How can I change all the words in a given structure?
-
@darkenb said in How can I change all the words in a given structure?:
I don’t quite understand, so I don’t think I can do it. I tried something but it didn’t happen.
Thanks anyway. I think I’ll try to find another way.This is why creating a help area of general problems and their general solutions on this site probably would be a wasted effort.
People don’t want this, they just want the answer to their specific “thing”.
No thinking required.
Plug n play. -
@Alan-Kilborn said in How can I change all the words in a given structure?:
#begin_spoon_feeding
From the linked posting:
SEARCH
(?-i:BSR|(?!\A)\G)(?s:(?!ESR).)*?\K(?-i:FR)
REPLACERRSubstituting in our values for BSR/ESR/FR/RR, that I enumerated above, yields:
SEARCH
(?-i:bs[_|(?!\A)\G)(?s:(?!_bs]).)*?\K(?-i: )
REPLACE_Note: this site has trouble with backslash followed by
[or], so the above still usesbsfor backslash, but when put correctly into Notepad++ it looks like this in the Find what box: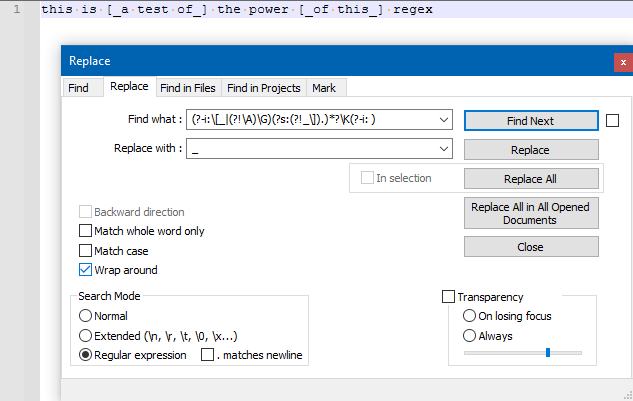
And running a Replace All results in:
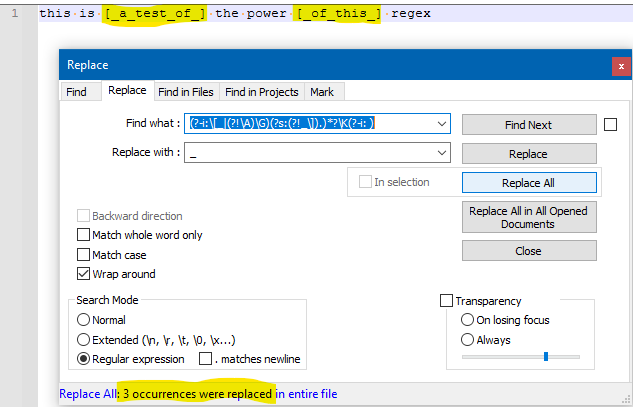
#end_spoon_feeding
EDIT: Well, while I was composing, Peter was also getting out the spoon. Since I went to the trouble of composing, I’ll leave it.
All right, this worked.
I did not understand the complicated part in stage 2, now I have figured it out.
Thanks to everyone who helped.
-
All right, this worked. Now I’ve added _ underscores to texts that I don’t want translated and it worked. Now I will restore the texts that I have added _ underscores, so I have to delete the ones I added. Only underscores in these parentheses will be removed. Any other _ hyphens used in the document will not change.
-
@darkenb said in How can I change all the words in a given structure?:
Only […] underscores in these parentheses will be removed. Any other _ hyphens used in the document will not change.
And now this is a trivial thing to do!
-
@Alan-Kilborn said in How can I change all the words in a given structure?:
@darkenb said in How can I change all the words in a given structure?:
Only […] underscores in these parentheses will be removed. Any other _ hyphens used in the document will not change.
And now this is a trivial thing to do!
I don’t understand why something trivial?
This code block belongs to a game. I added this character “" so that Google Translate wouldn’t detect it and it worked. But it won’t work in the game if I don’t restore it. So I have to remove "” from these characters so that the text remains constant.
-
@darkenb said in How can I change all the words in a given structure?:
I don’t understand why something trivial?
Because you can just reapply the technique used earlier, with different values.
In fact, I think it is just as simple as swapping yourFRandRRvalues. -
Hello, @darkenb, @alan-kilborn, @peterjones, @ekopalypse and All,
I supposed, that, with the Alan’s and Peter’s explanations, you succeeded to achieve what you want !
However, in all that story, there is still something unclear !
@darkenb, I do understand that you don’t want the first line, beginning with a
#character, to be translated byGoogle Translateand that the way you’ve found, to avoid translating, is to add a underscore characters (_) between words ! But, please, could you be a bit more accurate ?Before the replacement process, is your text as like the
B1,B2,B3orB4type ?B1 #. "This is an [ABC DEF GHI JKL] example of text: 0" B2 #. "This is an [ABC DEF GHI JKL ] example of text: 0" B3 #. "This is an [ ABC DEF GHI JKL] example of text: 0" B4 #. "This is an [ ABC DEF GHI JKL ] example of text: 0"After the replacement process, do you expect the text
A1,A2,A3,A4, orA5?A1 #. "This is an [ABC_DEF_GHI_JKL] example of text: 0" A2 #. "This is an [_ABC_DEF_GHI_JKL_] example of text: 0" A3 #. "This is an [_ABC_DEF_GHI_JKL _] example of text: 0" A4 #. "This is an [_ ABC_DEF_GHI_JKL_] example of text: 0" A5 #. "This is an [_ ABC_DEF_GHI_JKL _] example of text: 0"
To my mind, the more logical version is :
-
You, presently, have the
B1configuration -
You would like to get the
A1or, may be, theA2configuration, after the replacement process
Just tell me about it !
As always, once the problem is well defined, the solution is more easy to guess and halfway there ;-))
Best regards,
guy038
-
-
@guy038
Yes, you got it right. A2 is exactly what I want.However, when the process is completed, that is, when I complete the translation, I have to do the opposite of this process.
That’s why I need to remove _ underscores. However, there are _ lines in other words on the page. Therefore, only the underscores in the brackets should be removed in the same way, without changing the sentence. So in summary, I need to apply the following structure.
Before: B1 #. “This is an [ABC DEF GHI JKL] example of text: 0”
After: A2 #. “This is an [ABC_DEF_GHI_JKL] example of text: 0”
More then: B1 #. “This is an [ABC DEF GHI JKL] example of text: 0”
I’ll be glad if you help. I do not understand much, I would appreciate it if you show me practical.
-
A2, the wrong leading signs are erasing for me. It will be B1 first, then A2, then B1 again.
-
@darkenb said in How can I change all the words in a given structure?:
It will be B1 first, then A2, then B1 again.
Which really isn’t anything different than described before.
And which already has a successful solution.I don’t really know what @guy038 would additionally supply.
Probably some over-complicated single-step way(s) to do it, which likely would totally eliminate any possible learning opportunity, for an obvious newbie?I mean, we understand the newbie thing, but is it that hard to follow a recipe?
Maybe someone needs to create a script that would walk one through the process of building up a regex for the “replace only inside delimiters” scenario? OK, I’ll give that a go, and post back here. -
Hello, @darkenb,
OK ! So, you start with text of style
B1B1 #. "This is an [ABC DEF GHI JKL] example of text: 0"But, the case
A#is still not defined, yet. Indeed, you said :After: A2 #. “This is an [ABC_DEF_GHI_JKL] example of text: 0”
but, according to my classification, this should be
A1?
So, sorry to repeat, but are you expecting the style
A1orA2, below ?A1 #. "This is an [ABC_DEF_GHI_JKL] example of text: 0" A2 #. "This is an [_ABC_DEF_GHI_JKL_] example of text: 0"BR
guy038
-
@guy038
My sentence design is B1, but I want to switch to A2 and then B1 again. Although I have written A2 layout, the system puts A1 in order. So it lifts the lines, I don’t understand it. -
@Alan-Kilborn I understand you, but I am seriously a newbie. (? -i: bs (_ | (?! \ A) \ G) (? s: (?! _ bs)).) *? \ K (? - i :) this may be simple for you, but I’m seriously confused. So I couldn’t delete the underscores and replace them with a space character without breaking the sentence. Simply write the codes and let me apply them.
-
@darkenb said in How can I change all the words in a given structure?:
this may be simple for you
Actually, it is NOT simple for me, meaning that I couldn’t retype it from nothing and have a chance at getting it correct. But that’s the benefit of a plug and play recipe.
-
Hi, @darkenb,
OK, I’ve found out all the regexes needed to cover, both, the changes from
B1toA2styles and then, fromA2toB1styles again !Just allow me an hour about to write an informative reply ( for you ! )
BR
guy038
-
Thank you. I’m waiting …
-
@guy038 said in How can I change all the words in a given structure?:
Just allow me an hour about to write an informative reply ( for you ! )
Thank you. I’m waiting …
LOL, all the information was there, a day and a half ago.
What problem is left to be solved? -
Hello, @darkenb, @alan-kilborn, @peterjones, @ekopalypse and All,
@darkenb, before speaking about your problem, I would like to give you some basic information about generic regexes !
Let’s imagine that you want to change a certain class of characters, surrounded double quotes into the same class but surrounded by other symbols
I could have written this generic regex :
SEARCH
"FR"REPLACE SS
$0ESSo,
-
If you have a lot of digits between double quotes, the Find Regex FR is
\d+and that you want to surround them with square brackets, the Start Separator SS is[symbol and the End Separator ES is the]symbol So, you would use the regex S/R below :-
SEARCH
"\d+" -
REPLACE
[$0]
-
-
Now, if you have a lot of uppercase letters between double quotes, the Find Regex FR is
[A-Z]+and you want to surround them with braces, themselves surrounded with the--string, the Start Separator SS is--{symbol and the End Separator ES is the}--symbol and you would use the regex S/R below :-
SEARCH
"[A-Z]+" -
REPLACE
--{$0}--
-
-
Finally, if you have a lot of word letters between double quotes, the Find Regex FR is
\w+and you want to surround them with one space char, themselves surrounded with the simple quotes, the Start Separator SS is'\x20symbol and the End Separator ES is the\x20'symbol and you would use the regex S/R below :-
SEARCH
"\w+" -
REPLACE
'\x20$0\x20'
-
Note that the
$0syntax, in replacement, represents the complete search match and\x20represents a single space charSo, you can see, that whatever the real example chosen, this generic regex remains exact and means :
After the replacement, any range of characters between double quotes will be changed as the same range, preceded with the SS separator and followed with the ES separator
Of course, this example is very basic and should be wrong in some particular cases but just gives you a general idea ! The goal is to replace the generic names, as FR, SS and ES with their true regex values, regarding your own needs and what you want to achieve ;-))
Let’s go back to your problem ! For all the regexes, provided below, the process is :
-
Open or switch to your file, in N++
-
Open the
Replacedialog (Ctrl + H)-
Fill up the
Find what:andReplace with:zones with the appropriate regexes -
Un-tick all box options, first
-
Tick the
Wrap aroundoption ( IMPORTANT : this ensures that current file is scanned from its very beginning to its very end, whatever the current position of the caret ) -
Select the
Regular expressionsearch mode -
Click on the Replace All button ( Do not use the
Replacebutton, due to the possible\Ksyntax in regexes )
-
-
In addition note that the square brackets are special regex characters with a special meaning and need to be escaped when you want to search them as literals. However, unfortunately, this escape syntax is not properly displayed, on our
NodeBBforum. So I’m going to use the usual\x##syntax, where##represents the hexadecimal code of a character. So, in regexes, I will refer of the[as the\x5bchar and of the]as the\x5dchar !
First, I will provide the method and the different regexes needed. Secondly, I’ll give you some explanations on them. However, I strongly advice you to learn basic regex documentation from here ;-))
-
A) This first regex S/R will add an underscore right after any[character and right before any]character-
SEARCH
(\x5b)|\x5d -
REPLACE
?1\x5b_:_\x5d
-
-
B) Then, this second regex S/R will change any space char, within square brackets only, with an underscore char :-
SEARCH
(?-s)(?:\x5b_|(?!\A)\G)(?:(?!_\x5d).)*?\K\x20 -
REPLACE
_
-
-
Now, just translate all your text with
Google Translate
... ... .... ... ... .... ... ... ....-
C) Once this translation task over, this third regex S/R will remove the underscore char located after the[character and before the]character-
SEARCH
(\x5b)_|_\x5d -
REPLACE
?1\x5b:\x5d
-
-
DFinally, this fourth regex S/R, below, will change back any underscore character , within square brackets only, with an space char :-
SEARCH
(?-s)(?:\x5b|(?!\A)\G)(?:(?!\x5d).)*?\K_ -
REPLACE
\x20
-
Et voilà !
Notes :
-
Regarding the S/R
AandC:-
The search part is rather obvious and searches two different expressions, separated with the alternation symbol
| -
Note that the
\x5bcharacter is surrounded with parentheses and so, defines a group1which is re-used in replacement -
The replacement has the syntax
?1(True:False)which means :-
If group
1exists ( so when the first alternative\x5boccurs ) rewrite the True part -
If group
1does not exist ( so, when the second alternative\x5doccurs ) rewrite the False part
-
-
-
Regarding the S/R
BandD:-
They are, both, built up from the generic S/R regex :
-
SEARCH
(?s-i:BSR|(?!\A)\G)(?s-i:(?!ESR).)*?\K(?s-i:FR) -
REPLACE RR
-
-
Note that the different syntaxes
(?s-i:•••••)are non-capturing groups ( i.e. groups which do not store the contents between parentheses ), which contain the leading modifierssandi-
The
smodifier means that the dot regex char (.) represents any char, even EOL characters -
The
-imodifier means that the search is sensible to case of letters characters
-
-
However, as we do not search any letter and as I suppose that your different zones
[•••••••]stand all in a single line, this generic regex can be simplified as below, with a leading-smodifier, meaning that a.will match a single standard character, only-
SEARCH
(?-s)(?:BSR|(?!\A)\G)(?:(?!ESR).)*?\KFR -
REPLACE RR
-
-
Globally, the generic S/R, above will change any search expression, found with the FR regex, with the replacement expression, expressed with the RR syntax, between the BSR and ESR excluded locations, only !
-
So, for the regex S/R
B:-
BSR, Beginning Search-region Regex, is the regex
\x5b_ -
ESR, Ending Search-region Regex, is the regex
_\x5d -
FR, Find Regex, is the regex
\x20 -
RR, Replacement Regex is the regex
_
-
-
And, if we change the names of generic regex with the real regex values, we exactly get the search regex
(?-s)(?:\x5b_|(?!\A)\G)(?:(?!_\x5d).)*?\K\x20and the replacement regex_ -
Now, regarding the regex S/R
D, note that we already remove the underscores close to the square brackets, with the regex S/RC. So, this time :-
BSR, Beginning Search-region Regex, is the regex
\x5b -
ESR, Ending Search-region Regex, is the regex
\x5d -
FR, Find Regex, is the regex
_ -
RR, Replacement Regex is the regex
\x20
-
-
And, again, if we change the names of generic regex with the real regex values, we exactly get the search regex
(?-s)(?:\x5b|(?!\A)\G)(?:(?!\x5d).)*?\K_and the replacement regex\x20!
-
Best Regards,
guy038
-
-
@guy038
I swear you are the king. : D Thanks to you, my job has been solved, and I can do it myself to a certain extent when something happens.Thank you very, very much…
-
Hello, @darkenb, @alan-kilborn, @peterjones, @ekopalypse and All,
@darkenb :
- Regarding the
BandDregex S/R, note that I didn’t explain fully how they work. I do think that you need to learn basic regex concepts first, before trying to understand these complicated syntaxes which would just confuse you ;-)
To All,
-
Regarding the
AandCregex S/R, they can be simplified and we do not need to use conditional regexes ! Indeed :-
Regex S/R
A:-
SEARCH
(\x5b)|(\x5d) -
REPLACE
\1_\2
-
-
Regex S/R
C:-
SEARCH
(\x5b)_|_(\x5d) -
REPLACE
\1\2
-
-
-
As you can see, the opening square bracket
\x5bis stored as group1and the ending square bracket\x5dis stored as group2. And, as the two alternatives are mutually exclusive, we can write, both,\1and\2in the replacement zone ( or$1and$2). We know that when one is defined, the other one is undefined and equivalent to an empty string ;-))
Best Regards,
guy038
- Regarding the
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login