Help with JSON and Scintilla Lexer
-
@Tyree-Bingham said in Help with JSON and Scintilla Lexer:
could I perhaps attach a shell and send a command that changes Lexer.json.allow.comments to 1?
Interesting idea. However, I think that Lexer.json’s
options.allowCommentsis an internal variable that you cannot access from the outside world. So I don’t think that would be possible from a scripting plugin or external “shell”.The best long-term solution would be to follow the FAQ to see how to issue a feature request. I know that the developer has previously done a language-specific option – the SQL backslash-as-escape option – on the Preferences > Language menu:
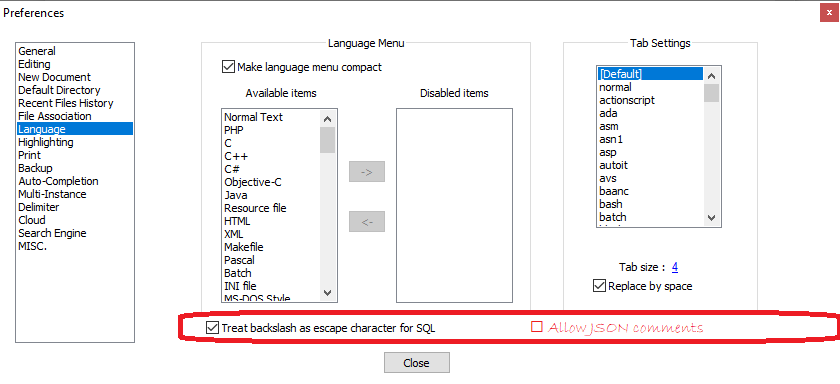
If you wanted to steal that image to embed in your feature request, and say something likeI would like to be able to allow comments in my JSON files; by default, the JSON lexer disables JSON comments, but line 389 of the JSON lexer source code shows there's an option `options.allowComments` in the lexer: } else if (options.allowComments && context.Match("/*")) { context.SetState(SCE_JSON_BLOCKCOMMENT); context.Forward(); } else if (options.allowComments && context.Match("//")) { context.SetState(SCE_JSON_LINECOMMENT); ... and the Style Configurator has the LINECOMMENT and BLOCKCOMMENT styles, but those never take effect because the lexer option is turned off. Would it be possible to add an option in the Notepad++ interface that would toggle that lexer option? Maybe put it in **Preferences > Language**, like for the SQL backslash-as-escape option: Note: I wrote possible text for the issue for you because I think this is a good option to provide to all Notepad++ users. A year ago, I would have actually submitted the issue for you, but I learned recently that the developer pays more attention to issues put in by “normal users” like you, so it would increase your chances if you put in the request yourself. Feel free to rephrase to your own words
I’m just sick of looking at red highlights whenever there are comments in the JSON I open
As a workaround, you can add extra highlighting to a builtin lexer (like the JSON lexer) using regexes via the script
EnhanceAnyBuiltinLexer.pythat @Ekopalypse shares in this linked post. With that, you should be able to look for the comment sequence and set a new highlighting that would override the default error highlighting.-—
PS: I had an idea that I want to experiment with – maybe it is possible to access, since it’s done with scintilla properties, but I’ve got to be away from the keyboard, so it might be a while before I get a chance to experiment. One of the other regulars here might be able to take my “scintilla properties hint” and finish the experiment before I get back. :-)
moderator: fixed link to match modern forum linking
-
@PeterJones said in Help with JSON and Scintilla Lexer:
PS: I had an idea that I want to experiment with – maybe it is possible to access, since it’s done with scintilla properties, but I’ve got to be away from the keyboard, so it might be a while before I get a chance to experiment. One of the other regulars here might be able to take my “scintilla properties hint” and finish the experiment before I get back. :-)
@Tyree-Bingham
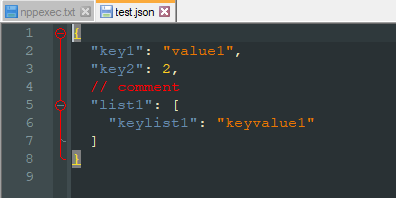
Pick your scripting plugin of choice - mine is NppExec.Testing for JSON properties with an open JSON document:
{ "key1": "value1", "key2": 2, // comment "list1": [ "keylist1": "keyvalue1" ] }which looks like (note I’m using the Obsidian theme so colors may vary, but the comment is red error text):
I can use NppExec and get the following:
================ READY ================ SCI_SENDMSG SCI_PROPERTYNAMES 0 @"" ================ READY ================ echo $(MSG_LPARAM) lexer.json.escape.sequence lexer.json.allow.comments fold.compact fold ================ READY ================So the script to enable comments is (you’ll need to translate from this script to your scripting language preference (e.g., PythonScript, LuaScript, “PerlScript”).
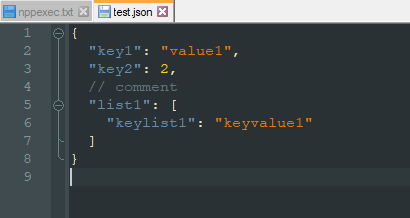
SCI_SENDMSG SCI_SETPROPERTY "lexer.json.allow.comments" "1"Now I see:
Cheers.
-
I mentioned,
scintilla properties
Yes, that worked – and as I was writing it up, @Michael-Vincent replied. :-)
The Scintilla interface has a way to set and get properties. I was able to confirm that you can write that property: in PythonScript (available through Plugins Admin), using
editor.setProperty("lexer.json.allow.comments",1)will accomplish the same thing that Michael’s NppExec script did.If you have a perl interpreter, Win32::Mechanize::NotepadPlusPlus will do the same with
editor->setProperty("lexer.json.allow.comments",1)(though I had to click back in the editor pane to get the screen to refresh after Perl tried to update the property)Does @dinkumoil want to add per-language settings to the ExtSettings plugin?
-
@PeterJones said in Help with JSON and Scintilla Lexer:
though I had to click back in the editor pane to get the screen to refresh
As did I with NppExec, thanks for mentioning that.
Cheers.
-
@PeterJones said in Help with JSON and Scintilla Lexer:
The Scintilla interface has a way to set and get properties.
I got pretty excited about this:
::lex NPP_CONSOLE keep SET LOCAL AFTER = 0 IF "$(ARGC)"<="1" THEN SCI_SENDMSG SCI_PROPERTYNAMES 0 @"" ECHO $(MSG_LPARAM) ELSE IF "$(ARGC)"<="2" THEN SCI_SENDMSG SCI_DESCRIBEPROPERTY "$(ARGV[1])" @"" ECHO $(MSG_LPARAM) SCI_SENDMSG SCI_GETPROPERTYEXPANDED "$(ARGV[1])" @"" ECHO $(ARGV[1]) = $(MSG_LPARAM) ELSE IF "$(ARGC)"<="3" THEN SCI_SENDMSG SCI_SETPROPERTY "$(ARGV[1])" "$(ARGV[2])" ELSE GOTO USAGE ENDIF GOTO END :USAGE ECHO Usage: ECHO \$(ARGV[0]) = current lexer properties ECHO \$(ARGV[0]) [K] = get value of property K ECHO \$(ARGV[0]) [K] [V] = set property K to value V :ENDNow I’ve been running
\lexfrom NppExec console on all filetypes to see what magical properties Scintilla has that I can monkey with :-)Cheers.
-
but don’t be sad if it turns out that very few lexers
propagate their “properties” in this way. :-( -
propagate their “properties” in this way. :-(
Good timing. I just finished a script to explore this:
# encoding=utf-8 """ !!!REQUIRES PythonScript 1.5.4 to avoid getLanguageDesc() bug!!! """ from Npp import * console.show() console.clear() notepad.new() keep = notepad.getLangType() for t in [LANGTYPE.ADA, LANGTYPE.ASM, LANGTYPE.ASN1, LANGTYPE.ASP, LANGTYPE.AU3, LANGTYPE.AVS, LANGTYPE.BAANC, LANGTYPE.BASH, LANGTYPE.BATCH, LANGTYPE.BLITZBASIC, LANGTYPE.C, LANGTYPE.CAML, LANGTYPE.CMAKE, LANGTYPE.COBOL, LANGTYPE.COFFEESCRIPT, LANGTYPE.CPP, LANGTYPE.CS, LANGTYPE.CSOUND, LANGTYPE.CSS, LANGTYPE.D, LANGTYPE.DIFF, LANGTYPE.ERLANG, LANGTYPE.ESCRIPT, LANGTYPE.FLASH, LANGTYPE.FORTH, LANGTYPE.FORTRAN, LANGTYPE.FORTRAN_77, LANGTYPE.FREEBASIC, LANGTYPE.GUI4CLI, LANGTYPE.HASKELL, LANGTYPE.HTML, LANGTYPE.IHEX, LANGTYPE.INI, LANGTYPE.INNO, LANGTYPE.JAVA, LANGTYPE.JAVASCRIPT, LANGTYPE.JS, LANGTYPE.JSON, LANGTYPE.JSP, LANGTYPE.KIX, LANGTYPE.LATEX, LANGTYPE.LISP, LANGTYPE.LUA, LANGTYPE.MAKEFILE, LANGTYPE.MATLAB, LANGTYPE.MMIXAL, LANGTYPE.NIMROD, LANGTYPE.NNCRONTAB, LANGTYPE.NSIS, LANGTYPE.OBJC, LANGTYPE.OSCRIPT, LANGTYPE.PASCAL, LANGTYPE.PERL, LANGTYPE.PHP, LANGTYPE.POWERSHELL, LANGTYPE.PROPS, LANGTYPE.PS, LANGTYPE.PUREBASIC, LANGTYPE.PYTHON, LANGTYPE.R, LANGTYPE.RC, LANGTYPE.REBOL, LANGTYPE.REGISTRY, LANGTYPE.RUBY, LANGTYPE.RUST, LANGTYPE.SCHEME, LANGTYPE.SEARCHRESULT, LANGTYPE.SMALLTALK, LANGTYPE.SPICE, LANGTYPE.SQL, LANGTYPE.SREC, LANGTYPE.SWIFT, LANGTYPE.TCL, LANGTYPE.TEHEX, LANGTYPE.TEX, LANGTYPE.TXT, LANGTYPE.TXT2TAGS, LANGTYPE.USER, LANGTYPE.VB, LANGTYPE.VERILOG, LANGTYPE.VHDL, LANGTYPE.VISUALPROLOG, LANGTYPE.XML, LANGTYPE.YAML]: n = notepad.getLanguageName(t) d = notepad.getLanguageDesc(t) console.write("{!s:<35.35s} {!s:<35.35s} {!s:<35.35s}\n".format(t,n,d)) notepad.setLangType(t) for s in editor.propertyNames().split(): if editor.getPropertyInt(s,-65537) > -65537: v = str(editor.getPropertyInt(s,-65537)) else: v = '"' + editor.getProperty(s) + '"' console.write("\t{:<32.32}:{:01d}: {:<32.32} \"{}\"\n".format("'"+s+"'", editor.propertyType(s), v, editor.describeProperty(s))) notepad.setLangType(keep) notepad.close()-–
Tangential: While I’ve got you here, @Ekopalypse , I manually useddir(LANGTYPE)to get that list, then I changed['ADA', ...]to[LANGTYPE.ADA, ...]. Is there an easier way to do that inside Python, rather than manually making the list of types?
-–Anyway, back to the results: quite a few have properties, but not all:
... JAVASCRIPT JavaScript JavaScript file 'styling.within.preprocessor' :0: "" "For C++ code, determines whether all preprocessor code is styled in the preprocessor style (0, the default) or only from the initial # to the end of the command word(1)." 'lexer.cpp.allow.dollars' :0: "" "Set to 0 to disallow the '$' character in identifiers with the cpp lexer." 'lexer.cpp.track.preprocessor' :0: 0 "Set to 1 to interpret #if/#else/#endif to grey out code that is not active." 'lexer.cpp.update.preprocessor' :0: "" "Set to 1 to update preprocessor definitions when #define found." 'lexer.cpp.verbatim.strings.allo:0: "" "Set to 1 to allow verbatim strings to contain escape sequences." 'lexer.cpp.triplequoted.strings':0: "" "Set to 1 to enable highlighting of triple-quoted strings." 'lexer.cpp.hashquoted.strings' :0: "" "Set to 1 to enable highlighting of hash-quoted strings." 'lexer.cpp.backquoted.strings' :0: 1 "Set to 1 to enable highlighting of back-quoted raw strings ." 'lexer.cpp.escape.sequence' :0: "" "Set to 1 to enable highlighting of escape sequences in strings" 'fold' :0: 1 "" 'fold.cpp.syntax.based' :0: "" "Set this property to 0 to disable syntax based folding." 'fold.comment' :0: 1 "This option enables folding multi-line comments and explicit fold points when using the C++ lexer. Explicit fold points allows adding extra folding by placing a //{ comment at the start and a //} at the end of a section that should fold." 'fold.cpp.comment.multiline' :0: "" "Set this property to 0 to disable folding multi-line comments when fold.comment=1." 'fold.cpp.comment.explicit' :0: "" "Set this property to 0 to disable folding explicit fold points when fold.comment=1." 'fold.cpp.explicit.start' :2: "" "The string to use for explicit fold start points, replacing the standard //{." 'fold.cpp.explicit.end' :2: "" "The string to use for explicit fold end points, replacing the standard //}." 'fold.cpp.explicit.anywhere' :0: "" "Set this property to 1 to enable explicit fold points anywhere, not just in line comments." 'fold.cpp.preprocessor.at.else' :0: "" "This option enables folding on a preprocessor #else or #endif line of an #if statement." 'fold.preprocessor' :0: 1 "This option enables folding preprocessor directives when using the C++ lexer. Includes C#'s explicit #region and #endregion folding directives." 'fold.compact' :0: 0 "" 'fold.at.else' :0: "" "This option enables C++ folding on a "} else {" line of an if statement." JS JavaScript JavaScript file 'styling.within.preprocessor' :0: "" "For C++ code, determines whether all preprocessor code is styled in the preprocessor style (0, the default) or only from the initial # to the end of the command word(1)." 'lexer.cpp.allow.dollars' :0: "" "Set to 0 to disallow the '$' character in identifiers with the cpp lexer." 'lexer.cpp.track.preprocessor' :0: 0 "Set to 1 to interpret #if/#else/#endif to grey out code that is not active." 'lexer.cpp.update.preprocessor' :0: "" "Set to 1 to update preprocessor definitions when #define found." 'lexer.cpp.verbatim.strings.allo:0: "" "Set to 1 to allow verbatim strings to contain escape sequences." 'lexer.cpp.triplequoted.strings':0: "" "Set to 1 to enable highlighting of triple-quoted strings." 'lexer.cpp.hashquoted.strings' :0: "" "Set to 1 to enable highlighting of hash-quoted strings." 'lexer.cpp.backquoted.strings' :0: 1 "Set to 1 to enable highlighting of back-quoted raw strings ." 'lexer.cpp.escape.sequence' :0: "" "Set to 1 to enable highlighting of escape sequences in strings" 'fold' :0: 1 "" 'fold.cpp.syntax.based' :0: "" "Set this property to 0 to disable syntax based folding." 'fold.comment' :0: 1 "This option enables folding multi-line comments and explicit fold points when using the C++ lexer. Explicit fold points allows adding extra folding by placing a //{ comment at the start and a //} at the end of a section that should fold." 'fold.cpp.comment.multiline' :0: "" "Set this property to 0 to disable folding multi-line comments when fold.comment=1." 'fold.cpp.comment.explicit' :0: "" "Set this property to 0 to disable folding explicit fold points when fold.comment=1." 'fold.cpp.explicit.start' :2: "" "The string to use for explicit fold start points, replacing the standard //{." 'fold.cpp.explicit.end' :2: "" "The string to use for explicit fold end points, replacing the standard //}." 'fold.cpp.explicit.anywhere' :0: "" "Set this property to 1 to enable explicit fold points anywhere, not just in line comments." 'fold.cpp.preprocessor.at.else' :0: "" "This option enables folding on a preprocessor #else or #endif line of an #if statement." 'fold.preprocessor' :0: 1 "This option enables folding preprocessor directives when using the C++ lexer. Includes C#'s explicit #region and #endregion folding directives." 'fold.compact' :0: 0 "" 'fold.at.else' :0: "" "This option enables C++ folding on a "} else {" line of an if statement." JSON json JSON file 'lexer.json.escape.sequence' :0: "" "Set to 1 to enable highlighting of escape sequences in strings" 'lexer.json.allow.comments' :0: "" "Set to 1 to enable highlighting of line/block comments in JSON" 'fold.compact' :0: 0 "" 'fold' :0: 1 "" ... PERL Perl Perl source file 'fold' :0: 1 "" 'fold.comment' :0: 1 "" 'fold.compact' :0: 0 "" 'fold.perl.pod' :0: "" "Set to 0 to disable folding Pod blocks when using the Perl lexer." 'fold.perl.package' :0: "" "Set to 0 to disable folding packages when using the Perl lexer." 'fold.perl.comment.explicit' :0: "" "Set to 0 to disable explicit folding." 'fold.perl.at.else' :0: "" "This option enables Perl folding on a "} else {" line of an if statement." ... PYTHON Python Python file 'tab.timmy.whinge.level' :1: "" "For Python code, checks whether indenting is consistent. The default, 0 turns off indentation checking, 1 checks whether each line is potentially inconsistent with the previous line, 2 checks whether any space characters occur before a tab character in the indentation, 3 checks whether any spaces are in the indentation, and 4 checks for any tab characters in the indentation. 1 is a good level to use." 'lexer.python.literals.binary' :0: "" "Set to 0 to not recognise Python 3 binary and octal literals: 0b1011 0o712." 'lexer.python.strings.u' :0: "" "Set to 0 to not recognise Python Unicode literals u"x" as used before Python 3." 'lexer.python.strings.b' :0: "" "Set to 0 to not recognise Python 3 bytes literals b"x"." 'lexer.python.strings.f' :0: "" "Set to 0 to not recognise Python 3.6 f-string literals f"var={var}"." 'lexer.python.strings.over.newli:0: "" "Set to 1 to allow strings to span newline characters." 'lexer.python.keywords2.no.sub.i:0: "" "When enabled, it will not style keywords2 items that are used as a sub-identifier. Example: when set, will not highlight "foo.open" when "open" is a keywords2 item." 'fold' :0: 1 "" 'fold.quotes.python' :0: 1 "This option enables folding multi-line quoted strings when using the Python lexer." 'fold.compact' :0: 0 "" 'lexer.python.unicode.identifier:0: "" "Set to 0 to not recognise Python 3 unicode identifiers." ...(it was too long, so I pared down results
-
oopss - I’m surprised to see that much info.
Boost::python seems to create the classes with names and values attributes,
which itself do return a dict and this can be iterated.
Something likefor t in LANGTYPE.values.values():
should do the job.
The first values creates the dictionary(hash) and the second a list of LANGTYPE enum members. -
By the way, what always works, but is banned by most of the python programmers
is using eval function. So something likeeval('LANGTYPE.{}'.format('ADA'))will return the LANGTYPE.ADA object.
-
@Ekopalypse said in Help with JSON and Scintilla Lexer:
Something like
for t in LANGTYPE.values.values():Yep. Exactly that syntax worked for me. Much cleaner – and now my saved script will still work in future versions with new LANGTYPEs. :-)
Since the first worked, I didn’t bother with the
eval, though that’s a good alternative. Also, for parsing thedir(...)strings, I would have had to eliminate the various helper methods, too, which I don’t have to do with theLANGTYPE.values.values()syntax, so all-in-all, values were better. :-) -
Sorry for hijacking your thread. In the first few responses, we showed a few of the scripting-languages’ methods for changing that setting. If you need more help, let us know which scripting language you chose, and where you’re having trouble.
-
@PeterJones said in Help with JSON and Scintilla Lexer:
Good timing. I just finished a script to explore this:
As the author of “PerlScript” why don’t you post Perl solutions ??? :-)
Pretty quick but roughly Perl equivalent of the PythonScript you posted:
#!perl use strict; use warnings; use Win32::Mechanize::NotepadPlusPlus ':all'; my $keep = notepad->getLangType(); for my $t ( sort ( keys ( %LANGTYPE ) ) ) { my $n = notepad->getLanguageName($LANGTYPE{$t}); my $d = notepad->getLanguageDesc($LANGTYPE{$t}); printf "%-35s %-35s %-35s\n", $t, $n, $d; notepad->setLangType($LANGTYPE{$t}); for my $s ( split "\n", editor->propertyNames() ) { my $v = editor->getProperty($s); printf "\t'%-32s' :%i: %-32s %s\n" , $s, editor->propertyType($s), '"' . $v . '"', editor->describeProperty($s); } print "\n"; } notepad->setLangType($keep); -
P PeterJones referenced this topic on
-
For future readers:
Approximately two years later, someone put in feature request #11713 to request this toggle. (They also put in a separate request #11676 to add all the features of JSON5/JSONC, not just comments.)
update: This request was implemented and released in v8.4.9 in January 2023 (see release notes item 3)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login