++, because Notepad++'s Language menu is not macro-recordable. That seemed like an odd request for this conversation, because this conversation has nothing to do with syntax highlighting.
But then I reread the post you made just before, where you said,
I think this my above RegEx is most accurate but it needs some modification to work on Notepad++. It works on https://regex101.com if I choose the ECMA script (JavaScript) Regular expression flavor.
Ahh, now I get it. You see a couple of keywords and get yourself all confused and start asking for more impossible things, and confusing multiple different, independent, unrelated ideas.
As we’ve told you for years, regex101.com doesn’t include Boost regex, and you shouldn’t expect Notepad++'s Boost regex engine to work the same as your tests on regex101. But when we’ve said that to you, we weren’t expecting you to eventually try to “manipulate” Notepad++ into using some different flavor of regex – we expected you to try to learn Notepad++'s Boost regex rather than trying to learn some other random flavor of regex. It’s so frustrating that you’re doing the exact opposite of what you should be doing, if you want to continue using Notepad++ regex to manipulate your HTML (which you shouldn’t be doing).
I am wondering if I can download JavaScript for Notepad++ from here: https://github.com/notepad-plus-plus/userDefinedLanguages/blob/master/udl-list.md
You have completely misunderstood the userDefinedLanguages repo. Seriously. User Defined Languages (UDL), like the rest of the Language menu, are JUST about syntax highlighting – the coloring of the text to help you see language keywords when programming. Installing a JavaScript UDL would not help you at all, because that would just give you a different syntax highlighting for JavaScript code files (since Notepad++ already has built-in syntax highlighting for JavaScript, a UDL isn’t necessary anyway); adding that JavaScript UDL would not magically give you a new regular expression syntax in Notepad++, nor would it allow you to run JavaScript code that uses JavaScript regular expressions.
That said, if YOU knew JavaScript, you could install a JavaScript plugin from Plugins > Plugins Admin – it’s called “jN Notepad++ Plugin”. But I’ve never used that plugin, and I don’t know if it actually gives you access to JavaScript’s regular expression engine or not (and if it did, you would have to write a script in JavaScript to make use of that, and we are not going to be able to help you learn the JavaScript programming language nor its specific regular expression syntax, because this isn’t the place to learn JavaScript).
So, to sum up:
-
You wanted JavaScript in order to get its regex language, but then mistakenly asked how to install the JavaScript User Defined Language from the UDL collection URL linked to above – which would not give you a JavaScript interpreter nor the JavaScript regular expressions.
- in other words, answering that first question would not give you JavaScript regular expressions
-
You wanted JavaScript in order to get its regex language, but then linked to a post from years ago, which was about using the PythonScript plugin (which is completely different that JavaScript) to change the syntax highlighting.
- using PythonScript to change the active Language menu selection would not give you JavaScript regular expressions in Notepad++.
- you were even able to confuse @mathlete2 enough to make him think that you actually wanted to automate changing the syntax highlighting, so he linked to a way to do it by hacking the macro engine. But it would still just change the active Language selection for syntax coloring, and it would not give you JavaScript regular expressions in Notepad++
-
What you really seem to be looking for now is to get a JavaScript interpreter inside Notepad++, so that you can run JavaScript regular expressions on files opened in Notepad++.
- If you wanted to learn how to code in JavaScript, and wanted to figure out how to use the jN Notpead++ Plugin, you might be able to. But I really don’t think that’s the best choice for you.
-
If you are going to continue to use regular expressions and Notepad++ to manipulate HTML code (which you already know is a bad idea), what you really need to do is to study the Notepad++ regular expressions more, and try to learn its quirks, rather than trying to force Notepad++ to use some different regular expression language just so it matches a random tool that gives you advice for a different regular expression variety.
-
-
@dr-ramaanand said in Negative lookbehind regular expression not working on Notepad++:
skips what I want to match and matches what I want to skip for that block I typed for testing right at the top of this thread
Looking again at how you misunderstand everything, I think I see what you did wrong: you originally had XYZ in a negative lookbehind, followed by ABC in the normal match, which was trying to mean “anything but XYZ can come before ABC”.
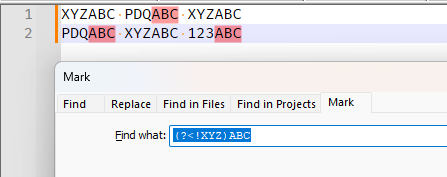
But when you converted to
\Ksyntax, you tried to look for XYZ before ABC, which is the exact opposite.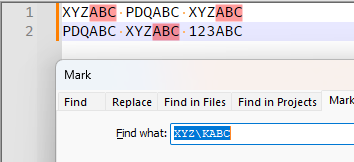
What you need to do is come up with a way of saying “match any text that is not XYZ, then reset the match, then really match ABC”. Unfortunately, with complicated “not XYZ”, I personally don’t know how to express that syntax in all situations. Here’s an example with the literal XYZ and ABC:
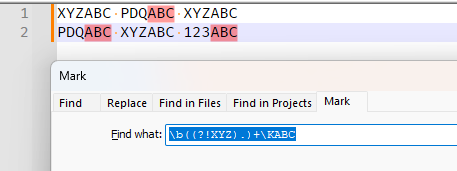
You might be able to use the same idea to make it work for your complicated, but my original experiments weren’t successful.
But just so you know, I really don’t like doing super-complicated single-run regular expressions when a multi-step that’s easier to understand would work. I will come back soon with a 3 step process to do what I think you want.
-
I said,
I will come back soon with a 3 step process to do what I think you want.
- FIND =
(<span\b[^>]*?color\s*:\s*black[^>]*>\s*|p\b[^>]*?color\s*:\s*black[^>]*>\s*<span\b[^>]*>\s*)\K
REPLACE =☹- this puts a FROWN just after the spans/paragraphs that you don’t want to come before.
- now you have a single character to mark which things you don’t want.
- Now that you have a single character which marks all the ones you don’t want, you can use a single-character negative lookbehind, which doesn’t have the problem of being variable width, so negative lookbehind will work:
- FIND =
(?<!☹)<code\s*style="background-color:\s*transparent;"> - this will find just the ones you want, I believe
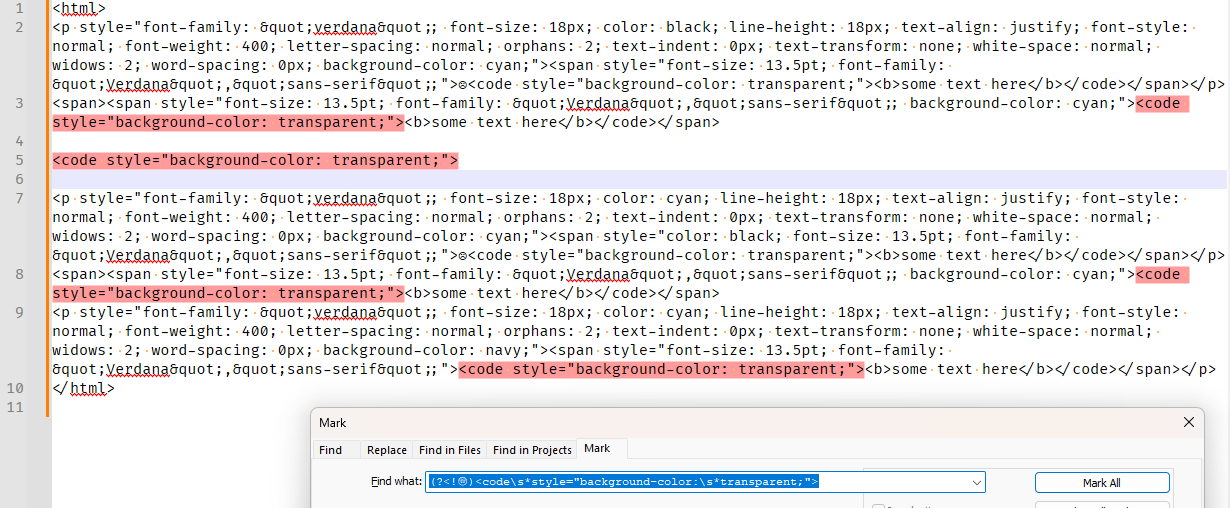
- so now you could use whatever REPLACE you didn’t tell us about.
- FIND =
- After you’ve finished, you can search for the
☹and replace with nothing, to get rid of those temporary markers
Again, I will reiterate: when I come across a search-and-replace that’s too complicated, one of my primary strategies is to break it down into a multi-step
- FIND =
-
Hello, @dr-ramaanand, @peterjones, @mpheath, @mathlete2 and All,
First, in order to simplify the problem, let’s use this theoretical notation to express your regex search, below :
(?<!<span\b[^>]*?color\s*:\s*black[^>]*>\s*)(?<!<p\b[^>]*?color\s*:\s*black[^>]*>\s*<span\b[^>]*>\s*)<code\s*style="background-color:\s*transparent;">( if NOT part A BEFORE part C ) ( if NOT part B BEFORE Part C ) ( FIND part C )But, as @peterjones said, previously :
The look-behinds cannot contain variable quantifiers like
{n,},{n,m},?( idem{0,1}),+( idem{1,}) or*( idem{0,}). So the partsAandBcan only contain possible{n}quantifiers !Moreover, if a look-behind contains an alternative, each part of the alternative must contain the same number of characters, too !
Now , you could say : OK, so I’ll replace all the look-behinds by normal regex parts between alternatives, followed with the
\Ksyntax and get the theoretical notation, below :( ( part A ) | ( Part B ) ) \K ( FIND part C )Which gives the functional regex :
(<span\b[^>]*?color\s*:\s*black[^>]*>\s*|<p\b[^>]*?color\s*:\s*black[^>]*>\s*<span\b[^>]*>\s*)<code\s*style="background-color:\s*transparent;">But indeed, it just finds the opposite matches because :
-
If the part
Amatched, then it will match the partConly -
If The part
Bmatched, then it will match the partConly -
In all other cases, as the parts
AorBnever occur, it will not match the partC, either, as @peterjones rightly explained !
At this point, we can imagine this other regex, which should look, with our notation :
( if ( part A | part B ) followed with part C ) then I do NOT want these TWO cases | In ALL other cases, I want to match the part CThis kind of logic can be reached with the help of the two phrasal verbs
(*SKIP)(*F)( very well-known of you !! ), giving the functional regex :(?:<span\b[^>]*?color\s*:\s*black[^>]*>\s*|<p\b[^>]*?color\s*:\s*black[^>]*>\s*<span\b[^>]*>\s*)<code\s*style="background-color:\s*transparent;">(*SKIP)(*F)|<code\s*style="background-color:\s*transparent;">
If we use the
free-spacingmode, we can add extra information on the method :(?sx-i) # Free-Spacing mode - DOT matches NEW-LINE, Search SENSITIVE to Case (?: # If it gets : <span\b[^>]*?color\s*:\s*black[^>]*>\s* # A match of this FIRST regex part ( Ex-FIRST negative look-behind ) | # OR <p\b[^>]*?color\s*:\s*black[^>]*>\s*<span\b[^>]*>\s* # A match of this SECOND regex part ( Ex-SECOND negative look-beind ) ) # End of the NON-CAPTURING group <code\s*style="background-color:\s*transparent;"> # , FOLLOWED with this MAIN regex part, (*SKIP) (*F) # CANCELS the WHOLE search and CONTINUE for a further possible MATCH | # In ALL other cases ( OR ) <code\s*style="background-color:\s*transparent;"> # Matches the MAIN regex partAgainst your example text, this regex do find the
4occurrences ( out of the6occurrences of the string<code style="background-color: transparent;">)
Below, I indicated, in your example text, the end of the main searched regex, in the two cases which are UNWANTED, by the
•••••mark !<html> <p style="font-family: "verdana"; font-size: 18px; color: black; line-height: 18px; text-align: justify; font-style: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; background-color: cyan;"><span style="font-size: 13.5pt; font-family: "Verdana","sans-serif";"><code style="background-color: transparent;">•••••<b>some text here</b></code></span></p> <span><span style="font-size: 13.5pt; font-family: "Verdana","sans-serif"; background-color: cyan;"><code style="background-color: transparent;"><b>some text here</b></code></span> <code style="background-color: transparent;"> <p style="font-family: "verdana"; font-size: 18px; color: cyan; line-height: 18px; text-align: justify; font-style: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; background-color: cyan;"><span style="color: black; font-size: 13.5pt; font-family: "Verdana","sans-serif";"><code style="background-color: transparent;">•••••<b>some text here</b></code></span></p> <span><span style="font-size: 13.5pt; font-family: "Verdana","sans-serif"; background-color: cyan;"><code style="background-color: transparent;"><b>some text here</b></code></span> <p style="font-family: "verdana"; font-size: 18px; color: cyan; line-height: 18px; text-align: justify; font-style: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; background-color: navy;"><span style="font-size: 13.5pt; font-family: "Verdana","sans-serif";"><code style="background-color: transparent;"><b>some text here</b></code></span></p> </html>
Note that the main regex
<code\s*style="background-color:\s*transparent;">MUST be placed in two places :-
Right BEFORE the part
(*SKIP)(*F)and the last|symbol -
Right AFTER the last
|symbol
Best Regards,
guy038
P.S. :
@dr-ramaanand, for such searches, you could mainly use the general template, below :
( Condition 1 | Condition 2 | ..... | Condition N ) ( MAIN Regex Search ) (*SKIP)(*F) | ( MAIN Regex Search ) | <---------------------------------- That I do NOT want ---------------------------------> <-- That I DO want ---> -
-
@guy038 Yes, your method is perfect. Thanks a lot. Merci beaucoup!
-
@PeterJones You may want to study what is mentioned at https://www.rexegg.com/regex-lookarounds.php to understand how to use your method of regular expression for multiple negative look behinds. This is the specific regular expression I believe can help:
(?<=(?<!(?<!X)_)_)\d+ -
@dr-ramaanand said in Negative lookbehind regular expression not working on Notepad++:
@PeterJones You may want to study what is mentioned at https://www.rexegg.com/regex-lookarounds.php to understand how to use your method of regular expression for multiple negative look behinds
Or, I may not.
As is obvious from this post, I know how to use multiple lookaheads to do the extra logic, and have for years.
But, as I said, “I really don’t like doing super-complicated single-run regular expressions when a multi-step that’s easier to understand would work.” And trying to rework the multiple conditions into multiple negative lookaheads buried before a
\Kto mimic a variable-width lookbehind moves it from the “this is reasonable and practical” world to the world of “why don’t you just do it with a simple three-step process, instead of confusing yourself and making other people write one complicated regex to do a job that’s easy if you break it into pieces”.@guy038 is able to do those super-fancy regex, and appears to enjoy it, so I let him. But I personally see no need for making a single regex that complex, and will not be using it for myself, nor do I think it’s necessarily the right solution for someone who comes here asking for regex help, since it’s not likely to continue to work when they change their parameters slightly. If @guy038 wants to share such solutions, in the hopes that eventually that person being helped will be able to do more for themselves, great; but I just want a practical solution that’s “good enough”.
-
@dr-ramaanand said in Negative lookbehind regular expression not working on Notepad++:
@PeterJones You may want to study what is mentioned at https://www.rexegg.com/regex-lookarounds.php to understand how to use your method of regular expression for multiple negative look behinds. This is the specific regular expression I believe can help:
(?<=(?<!(?<!X)_)_)\d+Please explain why as I am not a believer.
To be more explicit in detail, you have an issue and now you consider nested within nested within nested regular expression is a solution to your problem?
-
@guy038 said in Negative lookbehind regular expression not working on Notepad++:
you could mainly use the general template, below :
@guy038 , that’s an awesome template.
I highly encourage you to write up a short blog post about it, and then link to that new post from the Generic Regex Formula FAQ, because I think that’s a formula that could end up being useful.
(I would just link to your post in here, but the focus is this particular example, which I think would be too complicated for most readers to understand. Doing a simpler example in the blog would be useful, I think, to help people translate your “template” into a real regex.)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login